Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Traitement des requêtes SQL dans Amazon Redshift
Amazon Redshift achemine une requête SQL soumise à travers l’analyseur et l’optimiseur pour développer un plan de requête. Le moteur d’exécution traduit ensuite le plan de requête en code et envoie celui-ci aux nœuds de calcul à des fins d’exécution. Avant de concevoir un plan de requêtes, il est essentiel de comprendre le fonctionnement du traitement des requêtes.
Workflow d’exécution et de planification de requête
Le schéma suivant fournit une vue détaillée du flux de travail de planification et d'exécution des requêtes.
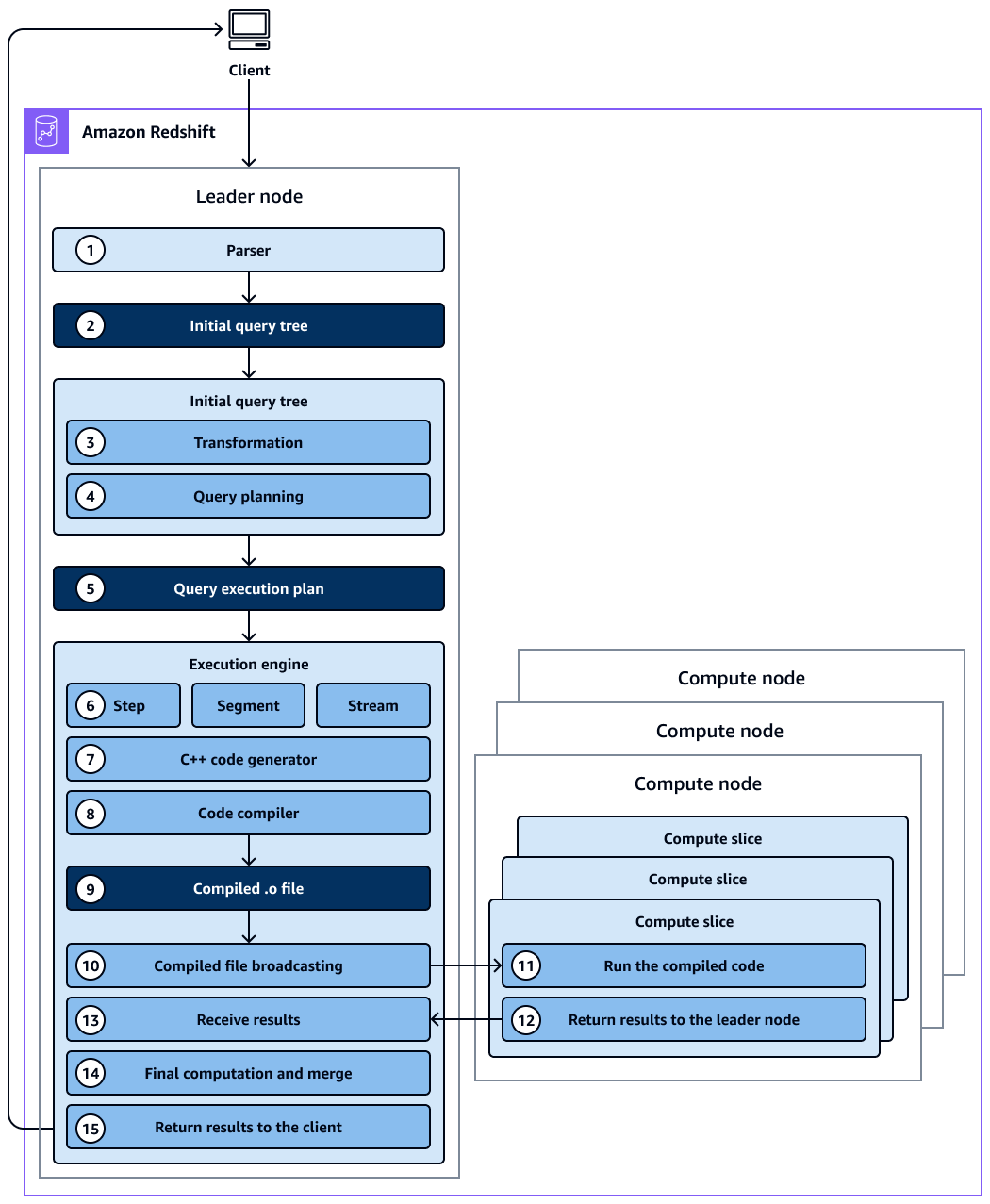
Le schéma suivant illustre le flux de travail suivant :
-
Le nœud principal du cluster Amazon Redshift reçoit la requête et analyse l'instruction SQL.
-
L'analyseur produit un arbre de requête initial qui est une représentation logique de la requête d'origine.
-
L'optimiseur de requêtes prend l'arbre de requêtes initial et l'évalue, analyse les statistiques des tables pour déterminer l'ordre de jointure et la sélectivité des prédicats et, si nécessaire, réécrit la requête pour optimiser son efficacité. Parfois, une seule requête peut être écrite sous la forme de plusieurs instructions dépendantes en arrière-plan.
-
L’optimiseur génère un plan de requête (ou plusieurs, si l’étape précédente entraîné la création de plusieurs requêtes) pour que l’exécution s’effectue avec les meilleures performances. Le plan de requête spécifie les options d'exécution telles que l'ordre d'exécution, les opérations réseau, les types de jointure, l'ordre de jointure, les options d'agrégation et les distributions de données.
-
Un plan de requête contient des informations sur les opérations individuelles requises pour exécuter une requête. Vous pouvez utiliser la commande
EXPLAINpour afficher le plan de requête. Le plan de requête est un outil fondamental permettant d’analyser et d’ajuster des requêtes complexes. -
L'optimiseur de requêtes envoie le plan de requêtes au moteur d'exécution. Le moteur d'exécution vérifie si le cache du plan compilé correspond au plan de requête et utilise le cache compilé (s'il est trouvé). Sinon, le moteur d'exécution traduit le plan de requête en étapes, en segments et en flux :
-
Les étapes sont des opérations individuelles qui ont lieu pendant l'exécution de la requête. Les étapes sont identifiées par une étiquette (par exemple
scan,dist,hjoin, oumerge). Un pas est la plus petite unité. Vous pouvez combiner les étapes afin que les nœuds de calcul puissent effectuer une requête, une jointure ou une autre opération de base de données. -
Un segment fait référence à un segment d'une requête et combine plusieurs étapes pouvant être effectuées par un seul processus. Un segment est la plus petite unité de compilation exécutable par une tranche de nœud de calcul. Une tranche est l’unité de traitement parallèle dans Amazon Redshift.
-
Un flux est un ensemble de segments à répartir sur les tranches de nœuds de calcul disponibles. Les segments d'un flux s'exécutent en parallèle sur des tranches de nœuds. Par conséquent, la même étape provenant du même segment est également exécutée en parallèle dans plusieurs tranches.
-
-
Le générateur de code reçoit le plan traduit et génère une fonction C++ pour chaque segment.
-
La fonction C++ générée est compilée par la collection de compilateurs GNU et convertie en fichier O (
.o). -
Le code compilé (fichier O) s'exécute. Le code compilé s’exécute plus vite qu’un code interprété et utilise moins de capacité de calcul.
-
Le fichier O compilé est ensuite diffusé aux nœuds de calcul.
-
Chaque nœud de calcul est composé de plusieurs tranches de calcul. Les tranches de calcul exécutent les segments de requête en parallèle. Amazon Redshift tire parti de l'optimisation des communications réseau, de la mémoire et de la gestion des disques pour transmettre les résultats intermédiaires d'une étape du plan de requêtes à l'autre. Cela permet également d'accélérer l'exécution des requêtes. Éléments à prendre en compte :
-
Les étapes 6, 7, 8, 9, 10 et 11 se produisent une fois pour chaque flux.
-
Le moteur crée les segments exécutables pour un flux et envoie ces segments aux nœuds de calcul.
-
Une fois les segments d'un flux précédent terminés, le moteur génère les segments pour le flux suivant. Ainsi, le moteur peut analyser ce qui est arrivé dans le flux précédent (par exemple, si les opérations étaient basées sur le disque) pour influencer la génération de segments dans le flux suivant.
-
-
Une fois les nœuds de calcul terminés, ils renvoient les résultats de la requête au nœud principal pour le traitement final. Le nœud principal fusionne les données en un seul ensemble de résultats et prend en charge tout tri ou agrégation requis.
-
Le nœud leader renvoie les résultats au client.
Le schéma suivant montre le flux de travail d'exécution des flux, des segments, des étapes et des tranches de nœuds de calcul. Gardez à l’esprit les points suivants :
-
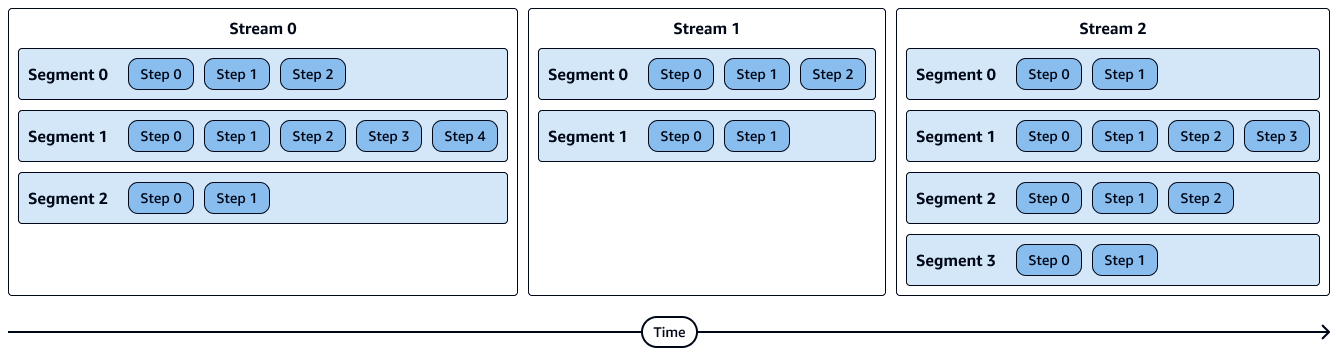
Les étapes d'un segment s'exécutent de manière séquentielle.
-
Les segments d'un stream s'exécutent en parallèle.
-
Les flux s'exécutent de manière séquentielle.
-
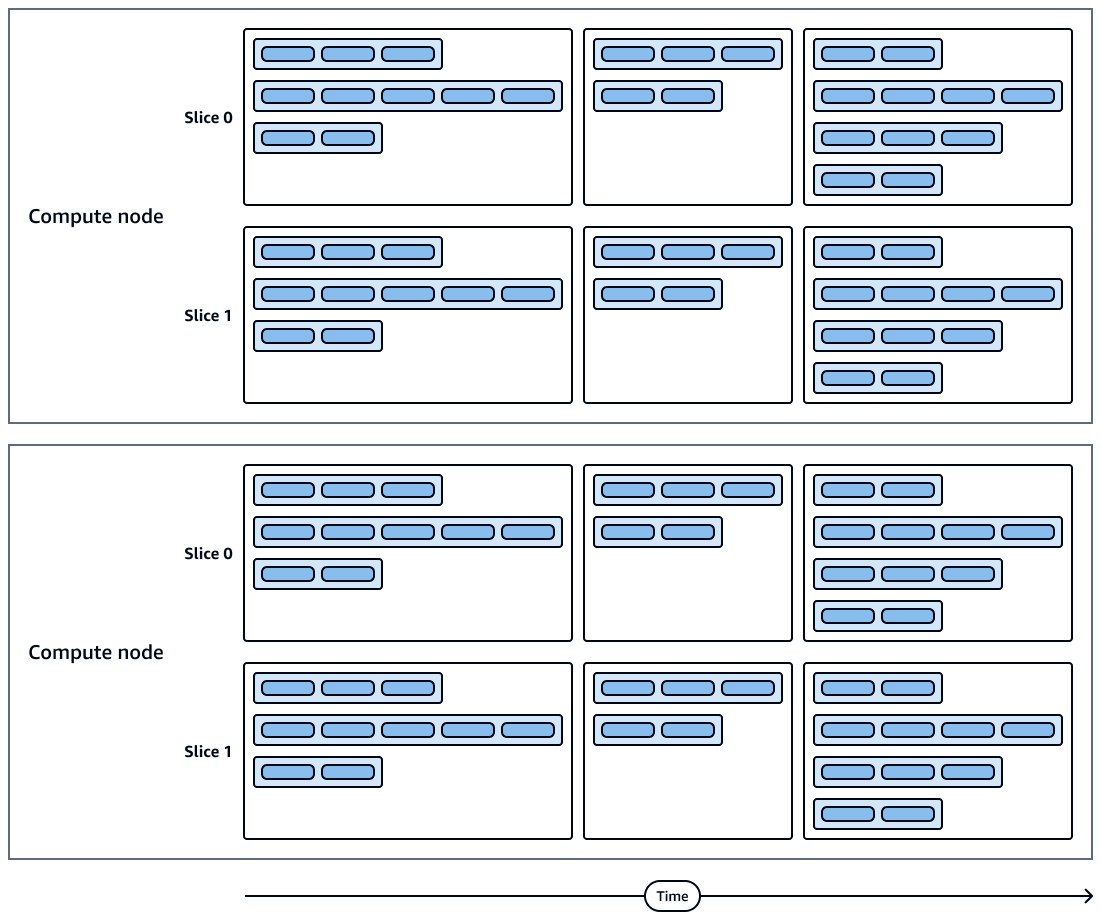
Les tranches de nœuds de calcul s'exécutent en parallèle.
Le schéma suivant montre une représentation visuelle des flux, des segments et des étapes. Chaque segment contient plusieurs étapes et chaque flux contient plusieurs segments.
Le schéma suivant montre une représentation visuelle des exécutions de requêtes et des tranches de nœuds de calcul. Chaque nœud de calcul contient plusieurs tranches, flux, segments et étapes.
Considérations supplémentaires
Nous vous recommandons de prendre en compte les points suivants en ce qui concerne le traitement des requêtes :
-
Le code compilé mis en cache est partagé entre les sessions du même cluster, de sorte que les exécutions ultérieures de la même requête seront plus rapides, souvent même avec des paramètres différents.
-
Lorsque vous comparez vos requêtes, nous vous recommandons de toujours comparer les durées de la deuxième exécution d'une requête, car la première exécution inclut le surcoût lié à la compilation du code. Pour plus d'informations, consultez la section Facteurs de performance des requêtes dans le guide des meilleures pratiques en matière de requêtes pour Amazon Redshift.
-
Les nœuds de calcul peuvent renvoyer certaines données au nœud principal lors de l'exécution de la requête si nécessaire. Par exemple, si vous avez une sous-requête contenant une
LIMITclause, la limite est appliquée au nœud principal avant que les données ne soient redistribuées dans le cluster pour un traitement ultérieur.
