Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Modèles d'apprentissage automatique pour prévoir la demande de fret
L'image suivante montre un exemple des données d'entraînement. La cible est ce que vous souhaitez prévoir, et les séries chronologiques 1 et 2 associées sont des entités d'entrée pertinentes pour prédire la cible. Les données historiques sont utilisées pour l'entraînement et la validation, et vous ne divulguez pas une période des données historiques pour la validation du modèle.
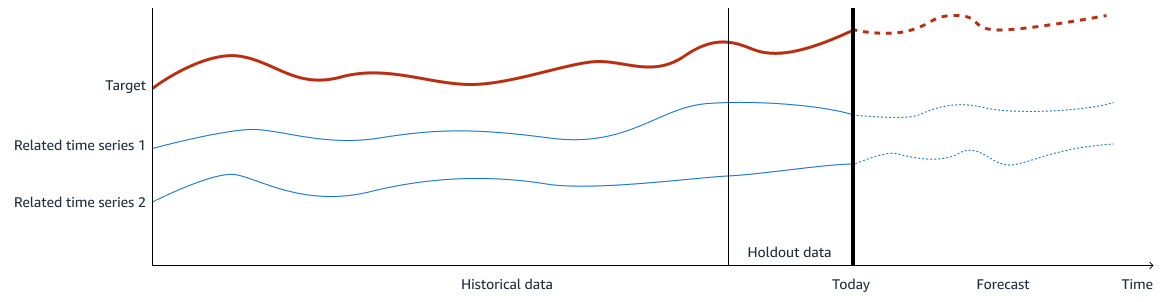
Dans le cadre de la prévision de la demande, le résultat (ou cible) est le volume de demande que vous souhaitez prévoir. Les entités en entrée sont des données de séries chronologiques liées à la sortie. Pour entraîner un modèle de machine learning à établir une prévision précise du volume de demande, deux modèles d'apprentissage automatique sont nécessaires dans la solution. Le premier modèle établit une prévision chronologique pour les entités en entrée, y compris les données internes et externes. Le second modèle fait la prévision de la demande finale en utilisant toutes les fonctionnalités. En utilisant ces deux modèles ensemble, vous pouvez capturer efficacement à la fois la tendance de la série chronologique et la relation entre la cible et les entrées.
Modèle ML pour la prévision des entités en entrée
Les fonctionnalités d'entrée incluent des données de séries chronologiques historiques internes et externes. Pour établir des prévisions pour chaque entité, vous pouvez utiliser un modèle de série chronologique unidimensionnel (1D). Différents algorithmes sont disponibles. Par exemple, Prophet
Modèle ML pour la prévision des variables cibles
Le modèle ML pour la sortie, ou le volume de demande, est conçu pour capturer la relation entre toutes les fonctionnalités et la sortie. Vous pouvez utiliser différents modèles de régression supervisée, tels que lassoridge regression,random forest, etXGBoost. Lorsque vous créez le modèle et que vous recherchez les meilleurs paramètres et hyperparamètres, vous pouvez utiliser des données fiables. Les données rémanentes sont une partie des données historiques étiquetées qui ne sont pas divulguées dans le jeu de données utilisé pour entraîner un modèle d'apprentissage automatique. Vous pouvez utiliser les données de blocage pour évaluer les performances du modèle en comparant les prévisions aux données de blocage.
