Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Préparation et nettoyage des données
La préparation et le nettoyage des données constituent l'une des étapes les plus importantes mais les plus chronophages du cycle de vie des données. Le schéma suivant montre comment l'étape de préparation et de nettoyage des données s'inscrit dans le cycle de vie de l'automatisation de l'ingénierie des données et du contrôle d'accès.
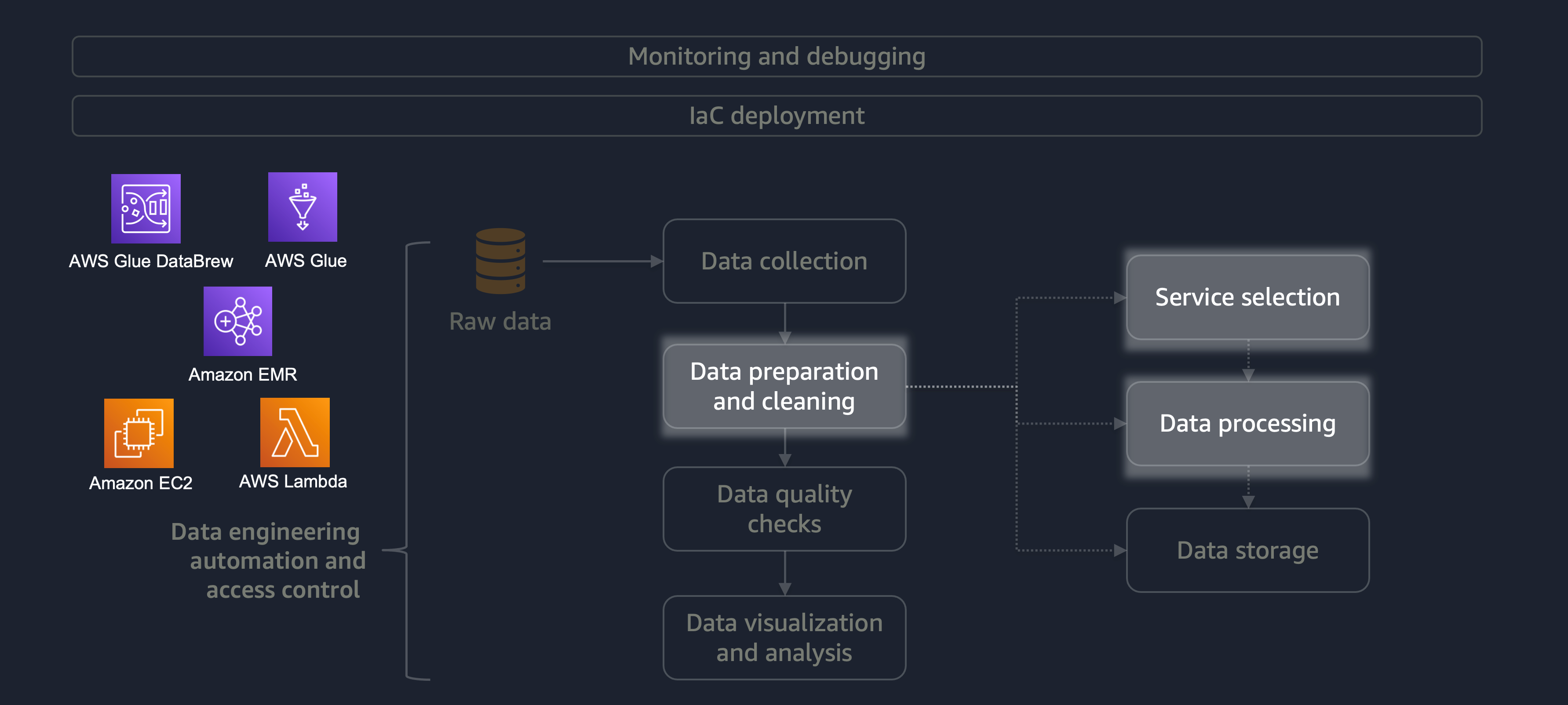
Voici quelques exemples de préparation ou de nettoyage des données :
-
Associer des colonnes de texte à des codes
-
Ignorer les colonnes vides
-
Remplir les champs de données vides avec
0None, ou'' -
Anonymisation ou masquage des informations personnelles identifiables (PII)
Si votre charge de travail comporte une grande variété de données, nous vous recommandons d'utiliser Amazon EMRDataFrame ou DynamicFrame utiliser un traitement horizontal. En outre, vous pouvez utiliser AWS Glue DataBrew
Pour les petites charges de travail ne nécessitant pas de traitement distribué et pouvant être effectuées en moins de 15 minutes, nous vous recommandons d'utiliser AWS
Il est essentiel de choisir le bon service AWS pour la préparation et le nettoyage des données et de comprendre les inconvénients liés à votre choix. Par exemple, imaginez un scénario dans lequel vous avez le choix entre AWS Glue et Amazon EMR. DataBrew AWS Glue est idéal si les tâches ETL sont peu fréquentes. Un travail occasionnel a lieu une fois par jour, une fois par semaine ou une fois par mois. Vous pouvez également partir du principe que vos ingénieurs de données maîtrisent l'écriture de code Spark (pour les cas d'utilisation de mégadonnées) ou les scripts en général. Si le travail est plus fréquent, l'exécution constante d'AWS Glue peut s'avérer coûteuse. Dans ce cas, Amazon EMR fournit des fonctionnalités de traitement distribué et propose à la fois une version sans serveur et une version basée sur serveur. Si vos ingénieurs de données ne possèdent pas les compétences requises ou si vous devez obtenir des résultats rapidement, DataBrew c'est une bonne option. DataBrew peut réduire les efforts de développement du code et accélérer le processus de préparation et de nettoyage des données.
Une fois le traitement terminé, les données issues du processus ETL sont stockées sur AWS. Le choix du stockage dépend du type de données que vous traitez. Par exemple, vous pouvez travailler avec des données non relationnelles telles que des données graphiques, des données de paires clé-valeur, des images, des fichiers texte ou des données structurées relationnelles.
Comme le montre le schéma suivant, vous pouvez utiliser les services AWS suivants pour le stockage des données :
-
Amazon S3
stocke des données non structurées ou semi-structurées (par exemple, des fichiers Apache Parquet, des images et des vidéos). -
Amazon Neptune
stocke des ensembles de données graphiques que vous pouvez interroger à l'aide de SPARQL ou GREMLIN. -
Amazon Keyspaces (pour Apache Cassandra)
stocke des ensembles de données compatibles avec Apache Cassandra. -
Amazon Aurora
stocke des ensembles de données relationnels. -
Amazon DynamoDB
stocke les données clé-valeur ou les données de document dans une base de données NoSQL. -
Amazon Redshift
stocke les charges de travail pour les données structurées dans un entrepôt de données.
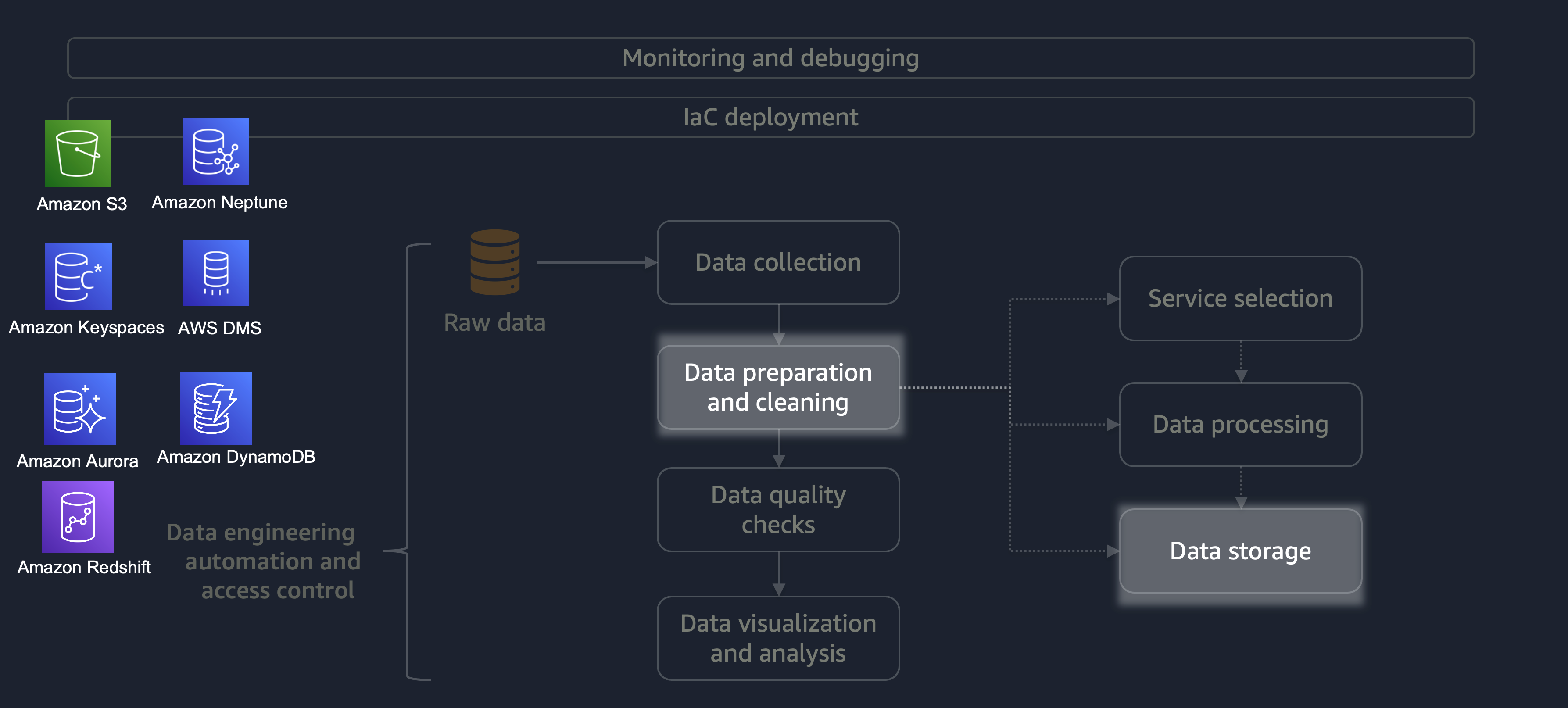
En utilisant le bon service avec les bonnes configurations, vous pouvez stocker vos données de la manière la plus efficace possible. Cela permet de minimiser les efforts liés à la récupération des données.
