Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Dimensionnement de la température
Dans les problèmes de classification, les probabilités prédites (sortie softmax) sont supposées représenter la vraie probabilité d'exactitude pour la classe prédite. Cependant, bien que cette hypothèse ait pu être raisonnable pour les modèles il y a une dizaine d'années, elle n'est pas vraie pour les modèles modernes de réseaux neuronaux actuels (Guo et coll. 2017). La perte de connexion entre les probabilités de prédiction du modèle et la confiance des prédictions des modèles empêcherait l'application de modèles modernes de réseaux neuronaux aux problèmes réels, comme dans les systèmes de prise de décision. La connaissance précise du score de confiance des prédictions de modèles est l'un des paramètres de contrôle des risques les plus critiques requis pour créer des applications d'apprentissage automatique robustes et fiables.
Les modèles de réseaux neuronaux modernes ont tendance à avoir de grandes architectures avec des millions de paramètres d'apprentissage. La distribution des probabilités de prédiction dans ces modèles est souvent fortement asymétrique à 1 ou 0, ce qui signifie que le modèle est trop confiant et que la valeur absolue de ces probabilités pourrait être dénuée de sens. (Ce problème est indépendant du fait que le déséquilibre des classes soit présent dans le jeu de données.) Différentes méthodes d'étalonnage permettant de créer un score de confiance de prédiction ont été développées au cours des dix dernières années à travers des étapes de post-traitement afin de recalibrer les probabilités naïves du modèle. Cette section décrit une méthode d'étalonnage appeléeDimensionnement de la température, qui est une technique simple mais efficace pour recalibrer les probabilités de prédiction (Guo et coll. 2017). La mise à l'échelle de la température est une version à paramètre unique de Platt Logistic Scaling (Platt 1999).
La mise à l'échelle de la température utilise un seul paramètre scalaireT > 0, oùTreprésente la température, pour redimensionner les scores logit avant d'appliquer la fonction softmax, comme illustré sur la figure suivante. Parce que la même choseTest utilisé pour toutes les classes, la sortie softmax avec mise à l'échelle a une relation monotonique avec une sortie non dimensionnée. QuandT= 1, vous récupérez la probabilité d'origine avec la fonction Softmax par défaut. Dans des modèles trop confiants oùT > 1, les probabilités recalibrées ont une valeur inférieure aux probabilités initiales, et elles sont réparties plus uniformément entre 0 et 1.
La méthode pour obtenir une température optimaleTpour un modèle entraîné, c'est en minimisant la probabilité de journal négatif pour un jeu de données de validation bloqué.
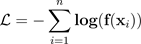
Nous vous recommandons d'intégrer la méthode de mise à l'échelle de la température dans le cadre du processus de formation au modèle : Une fois la formation sur le modèle terminée, extrayez la valeur de températureTen utilisant le jeu de données de validation, puis en redimensionnant les valeurs logit en utilisantTdans la fonction softmax. Sur la base d'expériences de tâches de classification de texte utilisant des modèles Bert, la températureTs'échelonne généralement entre 1,5 et 3.
La figure suivante illustre la méthode de mise à l'échelle de la température, qui applique la valeur de températureTavant de passer le score logit à la fonction softmax.
Les probabilités étalonnées par échelle de température peuvent représenter approximativement le score de confiance des prédictions du modèle. Cela peut être évalué quantitativement en créant un diagramme de fiabilité (Guo et coll. 2017), qui représente l'alignement entre la distribution de la précision attendue et la distribution des probabilités de prédiction.
L'échelle de température a également été évaluée comme un moyen efficace de quantifier l'incertitude prédictive totale dans les probabilités calibrées, mais elle n'est pas robuste pour capturer l'incertitude épistémique dans des scénarios tels que les dérives de données (Ovadia et coll. 2019). Compte tenu de la facilité de mise en œuvre, nous vous recommandons d'appliquer une échelle de température à la sortie de votre modèle Deep Learning afin de créer une solution robuste pour quantifier les incertitudes prédictives.
