Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Catalogue centralisé
Le schéma suivant montre comment le catalogue centralisé connecte les producteurs de données et les consommateurs de données dans le lac de données.
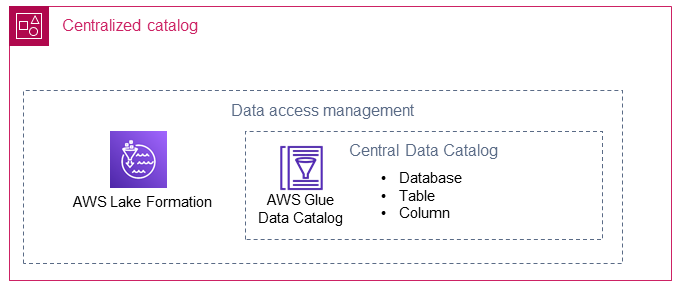
Le catalogue centralisé stocke et gère le catalogue de données partagé pour les comptes des producteurs de données. Le catalogue centralisé héberge également les métadonnées techniques des données partagées (par exemple, le nom de la table et le schéma) et constitue l'endroit où les consommateurs de données accèdent aux données.
Les consommateurs de données peuvent accéder aux données de plusieurs producteurs de données dans le catalogue centralisé et peuvent ensuite mélanger ces données avec leurs propres données pour un traitement ultérieur. L'utilisation d'un catalogue centralisé évite aux consommateurs de données de se connecter directement aux différents producteurs de données et réduit les frais d'exploitation.
Étant donné que le catalogue centralisé offre une visibilité sur le partage et la consommation de données par les producteurs et les consommateurs de données, il peut s'agir d'un emplacement idéal pour appliquer vos fonctions de gouvernance des données centralisées (par exemple, l'audit des accès).
Les sections suivantes décrivent comment le catalogue centralisé utilise AWS Lake Formation et AWS Glue.
AWS Lake Formation
AWS Lake Formationpermet de créer des bases de AWS Glue données dans un catalogue de données qui indiquent les emplacements de plusieurs producteurs de données dans votre lac de données. Un rôle AWS Identity and Access Management (IAM) est créé pour Lake Formation dans le catalogue centralisé. En utilisant Lake Formation, le catalogue centralisé peut partager de manière sélective des ressources de données (par exemple, une base de données, des tables ou des colonnes) avec les consommateurs de données. Les ressources gérées de Lake Formation sont partagées avec les consommateurs de données en utilisant l'une des deux méthodes suivantes :
-
Méthode de ressource nommée — Cette méthode partage les ressources gérées entre les comptes. Les noms de bases de données, de tables ou de colonnes doivent être spécifiés et une ressource peut être partagée avec une organisation, une unité organisationnelle (UO) ou Compte AWS. Pour réduire les frais de partage et de gestion, nous vous recommandons de partager les ressources à des niveaux supérieurs dans la mesure du possible (par exemple, au sein d'une organisation ou d'une unité d'organisation plutôt que d'une Compte AWS). Cependant, vous devez vous assurer que cette approche répond aux exigences de contrôle de sécurité des données de votre organisation.
-
Remarque : Cette méthode fonctionne bien pour les consommateurs de données utilisant un type d'application, où les AWS services consomment les données du producteur de données. Les exigences d'accès aux données de ce type de consommateur de données sont dictées par les applications, prescriptives et relativement statiques.
-
-
Méthode de contrôle d'accès basée sur les balises Lake Formation (LF-TBAC) — La LF-TBAC est particulièrement utile pour les consommateurs de données utilisant un type de service de données. Cependant, les ressources étiquetées Lake Formation ne peuvent actuellement être partagées qu'au Compte AWS niveau de l'organisation ou de l'unité organisationnelle.
AWS Glue
Vous devez créer des bases de données AWS Glue pour chaque producteur de données de votre catalogue centralisé. Comme le catalogue centralisé héberge les bases de données de tous les producteurs de données, vous devez vous assurer que le nom de la base de données est unique pour tous les producteurs de données et qu'il reflète le producteur de données et son type de données. AWS Glue Par exemple, vous pouvez utiliser la structure de dénomination de base de données suivante : <Data_Producer>–<Environment>–<Data_Group>
-
<Data_Producer>— Le nom du producteur de données. -
<Environment>— L'environnement du lac de données, tel qu'devun environnement de développement,situn environnement de test d'intégration de systèmes ouprodun environnement de production. -
<Data_Group>— Le nom du groupe de données utilisé pour séparer les données d'un producteur de données en groupes logiques. Vous pouvez utiliser le nom, l'ID ou l'abréviation du système source comme nom. Une description de base de données permet également de décrire le contenu et l'objectif de la base de données.
Vous pouvez utiliser un AWS Glue robot d'exploration sur les données du producteur de données pour conserver leur schéma dans la base de données du catalogue centralisé. Si des données sont régulièrement créées à la même fréquence par un producteur de données, vous pouvez utiliser un seul AWS Glue crawler. Dans tous les autres cas, vous devez utiliser plusieurs AWS Glue robots d'exploration pour s'adapter aux différentes fréquences d'exploration. Selon le cas d'utilisation de votre entreprise, le robot d'exploration peut être planifié selon une fréquence prédéfinie ou déclenché par des événements.
Vous pouvez également gérer le schéma de table en AWS Glue appelant l' AWS Glue API pour créer ou mettre à jour le schéma. Bien que cela puisse apporter de la flexibilité, des efforts supplémentaires sont nécessaires pour le développement et la maintenance du code. Assurez-vous d'évaluer le cas d'utilisation et la valeur commerciale, puis de choisir l'option qui répond à vos besoins et qui entraîne le moins de frais généraux.
