Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture de référence
Le schéma suivant montre l'architecture de référence de ce guide pour la croissance et la mise à l'échelle d'un lac de données sur le AWS Cloud.
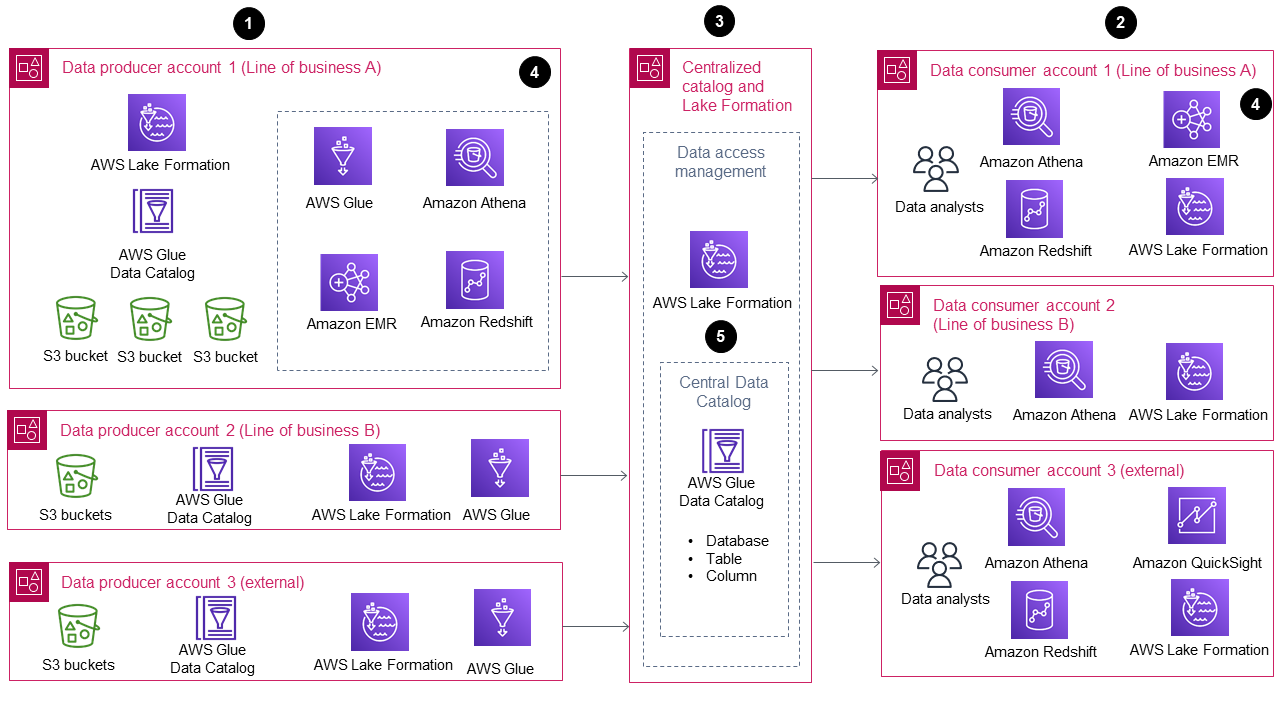
Le schéma montre les composants suivants :
-
Une couche productrice de données est différente Comptes AWS.
-
Une couche de consommation de données différente Comptes AWS.
-
Un catalogue centralisé dans un Compte AWS.
-
Bien que chaque secteur d'activité ne compte qu'un seul producteur et un seul consommateur de données, l'architecture de référence du guide prend en charge plusieurs producteurs et consommateurs de données pour chaque secteur d'activité. Il est courant d'associer un seul producteur de données à un ou plusieurs consommateurs de données, qui incluent à la fois des types d'applications et des serveurs de données. Pour plus d'informations à ce sujet, consultez la Composants de l'architecture de référence section de ce guide.
-
Le catalogue centralisé est l'interface utilisée par les producteurs et les consommateurs de données pour partager et consommer des données.
L'approche de l'architecture de référence permet de standardiser le partage et la consommation de données, et de dimensionner indépendamment les producteurs et les consommateurs de données sans augmenter vos frais de gestion. L'architecture de référence permet également la production et la distribution de données entre différents producteurs de données. Tout producteur de données peut faire partie du lac de données, partager ses données et contribuer à la valeur globale fournie par le lac de données.
Cette approche permet à votre organisation de récolter de la valeur des données dans tous vos secteurs d'activité et auprès des propriétaires de données externes, sans créer de goulot d'étranglement en limitant la collecte et le traitement des données dans un pipeline unique.
