Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Révision des étapes du plan de requête
Vous pouvez voir les étapes dans un plan de requête en exécutant la commande EXPLAIN. L’exemple suivant présente une requête SQL et commente la sortie. En lisant le plan de requête en partant du bas, vous pouvez voir chacune des opérations logiques utilisées pour exécuter la requête. Pour de plus amples informations, veuillez consulter Création et interprétation d'un plan de requêtes.
explain select eventname, sum(pricepaid) from sales, event where sales.eventid = event.eventid group by eventname order by 2 desc;
XN Merge (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Merge Key: sum(sales.pricepaid) -> XN Network (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Send to leader -> XN Sort (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Sort Key: sum(sales.pricepaid) -> XN HashAggregate (cost=2815366577.07..2815366578.51 rows=576 width=27) -> XN Hash Join DS_BCAST_INNER (cost=109.98..2815365714.80 rows=172456 width=27) Hash Cond: ("outer".eventid = "inner".eventid) -> XN Seq Scan on sales (cost=0.00..1724.56 rows=172456 width=14) -> XN Hash (cost=87.98..87.98 rows=8798 width=21) -> XN Seq Scan on event (cost=0.00..87.98 rows=8798 width=21)
Dans le cadre de la génération d’un plan de requête, l’optimiseur de requêtes décompose le plan en flux, segments et étapes. L’optimiseur de requêtes décompose le plan pour préparer la distribution des données et de la charge de travail de requête entre les nœuds de calcul. Pour plus d’informations sur les flux, les segments et les étapes, consultez Workflow d’exécution et de planification de requête.
L’illustration suivante présente la requête précédente et le plan de requête associé. Il affiche la manière dont les opérations de requête impliquées sont mappées en étapes utilisées par Amazon Redshift pour générer du code compilé pour les tranches de nœud de calcul. Chaque opération de plan de requête correspond à plusieurs étapes dans les segments et parfois à plusieurs segments dans les flux.
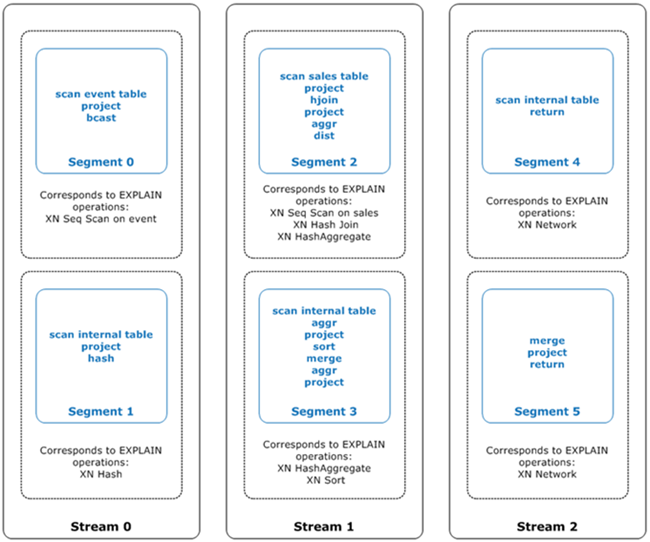
Dans cette illustration, l’optimiseur de requêtes exécute le plan de requête comme suit :
Dans
Stream 0, la requête exécuteSegment 0avec une opération d’analyse séquentielle pour analyser la tableevents. La requête passe àSegment 1avec une opération de hachage pour créer la table de hachage pour la table interne dans la jointure.Dans
Stream 1, la requête exécuteSegment 2avec une opération d’analyse séquentielle pour analyser la tablesales. Elle continue avecSegment 2et une jointure de hachage pour joindre des tables où les colonnes de jointure ne sont pas à la fois des clés de distribution et des clés de tri. Elle continue encore avecSegment 2et un agrégat de hachage pour agréger les résultats. Ensuite, la requête exécuteSegment 3avec une opération d’agrégation de hachage pour effectuer des fonctions d’agrégat groupées non triées, ainsi qu’une opération de tri pour évaluer la clause ORDER BY et d’autres opérations de tri.Dans
Stream 2, la requête exécute une opération de réseau dansSegment 4etSegment 5pour envoyer des résultats intermédiaires au nœud principal pour un traitement ultérieur.
Le dernier segment d’une requête renvoie les données. Si le jeu de retour est agrégé ou trié, les nœuds de calcul envoient chacun leur morceau du résultat intermédiaire au nœud principal. Le nœud principal fusionne ensuite les données afin que le résultat final puisse être renvoyé au client demandeur.
Pour plus d’informations sur les opérateurs EXPLAID, consultez EXPLAIN.
