Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exemple de mise en œuvre d'une stratégie moderne en matière de données de santé
AWS fournit des architectures de référence que les établissements de santé peuvent utiliser pour comprendre et créer des plateformes de données qui soutiennent une approche agile des données. L'architecture de référence suivante illustre une architecture de maillage de données
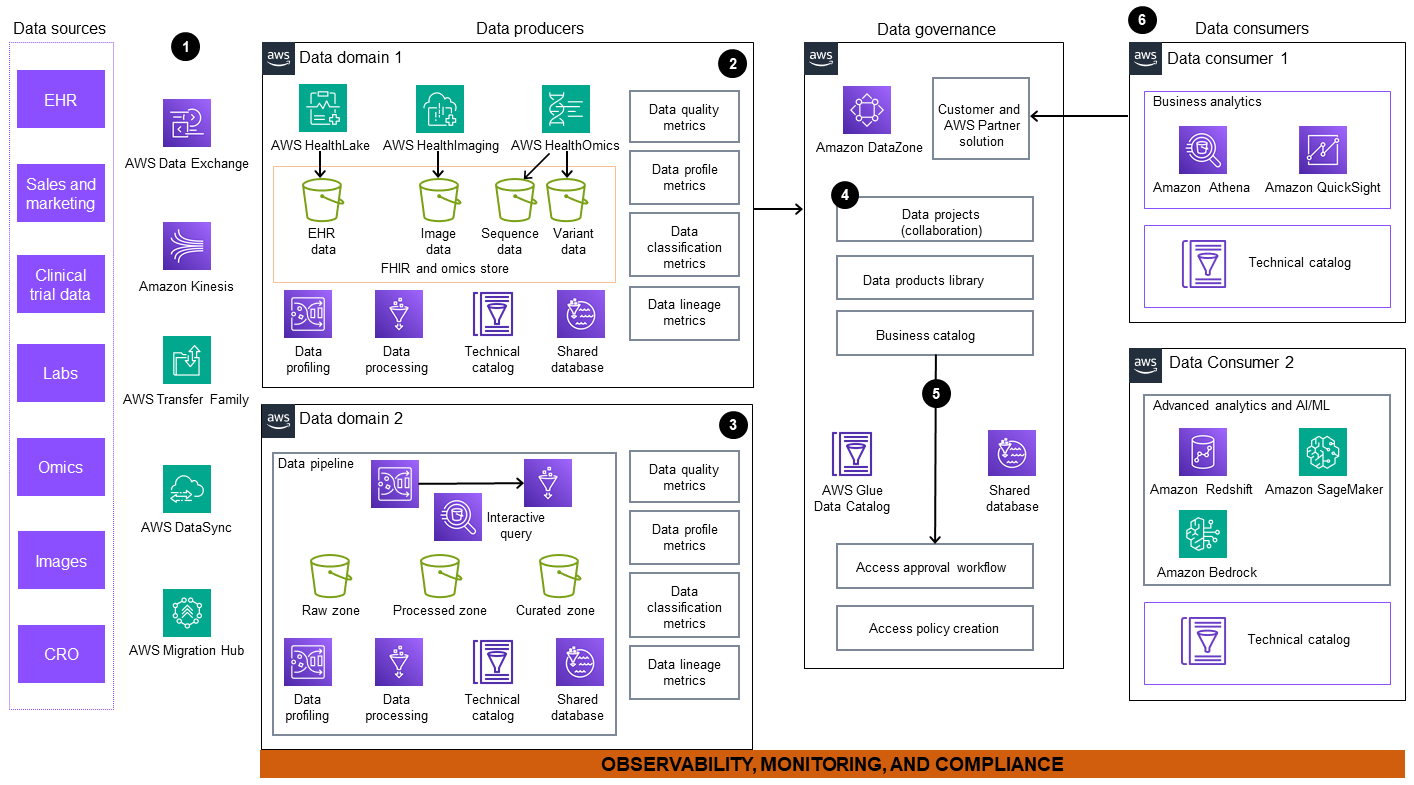
Le schéma d'architecture inclut les composants suivants :
-
Les données sont ingérées à partir de sources de données externes et internes. Ces sources incluent, sans toutefois s'y limiter, les systèmes de dossiers médicaux électroniques (EHR), les laboratoires, les installations de séquençage et les centres d'imagerie. AWS propose une suite de services tels que AWS Data Exchange
Amazon Kinesis ,,, AWS Transfer FamilyAWS DataSyncAWS Migration HubAWS HealthLake , et AWS Glue (ETL). Vous pouvez utiliser ces services pour faciliter la migration de votre ensemble de données interne et pour vous abonner à des ensembles de données internes et externes. -
Le domaine de données 1 comprend un flux de travail complet pour le traitement de données multimodales orientées vers le patient, notamment des données cliniques, omiques et d'imagerie. Les données cliniques des dossiers médicaux électroniques sont ingérées et stockées dans un magasin de HealthLake données, un service géré spécialement conçu pour les données cliniques. AWS HealthOmics
, un service spécialement conçu pour les données omiques, gère le stockage et le flux de travail des séquences et des variantes. Les données d'imagerie sont ingérées et stockées dans. AWS HealthImaging Ces données sont ensuite transformées en produits prêts à être consommés et publiées sur un marché de données d'entreprise pour une accessibilité et une utilisation étendues. -
Dans le domaine de données 2, Amazon Kinesis AWS Glue, et AWS Data Exchange ingérez des données brutes dans un pipeline de données. Les sources de données peuvent inclure les registres publics, le suivi à distance des patients et les programmes de planification des ressources d'entreprise (ERP). Le pipeline charge les données brutes dans des compartiments Amazon Simple Storage Service (Amazon S3)
. Ces données sont nettoyées, organisées, transformées et stockées pour être publiées en tant que produits de données. Amazon Athena propose un moteur de requête interactif que les producteurs de données peuvent utiliser pour transformer les données à l'aide du langage SQL. AWS Glue DataBrew fournit des fonctionnalités visuelles de transformation, de normalisation et de profilage des données. -
Amazon DataZone
gère la publication des métadonnées, des projets de données collaboratifs et de la bibliothèque de produits de données dans le catalogue commercial central. -
Un portail d'analyse de données unifié permet la collaboration autour des données en fournissant une vue des produits de données par le biais d'une gouvernance fédérée. Amazon DataZone propose un flux de travail en libre-service avec AWS Glue Data Catalog Backed by AWS Lake Formation, afin que les utilisateurs puissent partager, rechercher, découvrir des données et demander l'autorisation de les utiliser.
-
Les consommateurs de données peuvent accéder aux données, créer des vues en aval et utiliser des outils spécialement conçus tels qu'Amazon Athena, Amazon, Amazon QuickSight Redshift, Amazon SageMaker
AI et Amazon Bedrock pour effectuer les opérations suivantes : -
Analyses opérationnelles
-
Informatique clinique
-
Recherche
-
Engagement des patients et des cliniques
Les consommateurs de données peuvent également développer des applications innovantes en utilisant l'IA générative, et ils peuvent publier des produits de données dans le catalogue professionnel.
-
Pour plus d'informations sur l'architecture du maillage de données, voir Qu'est-ce qu'un maillage de données ?
IA générative
Les établissements de santé utilisent l'IA générative pour de nombreuses applications, qu'il s'agisse d'automatiser l'interprétation d'images médicales ou de générer des recommandations diagnostiques et des plans de traitement basés à la fois sur des images et des données textuelles. L'adoption de l'IA générative accélère l'innovation et améliore l'efficacité tout au long du continuum de soins. Le nouvel accent mis sur l'IA générative a contraint le secteur de la santé à étendre son champ d'action aux données pour inclure davantage de formes de données non structurées, augmentant ainsi le nombre et la variété des cas d'utilisation adaptés à l'IA. En général, les entreprises peuvent choisir parmi quatre modèles, en fonction de leur cas d'utilisation, pour mettre en œuvre des solutions d'IA générative :
-
Ingénierie rapide — Dans le cadre de l'ingénierie rapide, les utilisateurs fournissent des données pertinentes sous forme de contexte, guidant le modèle d'IA générative pour créer le contenu qu'ils souhaitent. Organisations dotées d'une stratégie moderne en matière de données de santé peuvent s'assurer que les données pertinentes sont facilement accessibles, partageables et consommables.
-
Génération augmentée par récupération (RAG) — Le modèle RAG repose sur une ingénierie rapide. Au lieu qu'un utilisateur fournisse des données pertinentes, un programme intercepte la question ou l'entrée de l'utilisateur. Le programme effectue des recherches dans un référentiel de données pour récupérer le contenu correspondant à la question ou à l'entrée. Le programme fournit les données qu'il trouve au modèle d'IA générative pour générer du contenu. Une stratégie moderne en matière de données de santé permet la curation et l'indexation des données de l'entreprise. Les données peuvent ensuite être recherchées et utilisées comme contexte pour les demandes ou les questions, aidant ainsi un grand modèle linguistique (LLM) à générer des réponses.
Votre organisation peut utiliser les deux modèles suivants pour concentrer les résultats du modèle d'IA générative sur la génération de contenu adapté au contexte de ses données.
-
Réglage précis — En utilisant ce modèle, votre organisation peut aller encore plus loin en personnalisant des modèles d'IA générative. Cela implique de peaufiner les modèles sur un petit échantillon de données spécifiques à l'organisation. La taille de l'échantillon étant petite, ce modèle fournit un équilibre entre le coût et la personnalisation. Pour éviter les biais dans les résultats du modèle, utilisez un petit échantillon de données aussi diversifié et représentatif que possible des modèles de données de votre organisation. Une stratégie moderne en matière de données de santé permet un accès efficace à une grande variété de données pour préparer les ensembles de données d'échantillons.
-
Créez votre propre modèle : si votre entreprise a besoin de générer du contenu à partir de gros volumes de données hautement spécialisés et que les trois modèles précédents ne sont pas adéquats, vous pouvez créer vos propres modèles.
Une stratégie de données moderne joue un rôle essentiel dans les solutions d'IA générative en garantissant que les données présentent les caractéristiques suivantes :
-
Des données de haute qualité pour garantir la précision
-
Données en temps réel ou quasi réel pour garantir la pertinence des résultats du modèle
-
Modalités de données multiples sur une variété de sources de données pour permettre au modèle d'accéder à des ensembles de données enrichis pour générer du contenu
Le schéma suivant montre la mise en œuvre d'une stratégie moderne de données de santé qui utilise une architecture de maillage de données pour prendre en charge les solutions d'IA génératives.
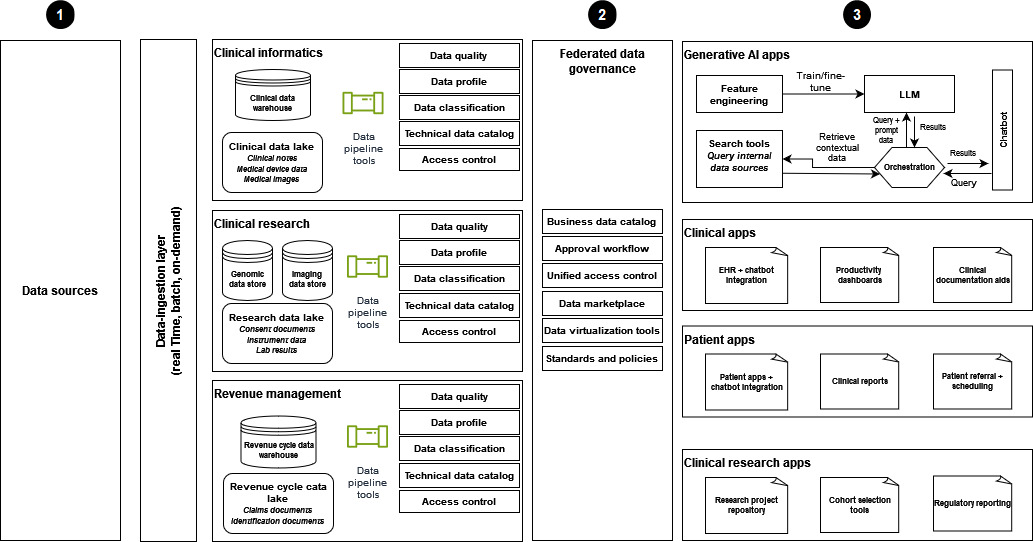
-
Les données sont ingérées à partir de diverses sources de données dans les domaines de l'informatique clinique, de la recherche clinique et de la gestion des recettes, et les données sont mises à la disposition de l'établissement de santé.
-
La gouvernance fédérée des données permet de garantir un contrôle d'accès strict pour le partage des données et un accès unifié.
-
Les consommateurs de données sont notamment les suivants :
-
Applications d'IA génératives, en particulier celles qui utilisent des données pour s'entraîner et affiner LLMs. Ces applications utilisent les données de l'entreprise pour les chatbots de questions-réponses afin d'améliorer l'efficacité opérationnelle et l'expérience des patients et des prestataires.
-
Applications cliniques équipées d'outils tels que des chatbots intégrés aux ressources humaines, des tableaux de bord de productivité et des aides à la documentation.
-
Des applications centrées sur le patient pour améliorer l'expérience des patients. Ces applications proposent des interactions avec des chatbots, des rapports cliniques et des processus de référence et de planification efficaces.
-
Recherche clinique, avec un référentiel de projets de recherche et des applications conçues pour l'analyse des cohortes et les rapports réglementaires.
-
Grâce à cette architecture, les parties prenantes de votre organisation peuvent se concentrer sur la sélection et la gestion des données qu'elles collectent auprès d'autres sources, tout en rendant leurs propres données accessibles au reste de l'organisation. Ils peuvent utiliser les outils disponibles dans la couche de gouvernance des données fédérées pour définir les métadonnées, gérer les flux de travail d'approbation des accès et définir et appliquer des politiques. En outre, la couche de gouvernance des données fédérée fournit un contrôle d'accès centralisé. Cela crée un environnement permettant de gérer diverses sources de données et d'actualiser des actifs de données de haute qualité à une fréquence spécifiée afin de maintenir leur pertinence. AWS propose un ensemble complet de fonctionnalités pour répondre à vos besoins en matière d'IA générative. Amazon Bedrock
