Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
percentileDiscOver
La fonction percentileDiscOver calcule le percentile en fonction des nombres réels contenus dans measure. Elle utilise le regroupement et le tri appliqués dans les zones de champs. Le résultat est partitionné selon la dimension spécifiée au niveau de calcul spécifié. La fonction percentileOver est un alias de percentileDiscOver.
Utilisez cette fonction pour répondre à la question suivante : Quels sont les points de données réels présents dans ce percentile ? Pour renvoyer la valeur de percentile la plus proche présente dans votre jeu de données, utilisez percentileDiscOver. Pour renvoyer une valeur percentile exacte qui n'est peut-être pas présente dans votre jeu de données, utilisez plutôt percentileContOver.
Syntaxe
percentileDiscOver (measure,percentile-n, [partition-by, …] ,calculation-level)
Arguments
- measure
-
Spécifie une valeur numérique à utiliser pour calculer le percentile. L'argument doit être une mesure ou une métrique. Les valeurs NULL sont ignorées dans le calcul.
- percentile-n
-
La valeur du percentile peut être n'importe quelle constante numérique située entre 0 et 100. Une valeur de percentile de 50 calcule la valeur médiane de la mesure.
- partition-by
-
(Facultatif) Une ou plusieurs mesures et dimensions selon lesquelles vous souhaitez effectuer la partition, avec séparation par des virgules. Chaque champ de la liste est placé dans des accolades { }, s'il s'agit de plusieurs mots. La liste entière est placée entre crochets [ ].
- calculation level
-
Spécifie l'emplacement où effectuer le calcul par rapport à l'ordre d'évaluation. Trois niveaux de calcul sont pris en charge :
-
PRE_FILTER
-
PRE_AGG
-
POST_AGG_FILTER (par défaut) – Pour utiliser ce niveau de calcul, vous devez spécifier une agrégation sur
measure, par exemplesum(measure).
PRE_FILTER et PRE_AGG sont appliqués avant que l'agrégation ne se produise dans une visualisation. Pour ces deux niveaux de calcul, il est impossible de spécifier une agrégation sur
measuredans l'expression du champ calculé. Pour en savoir plus sur les niveaux de calcul et les circonstances dans lesquelles ils s'appliquent, consultez les sections Ordre d'évaluation sur Amazon QuickSight et Utilisation de calculs basés sur les niveaux dans Amazon QuickSight. -
Renvoie
Le résultat de la fonction est un nombre.
Exemple de percentileDiscOver
L'exemple suivant permet d'expliquer comment percentileDiscOver cela fonctionne.
Exemple Comparaison des niveaux de calcul pour la médiane
L'exemple suivant illustre la médiane d'une dimension (catégorie) en utilisant différents niveaux de calcul avec la fonction percentileDiscOver. Le percentile est 50. Le jeu de données est filtré par un champ de région. Le code de chaque champ calculé est le suivant :
-
example = left((Un exemple simplifié.)category, 1 ) -
pre_agg = percentileDiscOver ( {Revenue} , 50 , [ example ] , PRE_AGG) -
pre_filter = percentileDiscOver ( {Revenue} , 50 , [ example ] , PRE_FILTER) -
post_agg_filter = percentileDiscOver ( sum ( {Revenue} ) , 50 , [ example ], POST_AGG_FILTER )
example pre_filter pre_agg post_agg_filter ------------------------------------------------------ 0 106,728 119,667 4,117,579 1 102,898 95,946 2,307,547 2 97,629 92,046 554,570 3 100,867 112,585 2,709,057 4 96,416 96,649 3,598,358 5 106,293 97,296 1,875,648 6 97,118 64,395 1,320,672 7 99,915 90,557 969,807
Exemple La médiane
L'exemple suivant calcule la moyenne (le 50e percentile) de Sales, partitionnée selon City et State.
percentileDiscOver ( Sales, 50, [City, State] )
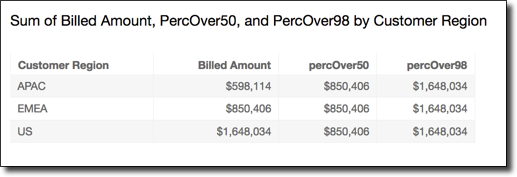
L'exemple suivant calcule le 98e percentile de sum({Billed
Amount}), partitionné selon Customer Region. Les champs du calcul de tableau se trouvent dans les sélecteurs de champs de la représentation visuelle.
percentileDiscOver ( sum({Billed Amount}), 98, [{Customer Region}] )
La capture d'écran suivante montre à quoi ressemblent ces deux exemples sur un graphique.