Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Étude de cas
Cette section examine un scénario commercial réel et une application pour quantifier l'incertitude dans les systèmes d'apprentissage profond. Supposons que vous souhaitiez qu'un modèle d'apprentissage automatique juge automatiquement si une phrase est grammaticalement inacceptable (cas négatif) ou acceptable (cas positif). Considérez le processus métier suivant : si le modèle indique qu'une phrase est grammaticalement acceptable (positive), vous la traitez automatiquement, sans révision humaine. Si le modèle indique que la phrase est inacceptable (négative), vous la transmettez à un humain pour révision et correction. L'étude de cas utilise des ensembles profonds ainsi qu'une mise à l'échelle de la température.
Ce scénario a deux objectifs commerciaux :
-
Taux de rappel élevé pour les cas négatifs. Nous voulons attraper toutes les phrases contenant des erreurs grammaticales.
-
Réduction de la charge de travail manuelle. Nous voulons traiter automatiquement les cas ne comportant aucune erreur grammaticale dans la mesure du possible.
Résultats de référence
Lorsque vous appliquez un modèle unique aux données sans perte de données au moment du test, voici les résultats :
-
Pour un échantillon positif : rappel = 94 %, précision = 82 %
-
Pour un échantillon négatif : rappel = 52 %, précision = 79 %
Les performances du modèle sont bien inférieures pour les échantillons négatifs. Toutefois, pour les applications professionnelles, le rappel des échantillons négatifs doit être la mesure la plus importante.
Application d'ensembles profonds
Pour quantifier l'incertitude du modèle, nous avons utilisé les écarts types des prédictions des modèles individuels pour des ensembles profonds. Notre hypothèse est que pour les faux positifs (FP) et les faux négatifs (FN), nous nous attendons à ce que l'incertitude soit beaucoup plus élevée que pour les vrais positifs (TP) et les vrais négatifs (TN). Plus précisément, le modèle doit avoir un niveau de confiance élevé lorsqu'il est correct et un niveau de confiance faible lorsqu'il est faux, afin que nous puissions utiliser l'incertitude pour savoir quand faire confiance aux résultats du modèle.
La matrice de confusion suivante montre la distribution de l'incertitude entre les données FN, FP, TN et TP. La probabilité d'un écart type négatif est l'écart type de la probabilité d'un écart type négatif entre les modèles. La médiane, la moyenne et les écarts types sont agrégés dans l'ensemble de données.
| Probabilité d'écart type négatif | |||
|---|---|---|---|
| Étiquette | Médiane | Méchant | Écart type |
FN |
0,061 |
0,060 |
0,027 |
FP |
0,063 |
0,062 |
0,040 |
TN |
0,039 |
0,045 |
0,026 |
TP |
0,009 |
0,020 |
0,025 |
Comme le montre la matrice, le modèle a donné les meilleurs résultats pour le TP, c'est donc celui qui présente le moins d'incertitude. Le modèle a donné les pires résultats pour la PF, ce qui présente le plus d'incertitude, ce qui est conforme à notre hypothèse.
Pour visualiser directement l'écart du modèle entre les ensembles, le graphique suivant trace la probabilité dans une vue en nuage de points pour FN et FP pour les données CoLA. Chaque ligne verticale correspond à un échantillon d'entrée spécifique. Le graphique montre huit vues de modèles d'ensemble. C'est-à-dire que chaque ligne verticale comporte huit points de données. Ces points se chevauchent parfaitement ou sont répartis dans une plage.
Le premier graphique montre que pour le FPs, la probabilité d'être positif se répartit entre 0,5 et 0,925 dans les huit modèles de l'ensemble.

De même, le graphique suivant montre que pour le FNs, la probabilité d'être négatif se répartit entre 0,5 et 0,85 entre les huit modèles de l'ensemble.

Définition d'une règle de décision
Pour tirer le meilleur parti des résultats, nous utilisons la règle d'ensemble suivante : pour chaque entrée, nous prenons le modèle qui a la plus faible probabilité d'être positif (acceptable) afin de prendre des décisions de signalement. Si la probabilité sélectionnée est supérieure ou égale à la valeur seuil, nous signalons le cas comme acceptable et le traitons automatiquement. Dans le cas contraire, nous envoyons le dossier pour examen par un humain. Il s'agit d'une règle de décision conservatrice qui convient aux environnements hautement réglementés.
Évaluation des résultats
Le graphique suivant montre la précision, le taux de rappel et le taux automatique (automatisation) pour les cas négatifs (cas présentant des erreurs grammaticales). Le taux d'automatisation fait référence au pourcentage de cas qui seront traités automatiquement car le modèle indique que la phrase est acceptable. Un modèle parfait avec un rappel et une précision de 100 % atteindrait un taux d'automatisation de 69 % (cas positifs/nombre total de cas), car seuls les cas positifs seront traités automatiquement.
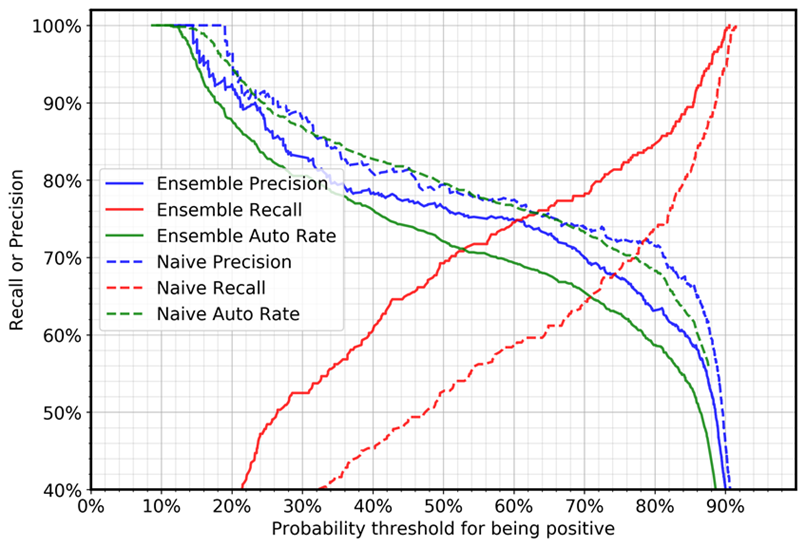
La comparaison entre l'ensemble profond et les cas naïfs montre que, pour le même réglage de seuil, le rappel augmente considérablement et la précision diminue légèrement. (Le taux d'automatisation dépend du ratio d'échantillonnage positif et négatif dans l'ensemble de données de test.) Par exemple :
-
En utilisant une valeur de seuil de 0,5 :
-
Avec un seul modèle, le rappel pour les cas négatifs sera de 52 %.
-
Avec l'approche d'ensemble approfondie, la valeur de rappel sera de 69 %.
-
-
En utilisant une valeur de seuil de 0,88 :
-
Avec un seul modèle, le taux de rappel pour les cas négatifs sera de 87 %.
-
Avec l'approche d'ensemble profond, la valeur de rappel sera de 94 %.
-
Vous pouvez constater qu'un ensemble profond peut améliorer certains indicateurs (dans notre cas, le rappel de cas négatifs) pour les applications métier, sans qu'il soit nécessaire d'augmenter la taille des données de formation, leur qualité ou de modifier la méthode du modèle.
