Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation du cadre
Le cadre d'analyse de résilience a été développé en identifiant les propriétés de résilience souhaitées d'une charge de travail. Les propriétés souhaitées sont ce que vous voulez que le système soit vrai. La résilience étant généralement mesurée par la disponibilité, cinq propriétés caractérisent un système distribué à haute disponibilité : redondance, capacité suffisante, sortie en temps voulu, sortie correcte et isolation des pannes. Ces propriétés sont illustrées dans le schéma suivant.
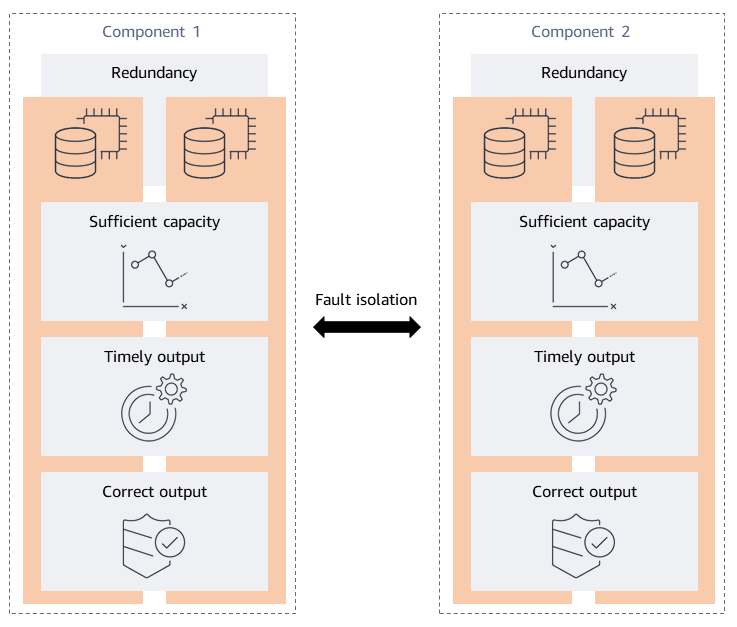
-
Redondance — La tolérance aux pannes est atteinte grâce à une redondance qui élimine les points de défaillance uniques (). SPOFs La redondance peut aller des composants de rechange de votre charge de travail à des répliques complètes de l'ensemble de votre pile d'applications. Lorsque vous envisagez la redondance de vos applications, il est important de prendre en compte le niveau de redondance fourni par l'infrastructure, les magasins de données et les dépendances que vous utilisez. Par exemple, Amazon DynamoDB et Amazon Simple Storage Service (Amazon S3) assurent la redondance en répliquant les données sur plusieurs zones de disponibilité d'une région AWS Lambda et en exécutant vos fonctions sur plusieurs nœuds de travail dans plusieurs zones de disponibilité. Pour chaque service que vous utilisez, tenez compte de ce qu'il fournit et de ce que vous devez concevoir.
-
Capacité suffisante — Votre charge de travail nécessite des ressources suffisantes pour fonctionner comme prévu. Les ressources incluent la mémoire, les cycles du processeur, les threads, le stockage, le débit, les quotas de service et bien d'autres.
-
Production en temps opportun — Lorsque les clients utilisent votre charge de travail, ils s'attendent à ce qu'elle remplisse la fonction prévue dans un délai raisonnable. À moins que le service ne fournisse un accord de niveau de service (SLA) pour la latence, leurs attentes sont généralement basées sur des preuves empiriques, c'est-à-dire sur leur propre expérience. Cette expérience client moyenne est généralement considérée comme la latence médiane (P50) de votre système. Si votre charge de travail prend plus de temps que prévu, cette latence peut affecter l'expérience de vos clients.
-
Sortie correcte — La sortie correcte du logiciel de votre charge de travail est nécessaire pour que celui-ci fournisse les fonctionnalités prévues. Un résultat incorrect ou incomplet peut être pire qu'une absence totale de réponse.
-
Isolation des défauts — L'isolation des défauts limite l'étendue de l'impact au conteneur de défauts prévu en cas de défaillance. Cela garantit que des composants spécifiques de votre charge de travail tombent en panne ensemble tout en empêchant une défaillance de se répercuter sur d'autres composants involontaires. Cela permet également de limiter l'impact de votre charge de travail sur les clients. L'isolation des défauts est quelque peu différente des quatre propriétés précédentes, car elle accepte qu'une défaillance s'est déjà produite mais qu'elle doit être maîtrisée. Vous pouvez isoler les défaillances de votre infrastructure, de vos dépendances et de vos fonctions logicielles.
Lorsqu'une propriété souhaitée n'est pas respectée, une charge de travail peut être ou perçue comme étant indisponible. Sur la base de ces propriétés de résilience souhaitées et de notre expérience de travail avec de nombreux AWS clients, nous avons identifié cinq catégories de défaillances courantes : points de défaillance uniques, charge excessive, latence excessive, erreurs de configuration et bogues, et destin partagé, que nous abrégeons en SEEMS. Ils fournissent une méthode cohérente pour catégoriser les modes de défaillance potentiels et sont décrits dans le tableau suivant.
Catégorie de défaillance |
Violation |
Définition |
|---|---|---|
Points de défaillance uniques (SPOFs) |
Redondance |
Une défaillance d'un seul composant perturbe le système en raison de l'absence de redondance du composant. |
Charge excessive |
Capacité suffisante |
La surconsommation d'une ressource due à une demande ou à un trafic excessif empêche la ressource de remplir la fonction attendue. Cela peut inclure l'atteinte de limites et de quotas, ce qui entraîne la limitation et le rejet des demandes. |
Latence excessive |
Sortie en temps opportun |
La latence du traitement du système ou du trafic réseau dépasse le délai prévu, les objectifs de niveau de service (SLOs) ou les accords de niveau de service (). SLAs |
Mauvaise configuration et bogues |
Sortie correcte |
Des bogues logiciels ou une mauvaise configuration du système entraînent une sortie incorrecte. |
Un destin partagé |
Isolation des défauts |
Un défaut causé par l'une des catégories de défaillance précédentes dépasse les limites d'isolation des défauts prévues et se répercute sur d'autres parties du système ou sur d'autres clients. |
