Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d’informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de la vue SVL_QUERY_REPORT
Pour analyser les informations récapitulatives sur la requête par tranche à l’aide de SVL_QUERY_REPORT, procédez comme suit :
-
Exécutez la commande suivante pour déterminer l’ID de votre requête :
select query, elapsed, substring from svl_qlog order by query desc limit 5;Examinez le texte de la requête tronquée dans le champ
substringpour déterminer quelle valeur dequeryreprésente votre requête. Si vous avez exécuté la requête plusieurs fois, utilisez la valeur dequeryde la ligne avec la valeur deelapsedinférieure. Il s’agit de la ligne de la version compilée. Si vous avez exécuté un grand nombre de requêtes, vous pouvez augmenter la valeur utilisée par la clause LIMIT utilisée pour vous assurer que votre requête est incluse. -
Sélectionner des lignes dans SVL_QUERY_REPORT pour votre requête. Ordonnez les résultats par segment, par étape, par elapsed_time et par lignes :
select * from svl_query_report where query = MyQueryID order by segment, step, elapsed_time, rows; -
Pour chaque étape, vérifiez que toutes les tranches traitent à peut près le même nombre de lignes :
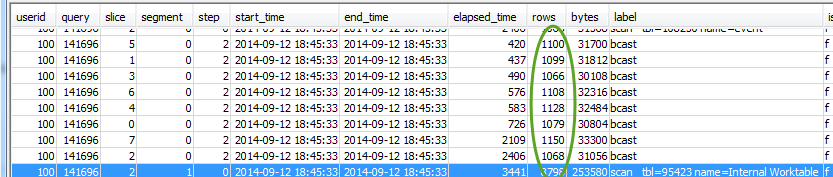
Vérifiez également que toutes les tranches prennent à peu près autant de temps :
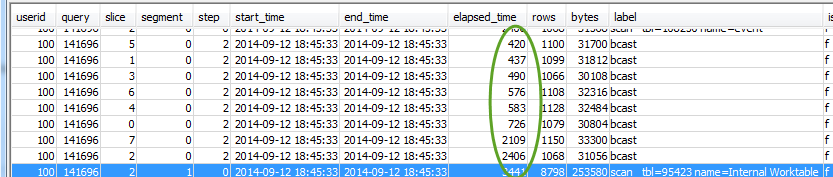
Si ces valeurs sont très différences, cela peut révéler une asymétrie de la distribution des données due à un style de distribution sous-optimal pour cette requête particulière. Pour connaître les solutions recommandées, consultez Distribution des données sous-optimales.
