Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Modèle d’approvisionnement d’événement
Intention
Dans les architectures pilotées par les événements, le modèle d’approvisionnement d’événement stocke les événements qui entraînent un changement d’état dans un magasin de données. Cela permet de saisir et de conserver un historique complet des changements d’état, et de promouvoir l’auditabilité, la traçabilité et la capacité d’analyser les états passés.
Motivation
Plusieurs microservices peuvent collaborer pour traiter les demandes, et ils communiquent par le biais d’événements. Ces événements peuvent entraîner un changement d’état (données). Le stockage des objets d’événements dans l’ordre dans lequel ils apparaissent fournit des informations précieuses sur l’état actuel de l’entité de données et des informations supplémentaires sur la façon dont elle est arrivée à cet état.
Applicabilité
Utilisez le modèle d’approvisionnement d’événement lorsque :
-
Un historique immuable des événements qui se produisent dans une application est nécessaire pour le suivi.
-
Les projections de données polyglottes sont requises à partir d’une source unique de vérité (SSOT).
-
Une reconstruction ponctuelle de l’état de l’application est nécessaire.
-
Le stockage à long terme de l’état de l’application n’est pas nécessaire, mais que vous souhaitez peut-être le reconstruire selon vos besoins.
-
Les charges de travail ont des volumes de lecture et d’écriture différents. Par exemple, vous avez des charges de travail intensives en écriture qui ne nécessitent pas de traitement en temps réel.
-
La capture des données de modification (CDC) est nécessaire pour analyser les performances de l’application et d’autres métriques.
-
Les données d’audit sont requises pour tous les événements survenant dans un système à des fins de génération de rapports et de conformité.
-
Vous souhaitez obtenir des scénarios hypothétiques en modifiant (insertion, mise à jour ou suppression) des événements au cours du processus de rediffusion afin de déterminer l’état final possible.
Problèmes et considérations
-
Contrôle de simultanéité optimiste : ce modèle stocke tous les événements qui entraînent un changement d’état dans le système. Plusieurs utilisateurs ou services peuvent essayer de mettre à jour les mêmes données en même temps, ce qui peut provoquer des collisions d’événements. Ces collisions se produisent lorsque des événements contradictoires sont créés et appliqués en même temps, ce qui se traduit par un état final des données qui ne correspond pas à la réalité. Pour résoudre ce problème, vous pouvez mettre en œuvre des stratégies pour détecter et résoudre les collisions d’événements. Par exemple, vous pouvez implémenter un schéma de contrôle de simultanéité optimiste en incluant la gestion des versions ou en ajoutant des horodatages aux événements pour suivre l’ordre des mises à jour.
-
Complexité : la mise en œuvre de l’approvisionnement d’événement nécessite un changement d’état d’esprit, passant des opérations CRUD traditionnelles à une réflexion axée sur les événements. Le processus de rediffusion, qui est utilisé pour restaurer le système dans son état d’origine, peut être complexe afin de garantir l’idempotence des données. Le stockage d’événements, les sauvegardes et les instantanés peuvent également ajouter de la complexité.
-
Cohérence à terme : les projections de données dérivées des événements sont cohérentes à terme en raison de la latence dans la mise à jour des données en utilisant le modèle de séparation des responsabilités des requêtes de commande (CQRS) ou des vues matérialisées. Lorsque les consommateurs traitent les données d’un magasin d’événements et que les diffuseurs de publication envoient de nouvelles données, la projection des données ou l’objet de l’application peuvent ne pas représenter l’état actuel.
-
Interrogation : la récupération des données actuelles ou agrégées à partir des journaux d’événements peut être plus complexe et plus lente que celle des bases de données traditionnelles, en particulier pour les requêtes complexes et les tâches de génération de rapports. Pour atténuer ce problème, l’approvisionnement d’événement est souvent mis en œuvre selon le modèle CQRS.
-
Taille et coût du magasin d’événements : le magasin d’événements peut connaître une croissance exponentielle en raison de la persistance des événements, en particulier dans les systèmes présentant un débit d’événements élevé ou des périodes de rétention prolongées. Par conséquent, vous devez régulièrement archiver les données des événements pour les stocker de manière rentable afin d’éviter que le magasin d’événements ne devienne trop volumineux.
-
Capacité de mise à l’échelle du magasin d’événements : le magasin d’événements doit gérer efficacement de gros volumes d’opérations d’écriture et de lecture. La mise à l’échelle d’un magasin d’événements peut s’avérer difficile. Il est donc important de disposer d’un magasin de données qui fournit des partitions.
-
Efficacité et optimisation : choisissez ou concevez un magasin d’événements qui gère efficacement les opérations d’écriture et de lecture. Le magasin d’événements doit être optimisé en fonction du volume d’événements attendu et des modèles de requêtes pour l’application. La mise en œuvre de mécanismes d’indexation et de requête peut accélérer la récupération des événements lors de la reconstruction de l’état de l’application. Vous pouvez également envisager d’utiliser des bases de données ou des bibliothèques de magasins d’événements spécialisées qui offrent des fonctionnalités d’optimisation des requêtes.
-
Instantanés : vous devez sauvegarder les journaux d’événements à intervalles réguliers avec une activation basée sur le temps. La répétition des événements survenus lors de la dernière sauvegarde réussie connue des données devrait permettre de point-in-time rétablir l'état de l'application. L’objectif de point de reprise (RPO) est le délai maximal acceptable depuis le dernier point de reprise des données. Le RPO détermine ce qui est considéré comme une perte de données acceptable entre le dernier point de reprise et l’interruption du service. La fréquence des instantanés quotidiens du magasin de données et d’événements doit être basée sur le RPO de l’application.
-
Sensibilité temporelle : les événements sont stockés dans l’ordre dans lequel ils se produisent. Par conséquent, la fiabilité du réseau est un facteur important à prendre en compte lorsque vous implémentez ce modèle. Les problèmes de latence peuvent entraîner un état incorrect du système. Utilisez les files d'attente « premier entré, premier sorti » (FIFO) avec at-most-once livraison pour acheminer les événements vers le magasin de l'événement.
-
Performances de rediffusion d’événements : la répétition d’un grand nombre d’événements pour reconstituer l’état actuel de l’application peut prendre beaucoup de temps. Des efforts d’optimisation sont nécessaires pour améliorer les performances, en particulier lors de la rediffusion d’événements à partir de données archivées.
-
Mises à jour externes du système : les applications qui utilisent le modèle d’approvisionnement d’événement peuvent mettre à jour les magasins de données dans des systèmes externes et peuvent capturer ces mises à jour sous forme d’objets d’événements. Lors des rediffusions d’événements, cela peut devenir un problème si le système externe ne s’attend pas à une mise à jour. Dans de tels cas, vous pouvez utiliser des indicateurs de fonctionnalité pour contrôler les mises à jour externes du système.
-
Requêtes système externes : lorsque les appels système externes sont sensibles à la date et à l’heure de l’appel, les données reçues peuvent être stockées dans des magasins de données internes pour être utilisées lors des rediffusions.
-
Gestion des versions des événements : au fur et à mesure que l’application évolue, la structure des événements (schéma) peut changer. La mise en œuvre d’une stratégie de gestion des versions pour les événements afin de garantir la rétrocompatibilité et la compatibilité descendante est nécessaire. Cela peut impliquer l’inclusion d’un champ de version dans la charge utile de l’événement et la gestion des différentes versions de l’événement de manière appropriée pendant la rediffusion.
Mise en œuvre
Architecture de haut niveau
Commandes et événements
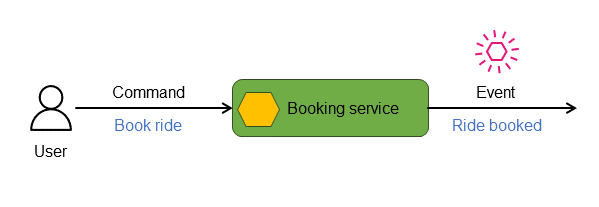
Dans les applications de microservices distribuées pilotées par des événements, les commandes représentent les instructions ou les demandes envoyées à un service, généralement dans le but de modifier son état. Le service traite ces commandes et évalue leur validité et leur applicabilité à son état actuel. Si la commande s’exécute correctement, le service répond en émettant un événement indiquant l’action entreprise et les informations d’état pertinentes. Par exemple, dans le schéma suivant, le service de réservation répond à la commande Réserver un trajet en émettant l’événement Trajet réservé.
Magasins d’événements
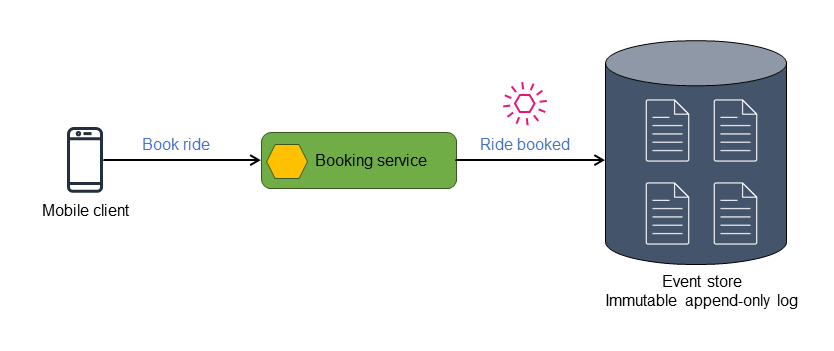
Les événements sont journalisés dans un référentiel ou un magasin de données immuable, avec ajout uniquement et ordonné chronologiquement, appelé magasin d’événements. Chaque changement d’état est traité comme un objet d’événement individuel. Un objet entité ou un magasin de données dont l'état initial est connu, son état actuel et n'importe quelle point-in-time vue peuvent être reconstruits en rejouant les événements dans l'ordre de leur apparition.
Le magasin d’événements sert de registre historique de toutes les actions et de tous les changements d’état, et constitue une source unique et précieuse de vérité. Vous pouvez utiliser le magasin d'événements pour déterminer l' up-to-dateétat final du système en transmettant les événements à un processeur de rediffusion, qui applique ces événements pour produire une représentation précise de l'état le plus récent du système. Vous pouvez également utiliser le magasin d'événements pour générer la point-in-time perspective de l'état en rejouant les événements via un processeur de rediffusion. Dans le modèle d’approvisionnement d’événement, l’état actuel peut ne pas être entièrement représenté par l’objet d’événement le plus récent. Vous pouvez obtenir l’état actuel de l’une des trois façons suivantes :
-
En agrégeant les événements associés. Les objets d’événements associés sont combinés pour générer l’état actuel pour les requêtes. Cette approche est souvent utilisée conjointement avec le modèle CQRS, dans lequel les événements sont combinés et écrits dans le magasin de données en lecture seule.
-
En utilisant les vues matérialisées. Vous pouvez utiliser l’approvisionnement d’événement avec le modèle de vue matérialisée pour calculer ou résumer les données d’événements et obtenir l’état actuel des données associées.
-
En rejouant les événements. Les objets d’événement peuvent être rejoués pour effectuer des actions permettant de générer l’état actuel.
Le schéma suivant montre l’événement Ride booked stocké dans un magasin d’événements.
Le magasin d’événements publie les événements qu’il stocke, et les événements peuvent être filtrés et acheminés vers le processeur approprié pour les actions suivantes. Par exemple, les événements peuvent être acheminés vers un processeur de vues qui résume l’état et affiche une vue matérialisée. Les événements sont transformés au format de données du magasin de données cible. Cette architecture peut être étendue pour dériver différents types de magasins de données, ce qui entraîne une persistance polyglotte des données.
Le schéma suivant décrit les événements d’une application de réservation de trajets. Tous les événements qui se produisent dans l’application sont stockés dans le magasin d’événements. Les événements stockés sont ensuite filtrés et acheminés vers différents utilisateurs.
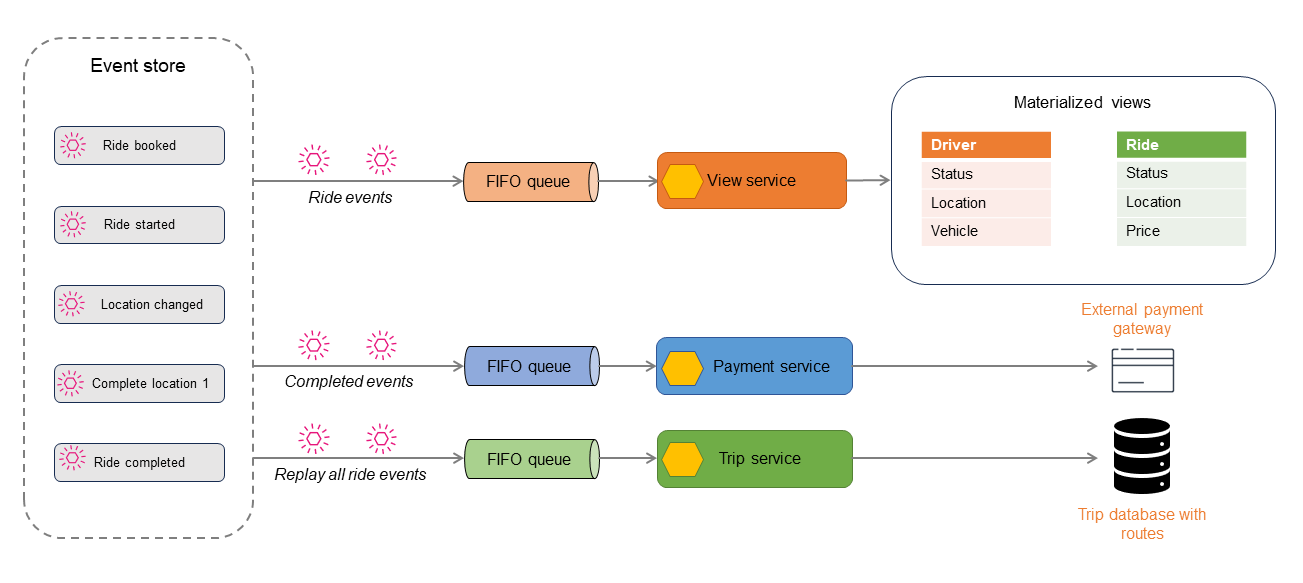
Les événements de trajet peuvent être utilisés pour générer des magasins de données en lecture seule à l’aide du modèle CQRS ou du modèle de vue matérialisée. Vous pouvez obtenir l’état actuel du trajet, du chauffeur ou de la réservation en interrogeant les magasins de lecture. Certains événements, tels que Location changed ou Ride completed, sont communiqués à un autre utilisateur pour le traitement des paiements. Une fois le trajet terminé, tous les événements du trajet sont rejoués pour créer un historique du trajet à des fins d’audit ou de génération de rapports.
Le modèle d'approvisionnement en événements est fréquemment utilisé dans les applications nécessitant une point-in-time restauration, ainsi que lorsque les données doivent être projetées dans différents formats à l'aide d'une source fiable unique. Ces deux opérations nécessitent un processus de rediffusion pour exécuter les événements et obtenir l’état final requis. Le processeur de rediffusion peut également avoir besoin d’un point de départ connu, idéalement pas dès le lancement de l’application, car ce ne serait pas un processus efficace. Nous vous recommandons de prendre régulièrement des instantanés de l'état du système et d'appliquer un plus petit nombre d'événements pour obtenir un up-to-date état.
Mise en œuvre à l’aide des services AWS
Dans l’architecture suivante, Amazon Kinesis Data Streams est utilisé comme magasin d’événements. Ce service capture et gère les modifications des applications sous forme d’événements, et offre une solution de diffusion de flux de données à haut débit et en temps réel. Pour implémenter le modèle d'approvisionnement en événements sur AWS, vous pouvez également utiliser des services tels qu'Amazon EventBridge et Amazon Managed Streaming for Apache Kafka (Amazon MSK) en fonction des besoins de votre application.
Pour améliorer la durabilité et activer l’audit, vous pouvez archiver les événements capturés par Kinesis Data Streams dans Amazon Simple Storage Service (Amazon S3). Cette méthode à double stockage permet de retenir les données historiques des événements en toute sécurité pour les analyses futures et à des fins de conformité.
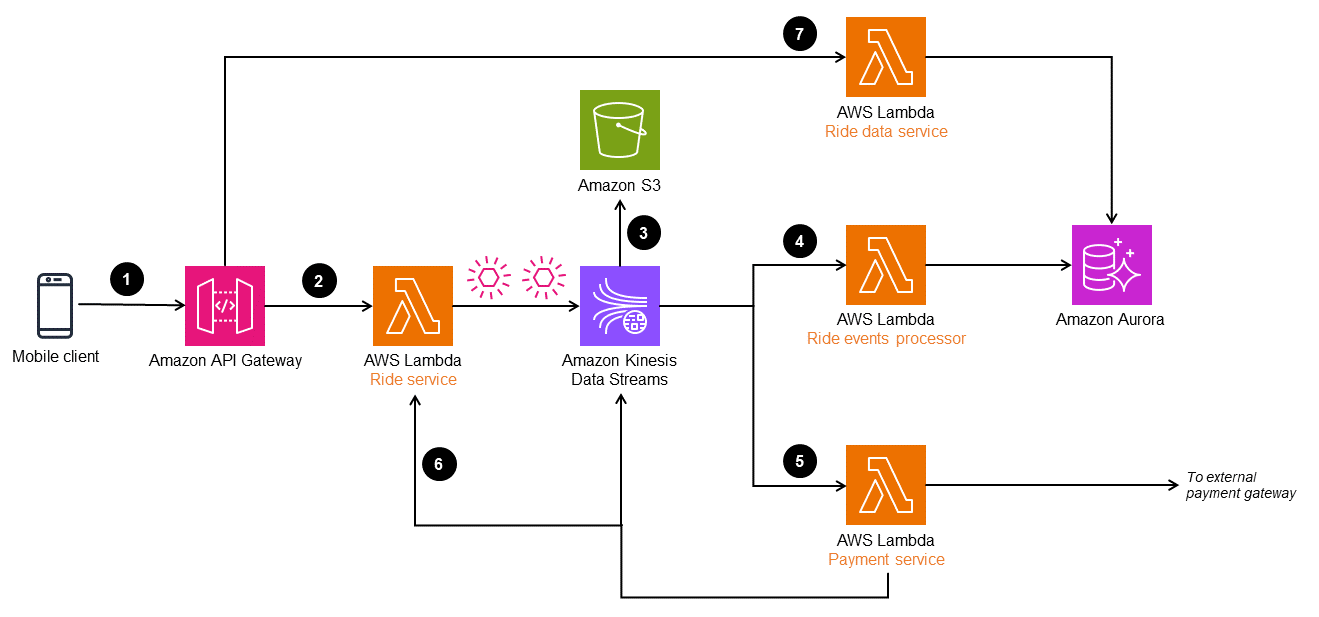
Le flux de travail se compose des étapes suivantes :
-
Une demande de réservation de trajet est envoyée via un client mobile à un point de terminaison Amazon API Gateway.
-
Le microservice de trajet (fonction Lambda
Ride service) reçoit la demande, transforme les objets et publie sur Kinesis Data Streams. -
Les données d’événements contenues dans Kinesis Data Streams sont stockées dans Amazon S3 à des fins de conformité et d’historique des audits.
-
Les événements sont transformés et traités par la fonction Lambda
Ride event processoret stockés dans une base de données Amazon Aurora afin de fournir une vue matérialisée des données de trajet. -
Les événements de trajet terminés sont filtrés et envoyés pour traitement du paiement à une passerelle de paiement externe. Lorsque le paiement est effectué, un autre événement est envoyé à Kinesis Data Streams pour mettre à jour la base de données de trajets.
-
Une fois le trajet terminé, les événements de trajet sont rejoués dans la fonction Lambda
Ride servicepour créer des itinéraires et l’historique du trajet. -
Les informations sur les trajets peuvent être lues via le
Ride data service, qui se lit dans la base de données Aurora.
API Gateway peut également envoyer l’objet d’événement directement à Kinesis Data Streams sans la fonction Lambda Ride service. Toutefois, dans un système complexe tel qu’un service de transport, l’objet de l’événement peut avoir besoin d’être traité et enrichi avant d’être ingéré dans le flux de données. C’est pourquoi l’architecture dispose d’un Ride service qui traite l’événement avant de l’envoyer à Kinesis Data Streams.
Références du blog
