Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Cycle de vie des données
Pour créer un pipeline de données, vous devez d'abord ingérer des données dans AWS à partir d'une source de données externe ou interne, telle qu'un serveur de fichiers, une base de données, un bucket de stockage ou un appel d'API. Les données ingérées peuvent ou non subir une transformation, telle que l'anonymisation, la suppression de colonnes ou le nettoyage des données.
Cette section fournit une vue d'ensemble des étapes du processus de cycle de vie des données, comme le montre le schéma suivant.
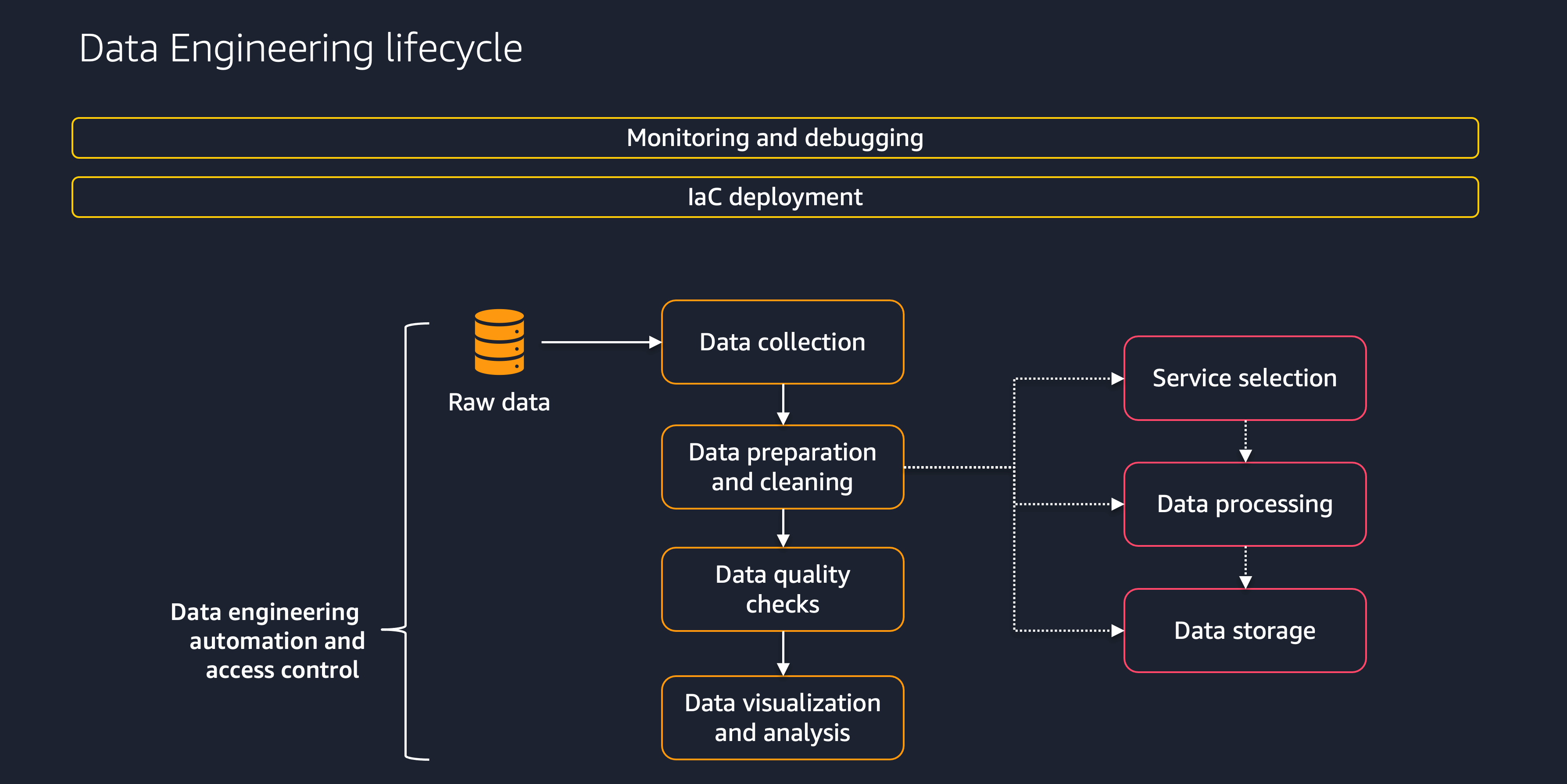
Ces étapes sont notamment les suivantes :
-
Collecte des données
-
Préparation et nettoyage des données
-
Contrôles de qualité des données
-
Visualisation et analyse des données
-
Surveillance et débogage
-
Déploiement iA
-
Automatisation et contrôle d'accès
