Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation des astuces de jointure dans Spark SQL
Avec Spark 3.0, vous pouvez spécifier le type d'algorithme de jointure que vous souhaitez Spark à utiliser lors de l'exécution. Les conseils de stratégie de jointure BROADCASTMERGE,SHUFFLE_HASH,SHUFFLE_REPLICATE_NL, et les instructions Spark pour utiliser la stratégie suggérée sur chaque relation spécifiée lorsque vous les associez à une autre relation. Cette section décrit en détail les conseils relatifs à la stratégie de jointure.
DIFFUSER
Dans une jointure Broadcast Hash, l'un des ensembles de données est nettement plus petit que l'autre. Comme le plus petit ensemble de données peut tenir en mémoire, il est diffusé à tous les exécuteurs du cluster. Une fois les données diffusées, une jointure par hachage standard est effectuée. Une jointure Broadcast Hash s'effectue en deux étapes :
-
Diffusion — Le plus petit ensemble de données est diffusé à tous les exécuteurs du cluster.
-
Jointure par hachage : le plus petit ensemble de données est haché sur tous les exécuteurs, puis joint au plus grand ensemble de données.
Il n'y a sort aucune merge opération. Lorsque vous joignez de grandes tables de faits avec des tables de dimensions plus petites utilisées pour effectuer une jointure par schéma en étoile, Broadcast Hash est l'algorithme de jointure le plus rapide. L'exemple suivant montre comment fonctionne une jointure Broadcast Hash. Le côté jointure contenant l'indice est diffusé, quelle que soit la limite de taille spécifiée dans la spark.sql.autoBroadcastJoinThreshold propriété. Si les deux côtés de la jointure contiennent des indices de diffusion, celui dont la taille est la plus petite (sur la base des statistiques) est diffusé. La valeur par défaut de la spark.sql.autoBroadcastJoinThreshold propriété est de 10 Mo. Cela permet de configurer la taille maximale, en octets, d'une table diffusée à tous les nœuds de travail lors de l'exécution d'une jointure.
Les exemples suivants fournissent la requête, le EXPLAIN plan physique et le temps nécessaire à l'exécution de la requête. La requête nécessite moins de temps de traitement si vous utilisez l'BROADCASTJOINindice pour forcer une jointure de diffusion, comme indiqué dans le deuxième exemple de EXPLAIN plan.
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
La jointure Shuffle Sort Merge est recommandée lorsque les deux ensembles de données sont volumineux et ne peuvent pas tenir dans la mémoire. Comme son nom l'indique, cette jointure comporte les trois phases suivantes :
-
Phase de remaniement : les deux ensembles de données de la requête de jointure sont mélangés.
-
Phase de tri — Les enregistrements sont triés à l'aide de la touche de jointure des deux côtés.
-
Phase de fusion : les deux côtés de la condition de jointure sont itérés, en fonction de la clé de jointure.
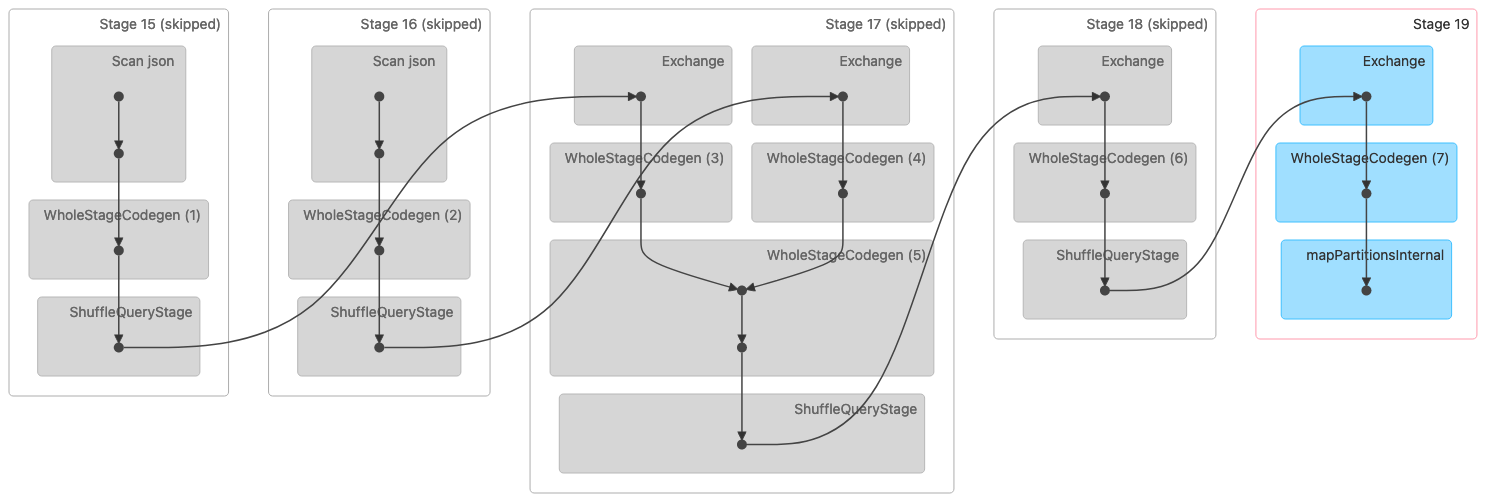
L'image suivante montre une visualisation DAG (Directed Acyclic Graph) d'une jointure Shuffle Sort Merge. Les deux tableaux sont lus au cours des deux premières étapes. À l'étape suivante (étape 17), ils sont mélangés, triés, puis fusionnés à la fin.
Remarque : Certaines étapes de cette image apparaissent comme étant ignorées car elles ont été effectuées lors des étapes précédentes. Ces données ont été mises en cache ou conservées pour être utilisées au cours de ces étapes. |
Ce qui suit est un plan physique qui indique une jointure Sort Merge.
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
La jointure Shuffle Hash, comme son nom l'indique, fonctionne en mélangeant les deux ensembles de données. Les mêmes clés des deux côtés se retrouvent dans la même partition ou tâche. Une fois les données mélangées, le plus petit des deux ensembles de données est haché dans des compartiments, puis une jointure par hachage est effectuée dans la partition. Une jointure Shuffle Hash est différente d'une jointure Broadcast Hash car l'ensemble de données n'est pas diffusé dans son intégralité. Une jointure Shuffle Hash est divisée en deux phases :
-
Phase de remaniement : les deux ensembles de données sont mélangés.
-
Phase de jointure par hachage : le côté le plus petit des données est haché, découpé en compartiments, puis joint par hachage au côté le plus grand dans toutes les partitions.
Le tri n'est pas nécessaire avec les jointures Shuffle Hash à l'intérieur des partitions. L'image suivante montre les phases de la jointure Shuffle Hash. Les données sont d'abord lues, puis elles sont mélangées, puis un hachage est créé et utilisé pour la jointure.
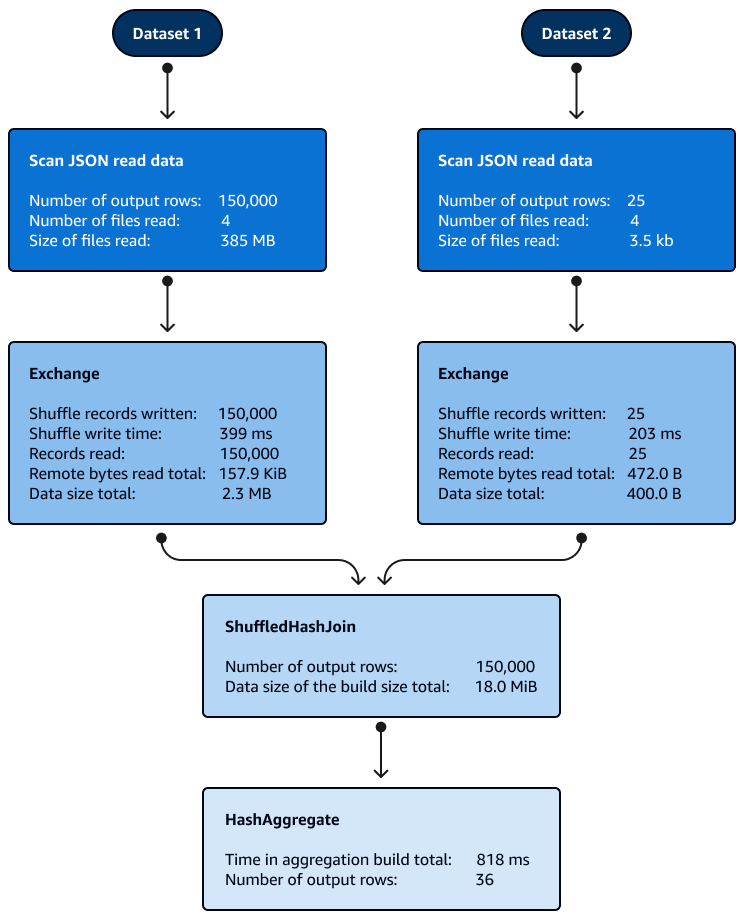
Par défaut, l'optimiseur choisit la jointure Shuffle Hash lorsque la jointure Broadcast Hash ne peut pas être utilisée. Sur la base du seuil de jointure Broadcast Hash (spark.sql.autoBroadcastJoinThreshold) et du nombre de partitions shuffle (spark.sql.shuffle.partitions) choisies, il utilise la jointure Shuffle Hash lorsque la partition unique du SQL logique est suffisamment petite pour créer une table de hachage locale.
SHUFFLE_REPLICATE_FR
La jointure Shuffle-and-Replicate Nested Loop, également connue sous le nom de jointure de produit cartésien, fonctionne de manière très similaire à une jointure Broadcast Hash, sauf que le jeu de données n'est pas diffusé.
Dans cet algorithme de jointure, shuffle ne fait pas référence à un véritable shuffle car les enregistrements avec les mêmes clés ne sont pas envoyés vers la même partition. Au lieu de cela, la partition complète des deux ensembles de données est copiée sur le réseau. Lorsque les partitions des ensembles de données sont disponibles, une jointure en boucle imbriquée est effectuée. S'il existe X un certain nombre d'enregistrements dans le premier ensemble de données et un Y certain nombre d'enregistrements dans le second ensemble de données dans chaque partition, chaque enregistrement du deuxième ensemble de données est joint à chaque enregistrement du premier ensemble de données. Cela se poursuit en X × Y boucle dans chaque partition.
