Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Pilier d'efficacité des performances
Le pilier de l'efficacité des performances du AWS Well-Architected Framework se concentre sur la manière d'optimiser les performances lors de l'ingestion ou de l'interrogation de données. L'optimisation des performances est un processus progressif et continu comprenant les éléments suivants :
-
Confirmation des exigences commerciales
-
Mesurer les performances de la charge
-
Identifier les composants peu performants
-
Optimisation des composants pour répondre aux besoins de votre entreprise
Le pilier relatif à l'efficacité des performances fournit des directives spécifiques aux cas d'utilisation qui peuvent vous aider à identifier le modèle de données graphique et les langages de requête appropriés à utiliser. Il inclut également les meilleures pratiques à suivre lors de l'ingestion et de la consommation de données dans Neptune Analytics.
Le pilier de l'efficacité en matière de performance se concentre sur les domaines clés suivants :
-
Modélisation de graphes
-
Optimisation des requêtes
-
Dimensionnement correct du graphique
-
Optimisation de l'écriture
Comprendre la modélisation de graphes à des fins d'analyse
Le guide Applying the AWS Well-Architected Framework for Amazon Neptune traite de la modélisation de graphes pour améliorer les performances. Les décisions de modélisation qui affectent les performances incluent le choix des nœuds et des arêtes requis, de leurs IDs étiquettes et de leurs propriétés, de la direction des arêtes, du caractère générique ou spécifique des étiquettes et, d'une manière générale, de l'efficacité avec laquelle le moteur de requêtes peut naviguer dans le graphe pour traiter les requêtes courantes.
Ces considérations s'appliquent également à Neptune Analytics ; il est toutefois important de faire la distinction entre les modèles d'utilisation transactionnels et analytiques. Un modèle de graphe efficace pour les requêtes dans une base de données transactionnelle telle qu'une base de données Neptune devra peut-être être remodelé à des fins d'analyse.
Prenons l'exemple d'un graphique de fraude dans une base de données Neptune dont le but est de détecter les tendances frauduleuses dans les paiements par carte de crédit. Ce graphique peut comporter des nœuds représentant les comptes, les paiements et les fonctionnalités (telles que l'adresse e-mail, l'adresse IP, le numéro de téléphone) du compte et du paiement. Ce graphe connecté prend en charge des requêtes telles que le fait de parcourir un chemin de longueur variable qui part d'un paiement donné et nécessite plusieurs sauts pour trouver les fonctionnalités et les comptes associés. La figure suivante montre un tel graphique.
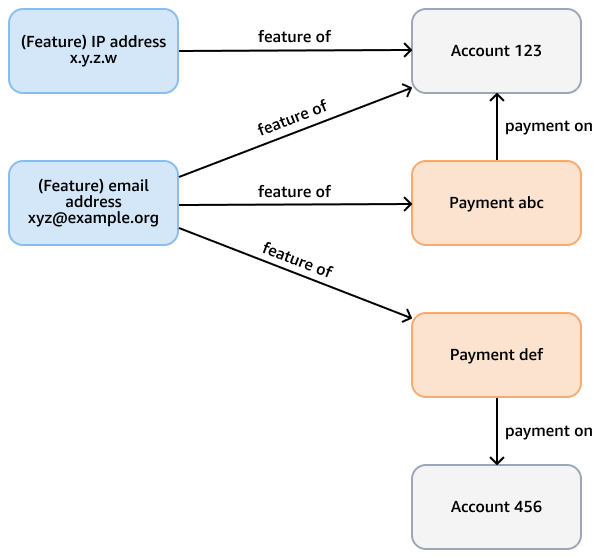
L'exigence d'analyse peut être plus spécifique, par exemple pour trouver des communautés de comptes liées par une fonctionnalité. Vous pouvez utiliser l'algorithme WCC (Weakly Connected Components) à cette fin. Il est inefficace de l'exécuter par rapport au modèle de l'exemple précédent, car il doit traverser plusieurs types de nœuds et d'arêtes. Le modèle du schéma suivant est plus efficace. Il relie les account nœuds à un shares feature avantage si les comptes eux-mêmes (ou les paiements provenant des comptes) partagent une même fonctionnalité. Par exemple, Account 123 possède une fonctionnalité xyz@example.org de courrier électronique et Account 456 utilise le même e-mail pour un paiement (Payment def).

La complexité informatique du WCC |E| est O(|E|logD) le nombre d'arêtes dans le graphique et D le diamètre (la longueur du chemin le plus long) qui relie les nœuds. Comme le modèle transactionnel omet les nœuds non essentiels, il optimise à la fois le nombre d'arêtes et le diamètre, et réduit la complexité de l'algorithme WCC.
Lorsque vous utilisez Neptune Analytics, revenez à partir des algorithmes et des requêtes analytiques requis. Si nécessaire, modifiez le modèle pour optimiser ces requêtes. Vous pouvez remodeler le modèle avant de charger des données dans le graphique ou d'écrire des requêtes qui modifient les données existantes dans le graphique.
Optimisation des requêtes
Suivez ces recommandations pour optimiser les requêtes Neptune Analytics :
-
Utilisez les requêtes paramétrées et le cache du plan de requêtes, qui est activé par défaut. Lorsque vous utilisez le cache du plan, le moteur prépare la requête pour une utilisation ultérieure, à condition qu'elle soit terminée en 100 millisecondes ou moins, ce qui permet de gagner du temps lors des appels suivants.
-
Pour les requêtes lentes, exécutez un plan d'explication pour identifier les goulots d'étranglement et apporter des améliorations en conséquence.
-
Si vous utilisez la recherche par similarité vectorielle, déterminez si des incorporations plus petites produisent des résultats de similarité précis. Vous pouvez créer, stocker et rechercher des intégrations plus petites de manière plus efficace.
-
Suivez les meilleures pratiques documentées pour utiliser OpenCypher dans Neptune Analytics. Par exemple, utilisez des cartes aplaties dans une clause UNWIND et spécifiez des étiquettes de bord dans la mesure du possible.
-
Lorsque vous utilisez un algorithme graphique, comprenez les entrées et les sorties de l'algorithme, sa complexité de calcul et, d'une manière générale, son fonctionnement.
-
Avant d'appeler un algorithme graphique, utilisez une
MATCHclause pour minimiser l'ensemble de nœuds en entrée. Par exemple, pour limiter les nœuds à partir desquels effectuer une recherche basée sur l'étendue (BFS), suivez les exemples fournis dans la documentation de Neptune Analytics. -
Filtrez sur les étiquettes des nœuds et des arêtes si possible. Par exemple, BFS dispose de paramètres d'entrée pour filtrer le passage vers une étiquette de nœud spécifique (
vertexLabel) ou des étiquettes de bord spécifiques (edgeLabels). -
Utilisez des paramètres de délimitation, par exemple
maxDepthpour limiter les résultats. -
Expérimentez avec le
concurrencyparamètre. Essayez-le avec une valeur de 0, qui utilise tous les threads d'algorithme disponibles pour paralléliser le traitement. Comparez cela à l'exécution monothread en définissant le paramètre sur 1. Un algorithme peut être exécuté plus rapidement dans un seul thread, en particulier sur des entrées plus petites, telles que les recherches de faible envergure, où le parallélisme n'entraîne aucune réduction mesurable du temps d'exécution et peut entraîner une surcharge. -
Choisissez entre des types d'algorithmes similaires. Par exemple, Bellman-Ford et Delta-Stepping sont tous deux des algorithmes à source unique sur le chemin le plus court. Lorsque vous testez avec votre propre ensemble de données, essayez les deux algorithmes et comparez les résultats. Le delta-step est souvent plus rapide que celui de Bellman-Ford en raison de sa faible complexité de calcul. Toutefois, les performances dépendent du jeu de données et des paramètres d'entrée, en particulier du
deltaparamètre.
-
Optimisez les écritures
Suivez les pratiques suivantes pour optimiser les opérations d'écriture dans Neptune Analytics :
-
Recherchez le moyen le plus efficace de charger des données dans un graphique. Lorsque vous chargez à partir de données dans Amazon S3, utilisez l'importation en bloc si la taille des données est supérieure à 50 Go. Pour des données plus petites, utilisez le chargement par lots. Si vous rencontrez out-of-memory des erreurs lorsque vous exécutez le chargement par lots, pensez à augmenter la valeur m-NCU ou à diviser la charge en plusieurs demandes. L'un des moyens d'y parvenir consiste à répartir les fichiers entre plusieurs préfixes dans le compartiment S3. Dans ce cas, appelez batch load séparément pour chaque préfixe.
-
Utilisez l'importation en bloc ou le chargeur par lots pour renseigner l'ensemble initial de données graphiques. Utilisez les opérations transactionnelles de création, de mise à jour et de suppression d'OpenCypher uniquement pour les modifications mineures.
-
Utilisez l'importation en bloc ou le chargeur par lots avec une simultanéité de 1 (thread unique) pour intégrer les éléments intégrés dans le graphique. Essayez de charger les intégrations dès le départ en utilisant l'une de ces méthodes.
-
Évaluez la dimension des intégrations vectorielles nécessaires pour une recherche de similarité précise dans les algorithmes de recherche de similarité vectorielle. Utilisez une dimension plus petite si possible. Cela se traduit par une vitesse de chargement plus rapide pour les intégrations.
-
Utilisez des algorithmes de mutation pour mémoriser les résultats algorithmiques si nécessaire. Par exemple, l'algorithme de centralité Degré Mutate trouve le degré de chaque nœud d'entrée et écrit cette valeur en tant que propriété du nœud. Si les connexions entourant ces nœuds ne changent pas par la suite, la propriété contient le résultat correct. Il n'est pas nécessaire de réexécuter l'algorithme.
-
Utilisez l'action administrative de réinitialisation du graphe pour effacer tous les nœuds, arêtes et intégrations si vous devez recommencer à zéro. Il n'est pas possible de supprimer tous les nœuds, arêtes et intégrations à l'aide d'une requête OpenCypher si votre graphe est volumineux. Le délai d'expiration d'une seule requête sur un ensemble de données volumineux peut être dépassé. À mesure que la taille augmente, le jeu de données prend plus de temps à être supprimé et la taille des transactions augmente. En revanche, le temps nécessaire pour effectuer une réinitialisation du graphe est à peu près constant, et l'action permet de créer un instantané avant de l'exécuter.
Graphiques à la bonne taille
Les performances globales dépendent de la capacité allouée à un graphe Neptune Analytics. La capacité est mesurée en unités appelées unités de capacité Neptune optimisées pour la mémoire (m -). NCUs Assurez-vous que la taille de votre graphique est suffisante pour prendre en charge la taille de votre graphique et vos requêtes. Notez que l'augmentation de la capacité n'améliore pas nécessairement les performances d'une requête individuelle.
Si possible, créez le graphique en important des données depuis une source existante telle qu'Amazon S3 ou un cluster ou un instantané Neptune existant. Vous pouvez limiter la capacité minimale et maximale. Vous pouvez également modifier la capacité allouée sur un graphique existant.
Surveillez CloudWatch des indicateurs tels que NumQueuedRequestsPerSecNumOpenCypherRequestsPerSec,GraphStorageUsagePercent,GraphSizeBytes, et CPUUtilization pour déterminer si le graphique est de bonne taille. Déterminez si une capacité supplémentaire est nécessaire pour supporter la taille et la charge de votre graphe. Pour plus d'informations sur la manière d'interpréter certains de ces indicateurs, consultez la section Pilier d'excellence opérationnelle.
