Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mode Écrire dans votre région (primaire mixte)
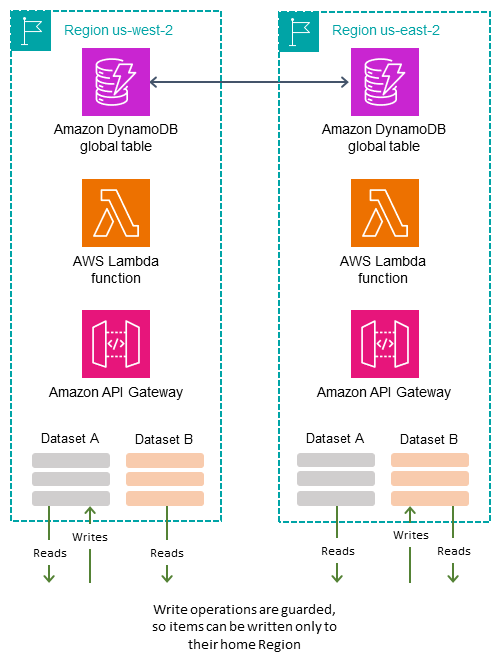
Le mode d'écriture dans votre région attribue différents sous-ensembles de données aux différentes régions d'origine et autorise les opérations d'écriture sur un élément uniquement via sa région d'origine. Ce mode est actif-passif mais assigne la région active en fonction de l'élément. Chaque région est principale pour son propre jeu de données qui ne se chevauche pas, et les opérations d'écriture doivent être protégées pour garantir une localisation appropriée.
Ce mode est similaire à l'écriture dans une région, sauf qu'il permet des opérations d'écriture à faible latence, car les données associées à chaque utilisateur peuvent être placées plus près du réseau de cet utilisateur. Cela répartit également l'infrastructure environnante de manière plus uniforme entre les régions et nécessite moins de travail pour construire l'infrastructure en cas de basculement, car toutes les régions ont déjà une partie de leur infrastructure active.
Vous pouvez déterminer la région d'origine des objets de plusieurs manières :
-
Intrinsèque : certains aspects des données, tels qu'un attribut spécial ou une valeur incorporée dans leur clé de partition, indiquent clairement leur région d'origine. Cette technique est décrite dans le billet de blog Utiliser l'épinglage régional pour définir une région d'origine pour les éléments d'une table globale Amazon DynamoDB
. -
Négocié : La région d'origine de chaque ensemble de données est négociée d'une manière externe, par exemple avec un service mondial distinct qui gère les assignations. La mission peut avoir une durée limitée, après laquelle elle est sujette à renégociation.
-
Orienté vers les tables : au lieu de créer une seule table globale de réplication, vous créez le même nombre de tables globales que les régions de réplication. Le nom de chaque table indique sa région d'origine. Dans les opérations standard, toutes les données sont écrites dans la région d'origine tandis que les autres régions conservent une copie en lecture seule. Lors d'un basculement, une autre région adopte temporairement des tâches d'écriture pour cette table.
Par exemple, imaginez que vous travaillez pour une société de jeux vidéo. Vous avez besoin d'opérations de lecture et d'écriture à faible latence pour tous les joueurs du monde entier. Vous assignez chaque joueur à la région la plus proche de lui. Cette région prend en charge toutes ses opérations de lecture et d'écriture, garantissant ainsi une forte read-after-write cohérence. Toutefois, lorsqu'un joueur voyage ou si sa région d'origine est en panne, une copie complète de ses données est disponible dans les autres régions, et le joueur peut être affecté à une autre région d'origine.
Autre exemple, imaginez que vous travaillez dans une entreprise de visioconférence. Les métadonnées de chaque conférence téléphonique sont attribuées à une région particulière. Les appelants peuvent utiliser la région la plus proche de chez eux pour une latence minimale. En cas de panne régionale, l'utilisation de tables globales permet une restauration rapide, car le système peut déplacer le traitement de l'appel vers une autre région où une copie répliquée des données existe déjà.
