Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Options de restauration
Les sections suivantes proposent deux options de restauration de base de données pour SQL Server sur Amazon Elastic Compute Cloud (Amazon EC2), lorsque vos sauvegardes sont sur site.
Utilisation d'Amazon S3
Cette approche de restauration de base de données SQL Server utilise les commandes Amazon Simple Storage Service (Amazon S3) pour AWS Command Line Interface le AWS CLI() ou l'API Amazon S3 afin de télécharger les fichiers de sauvegarde directement dans un compartiment S3.
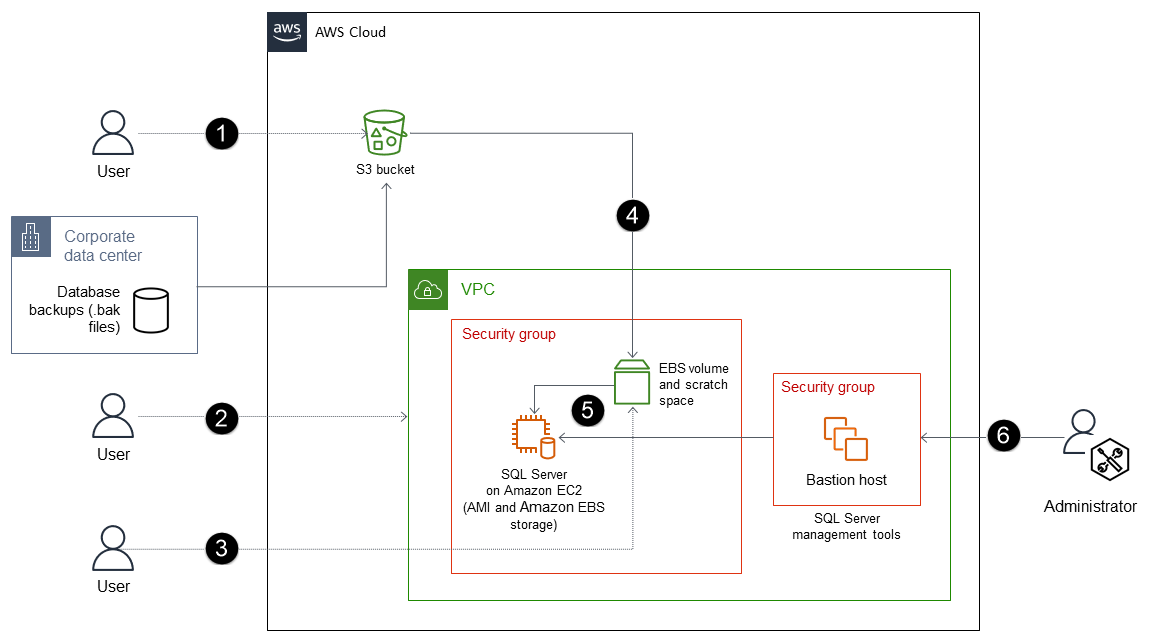
Le processus comprend les étapes suivantes :
-
Créez un compartiment S3 (ou utilisez un compartiment existant) pour stocker les fichiers de sauvegarde et transférez les fichiers de sauvegarde (.bak) de votre base de données sur site vers le compartiment S3 à l'aide de la AWS CLI ou de l'API Amazon S3.
-
Déployez SQL Server sur une EC2 instance optimisée pour EBS, à l'aide d'une Amazon Machine Image (AMI) SQL Server. Cette AMI doit contenir des volumes EBS configurés avec une partition du système d'exploitation, une partition DATA, une partition LOG, un stockage tempdb (NVMe) et un espace de travail.
-
(Facultatif) Attachez un volume EBS non root à l' EC2 instance.
-
Copiez les fichiers de sauvegarde sur le volume EBS non root.
-
Restaurez les fichiers de sauvegarde du volume EBS vers SQL Server sur l' EC2 instance.
-
Utilisez les outils de gestion de SQL Server pour gérer votre base de données.
Utilisation AWS DataSync d'Amazon FSx
Cette approche de restauration de base de données SQL Server permet de AWS DataSync transférer les fichiers de sauvegarde vers Amazon FSx pour Windows File Server.
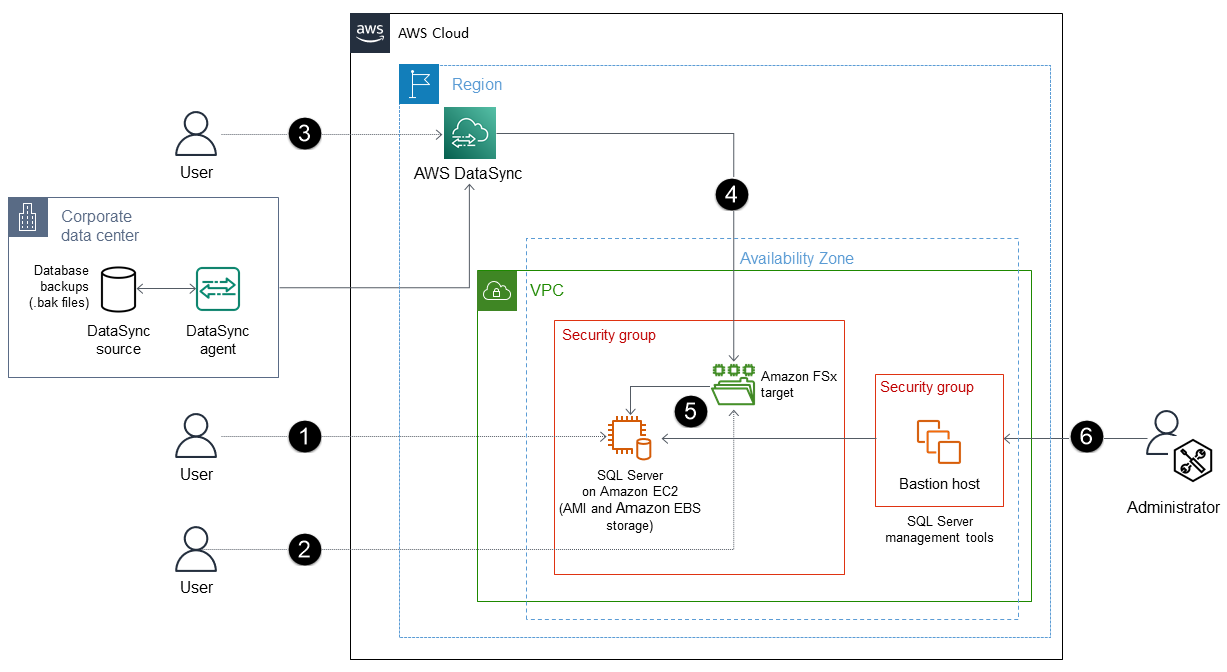
Le processus comprend les étapes suivantes :
-
Déployez SQL Server sur une EC2 instance optimisée pour EBS avec pièce jointe NVMe, à l'aide d'une AMI contenant des volumes EBS configurés avec OS, DATA, LOG et tempdb. (Par exemple, vous pouvez utiliser la classe d'
r5d.largeinstance optimisée pour la mémoire.) -
FSx À utiliser pour Windows File Server pour créer un serveur de fichiers. Il peut être utilisé comme emplacement de stockage temporaire pour télécharger des fichiers de sauvegarde SQL Server (.bak) depuis votre environnement local.
-
Créez un DataSync point de terminaison et un agent pour le serveur de FSx fichiers Amazon.
-
DataSync automatise la synchronisation des données entre votre stockage sur site et le serveur de FSx fichiers Amazon sans avoir besoin d'Amazon S3.
-
Restaurez les fichiers de sauvegarde du serveur de FSx fichiers Amazon vers SQL Server sur l' EC2instance.
-
Utilisez les outils de gestion de SQL Server pour gérer votre base de données.
Note
Amazon EC2 propose Microsoft SQL Server sur Microsoft Windows Server AMIs
Utilisation d'Amazon S3 File Gateway
Vous pouvez utiliser Amazon S3 File Gateway

Le processus comprend les étapes suivantes :
-
Les données sont écrites sur le disque de cache local de la passerelle de fichiers.
-
Une fois que les données sont conservées en toute sécurité dans le cache local, la passerelle de fichiers confirme la fin de l'opération d'écriture à l'application cliente.
-
La passerelle de fichiers transfère les données vers le compartiment S3 de manière asynchrone. Il optimise le transfert de données et utilise le protocole HTTPS pour chiffrer les données en transit.
-
Une fois les données téléchargées dans le compartiment S3, elles restent dans le cache local de la passerelle de fichiers jusqu'à ce qu'elles soient expulsées.
