Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Couverture et précision des documents — dans le domaine
Nous avons comparé les performances prédictives d'ensembles profonds avec le décrochage appliqué au moment du test, le décrochage MC et une fonction softmax naïve, comme le montre le graphique suivant. Après inférence, les prévisions présentant les incertitudes les plus élevées ont été abandonnées à différents niveaux, ce qui a permis d'obtenir une couverture de données restante comprise entre 10 % et 100 %. Nous nous attendions à ce que l'ensemble profond identifie plus efficacement les prédictions incertaines en raison de sa plus grande capacité à quantifier l'incertitude épistémique, c'est-à-dire à identifier les régions des données où le modèle possède moins d'expérience. Cela devrait se traduire par une plus grande précision pour les différents niveaux de couverture des données. Pour chaque ensemble profond, nous avons utilisé 5 modèles et appliqué l'inférence 20 fois. Pour le décrochage de MC, nous avons appliqué l'inférence 100 fois pour chaque modèle. Nous avons utilisé le même ensemble d'hyperparamètres et la même architecture de modèle pour chaque méthode.
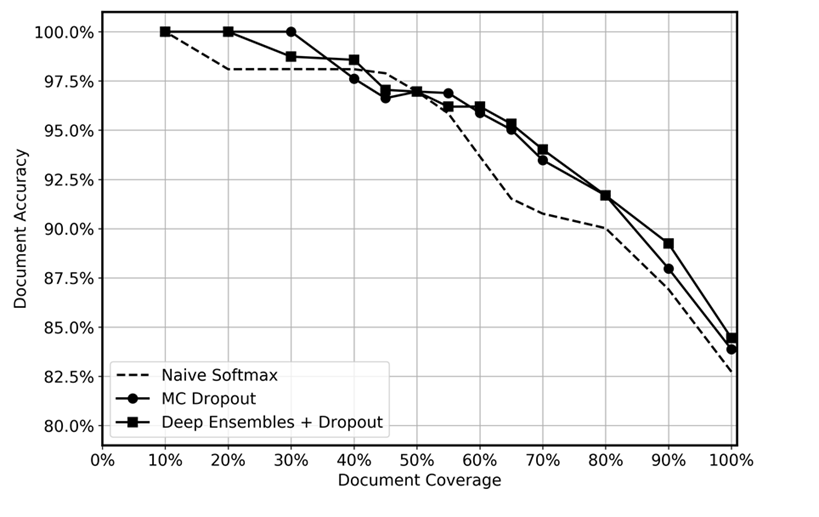
Le graphique semble montrer un léger avantage à utiliser des ensembles profonds et à abandonner les MC par rapport à un softmax naïf. Cela est particulièrement notable dans la plage de couverture des données comprise entre 50 et 80 %. Pourquoi n'est-ce pas plus important ? Comme indiqué dans la section sur les ensembles profonds, la force des ensembles profonds provient des différentes trajectoires de perte empruntées. Dans ce cas, nous utilisons des modèles préentraînés. Bien que nous ayons affiné l'ensemble du modèle, la grande majorité des poids sont initialisés à partir du modèle préentraîné, et seules quelques couches cachées sont initialisées de manière aléatoire. Par conséquent, nous supposons que le préentraînement de grands modèles peut entraîner un excès de confiance en raison d'une faible diversification. À notre connaissance, l'efficacité des ensembles profonds n'a jamais été testée auparavant dans des scénarios d'apprentissage par transfert, et nous considérons qu'il s'agit d'un domaine passionnant pour les recherches futures.
