Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
countOver
La fonction countOver calcule le nombre d'une dimension ou mesure partitionné par une liste de dimensions.
Syntaxe
Les crochets sont obligatoires. Pour voir quels arguments sont facultatifs, consultez les descriptions suivantes.
countOver (measure or dimension field,[ partition_field, ... ],calculation level)
Arguments
- measure or dimension field
-
Mesure ou dimension pour laquelle vous souhaitez effectuer le calcul, par exemple
sum({Sales Amt}). Utilisez un regroupement si le niveau de calcul est défini surNULLouPOST_AGG_FILTER. N'utilisez pas de regroupement si le niveau de calcul est défini surPRE_FILTERouPRE_AGG. - partition field
-
(Facultatif) Une ou plusieurs mesures et dimensions selon lesquelles vous souhaitez effectuer la partition, avec séparation par des virgules.
Chaque champ de la liste est placé dans des accolades {}, s'il s'agit de plusieurs mots. La liste entière est placée entre crochets [ ].
- calculation level
-
(Facultatif) Spécifie le niveau de calcul à utiliser :
-
PRE_FILTER– Les calculs de pré-filtre sont effectués avant les filtres de jeu de données. -
PRE_AGG– Les calculs de pré-regroupement sont effectués avant d'appliquer les regroupements et les filtres N premiers/derniers aux représentations visuelles. -
POST_AGG_FILTER– (Par défaut) Les calculs de tableau sont effectués lorsque les représentations visuelles s'affichent.
La valeur par défaut est
POST_AGG_FILTERlorsqu'elle est vide. Pour de plus amples informations, veuillez consulter Utilisation de calculs basés sur les niveaux dans Amazon QuickSight. -
exemple
L'exemple suivant montre le compte de Sales partitionné sur City et State.
countOver ( Sales, [City, State] )
L'exemple suivant montre le compte de {County} partitionné sur City et State.
countOver ( {County}, [City, State] )
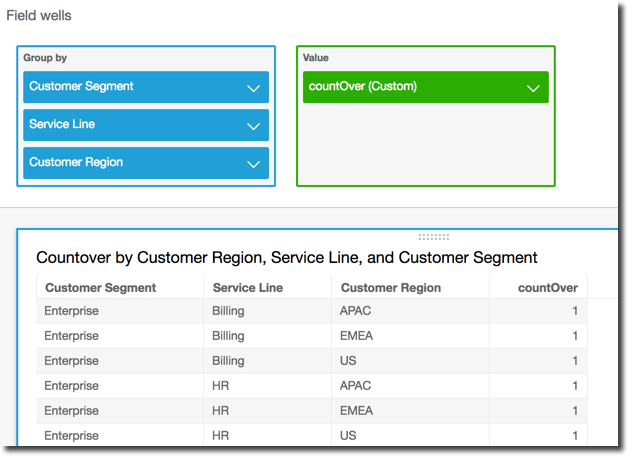
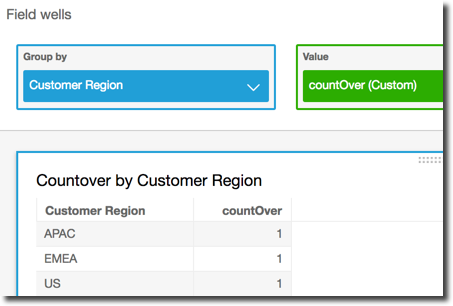
L'exemple suivant montre le compte de Billed Amount sur Customer Region. Les champs du calcul de tableau se trouvent dans les sélecteurs de champs de la représentation visuelle.
countOver ( sum({Billed Amount}), [{Customer Region}] )
La capture d'écran suivante affiche les résultats de l'exemple. Étant donné qu'il n'y a pas d'autres champs impliqués, le compte est de un pour chaque région.
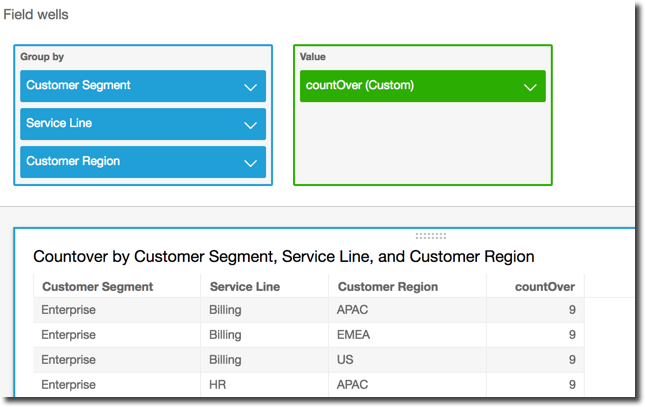
Si vous ajoutez des champs supplémentaires, le compte change. Dans la capture d'écran suivante, nous additionnons Customer Segment et Service Line. Chacun de ces champs contient trois valeurs uniques. Avec 3 segments, 3 gammes de services et 3 régions, le champ calculé affiche 9.
Si vous ajoutez les deux autres champs dans les champs de partitionnement du champ calculé, countOver( sum({Billed Amount}), [{Customer Region}, {Customer Segment},
{Service Line}], puis le décompte est à nouveau 1 pour chaque ligne.