Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Découvrez les concepts d'Amazon Redshift
Amazon Redshift sans serveur vous permet d’accéder aux données et de les analyser sans toutes les configurations d’un entrepôt des données provisionné. Les ressources sont automatiquement provisionnées et la capacité de l’entrepôt des données est intelligemment mise à l’échelle afin d’offrir des performances rapides, même pour les charges de travail les plus exigeantes et les plus imprévisibles. Vous ne payez pas de frais lorsque l’entrepôt des données est inactif, vous ne payez donc que ce que vous utilisez. Vous pouvez charger des données et commencer à effectuer des requêtes immédiatement dans l’éditeur de requête Amazon Redshift v2 ou dans votre outil d’informatique décisionnelle (BI) préféré. Profitez du meilleur rapport qualité/prix et des fonctionnalités SQL habituelles dans un easy-to-use environnement sans administration.
Si vous utilisez Amazon Redshift pour la première fois, nous vous recommandons de commencer par lire les sections suivantes :
-
Présentation des fonctions d'Amazon Redshift sans serveur : dans cette rubrique, vous trouverez une présentation d'Amazon Redshift sans serveur et de ses principales fonctionnalités.
-
Éléments principaux du service et prix
: sur cette page détaillée du produit, vous trouverez des détails sur les services et les prix d'Amazon Redshift sans serveur. -
Commencez avec les entrepôts de données sans serveur Amazon Redshift. — Dans cette rubrique, vous découvrirez comment créer un entrepôt de données Amazon Redshift Serverless et comment commencer à interroger des données à l'aide de l'éditeur de requêtes v2.
Si vous préférez gérer manuellement vos ressources Amazon Redshift, vous pouvez créer des clusters provisionnés pour vos besoins en matière d’interrogation de données. Pour plus d’informations, consultez Clusters Amazon Redshift.
Si votre organisation est éligible et que votre cluster est créé dans un environnement Région AWS où Amazon Redshift Serverless n'est pas disponible, vous pouvez peut-être créer un cluster dans le cadre du programme d'essai gratuit d'Amazon Redshift. Choisissez Production ou Essai gratuit pour répondre à la question Quelle est l’utilisation prévue de ce cluster ? Lorsque vous choisissez Essai gratuit, vous créez une configuration avec le type de nœud dc2.large. Pour plus d’informations sur le choix d’un essai gratuit, accédez à Essai gratuit d’Amazon Redshift
Vous trouverez ci-après quelques concepts clés d'Amazon Redshift sans serveur.
-
Espace de noms : collection d'objets et d'utilisateurs de la base de données. Les espaces noms regroupent toutes les ressources que vous utilisez dans Amazon Redshift sans serveur, telles que les schémas, les tables, les utilisateurs, les unités de partage des données et les instantanés.
-
Groupe de travail : une collection de ressources informatiques. Les groupes de travail hébergent des ressources de calcul qu'Amazon Redshift sans serveur utilise pour exécuter des tâches de calcul. Ces ressources incluent notamment les unités de traitement Redshift (RPUs), les groupes de sécurité et les limites d'utilisation. Les groupes de travail disposent de paramètres réseau et de sécurité que vous pouvez configurer à l'aide de la console Amazon Redshift Serverless, AWS Command Line Interface du ou d'Amazon Redshift Serverless. APIs
Pour plus d'informations sur la configuration des ressources des espaces noms et des groupes de travail, consultez Utilisation des espaces noms et Utilisation des groupes de travail.
Vous trouverez ci-dessous quelques concepts clés des clusters Amazon Redshift provisionnés :
-
Cluster : le composant principal de l'infrastructure d'un entrepôt des données Amazon Redshift est un cluster.
Un cluster est composé d’un ou plusieurs nœuds de calcul. Les nœuds de calcul exécutent le code compilé.
Si un cluster est alloué avec deux nœuds de calcul ou plus, un nœud principal supplémentaire coordonne les nœuds de calcul. Le nœud principal gère la communication externe avec des applications, telles que les outils de business intelligence et les éditeurs de requêtes. Votre application cliente n’interagit directement qu’avec le nœud principal. Les nœuds de calcul sont transparents pour les applications externes.
-
Base de données : un cluster contient une ou plusieurs bases de données.
Les données utilisateur sont stockées dans une ou plusieurs bases de données sur les nœuds de calcul. Votre client SQL communique avec le nœud principal, qui à son tour coordonne l'exécution des requêtes avec les nœuds de calcul. Pour plus de détails sur les nœuds principaux et les nœuds de calcul, veuillez consulter Architecture système de l'entrepôt de données. Dans une base de données, les données utilisateur sont organisées en un ou plusieurs schémas.
Amazon Redshift est un système de gestion de base de données relationnelle (SGBDR), compatible de ce fait avec d'autres applications SGBDR. Il fournit les mêmes fonctionnalités qu'un SGBDR classique, y compris les fonctions de traitement transactionnel en ligne (OLTP) comme l'insertion et la suppression de données. Amazon Redshift est également optimisé pour l'analyse par lots hautes performances et la création de rapports de jeux de données très volumineux.
Vous trouverez ci-dessous une description du flux de traitement des données typique dans Amazon Redshift, ainsi que des descriptions des différentes parties du flux. Pour plus d'informations sur l'architecture système Amazon Redshift, veuillez consulter Architecture système de l'entrepôt de données.
Le diagramme suivant illustre un flux de traitement des données standard dans Amazon Redshift.
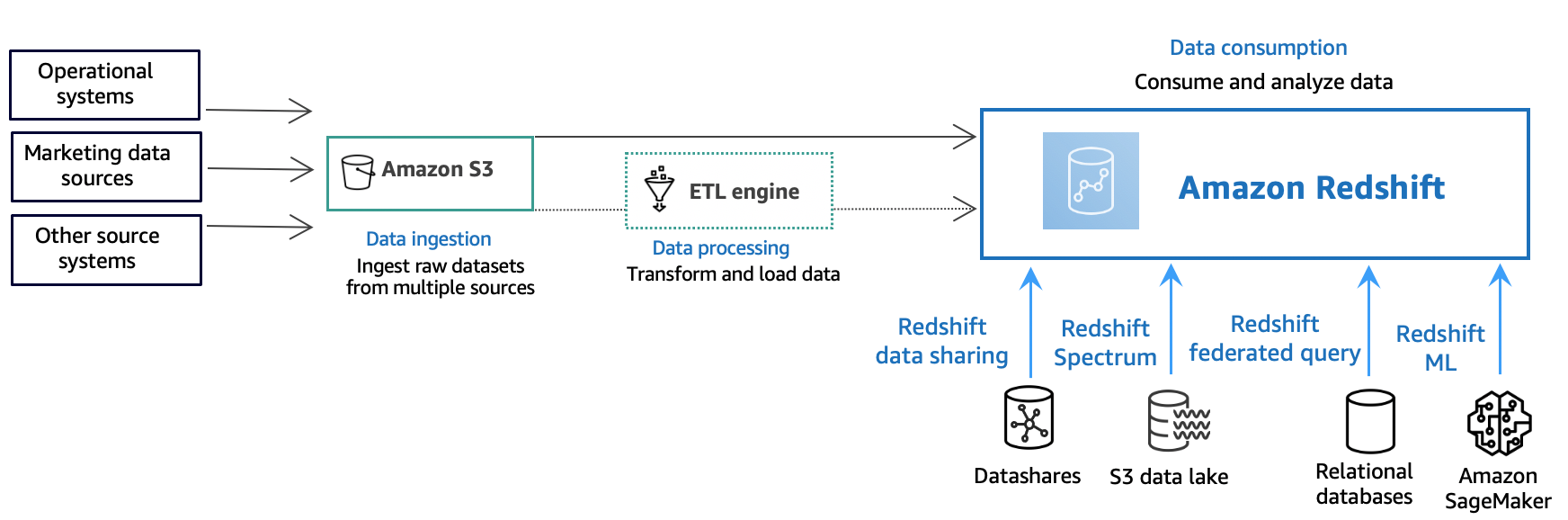
Un entrepôt des données Amazon Redshift est un système de gestion et de requête de base de données relationnelle de niveau entreprise. Amazon Redshift prend en charge les connexions client avec de nombreux types d’applications, notamment les outils de business intelligence (BI), de reporting, de données et d’analytique. Lorsque vous exécutez des requêtes analytiques, vous extrayez, comparez et évaluez de grandes quantités de données dans le cadre d’opérations à plusieurs étapes, afin d’obtenir un résultat final.
Au niveau de la couche d'ingestion de données, différents types de sources de données téléchargent en permanence des données structurées, semi-structurées ou non structurées vers la couche de stockage des données. Cette zone de stockage de données sert de zone de transit qui stocke les données dans différents états de préparation à la consommation. Un compartiment Amazon Simple Storage Service (Amazon S3) peut être un exemple de stockage.
Au niveau de la couche de traitement des données facultative, les données source passent par le prétraitement, la validation et la transformation à l'aide de pipelines d'extraction, de transformation, de chargement (ETL) ou d'extraction, de chargement, de transformation (ELT). Ces jeux de données bruts sont ensuite affinés à l'aide d'opérations ETL. Un exemple de moteur ETL est AWS Glue.
Au niveau de la couche de consommation des données, les données sont chargées dans votre cluster Amazon Redshift, où vous pouvez exécuter des charges de travail analytiques.
Pour des exemples de charges de travail analytiques, consultez Interroger des sources de données externes.
