Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Affichage des données de performances de cluster
En utilisant les métriques de cluster dans Amazon Redshift, vous pouvez effectuer les tâches de performance communes suivantes :
-
Déterminer si les métriques de cluster sont anormales au-dessus d’une durée spécifiée et, si tel est le cas, identifier les requêtes responsables de cette augmentation.
-
Vérifier si les requêtes historiques ou actuelles ont un impact sur les performances de cluster. SI vous identifiez une requête problématique, vous pouvez en consulter les détails, y compris les performances du cluster pendant l’exécution de la requête. Vous pouvez utiliser ces informations pour diagnostiquer la lenteur de la requête et voir ce qu’il est possible de faire pour en améliorer les performances.
Pour consulter les données de performances
-
Connectez-vous à la console Amazon Redshift AWS Management Console et ouvrez-la à l'adresse. https://console.aws.amazon.com/redshiftv2/
-
Dans le menu de navigation, choisissez Clusters, puis choisissez le nom d’un cluster dans la liste pour ouvrir ses détails. Les détails du cluster sont affichés, ce qui peut inclure les onglets Performance du cluster, Surveillance des requêtes, Bases de données, Datashares, Planifications, Maintenance et Propriétés.
-
Choisissez l’onglet Performance de cluster pour obtenir des informations sur la performance, notamment les suivantes :
-
Utilisation de l’UC
-
Pourcentage d’espace disque utilisé
-
Connexions de la base de données
-
État de santé
-
Durée de requête
-
Débit de requête
-
Activité de mise à l’échelle de simultanéité
De nombreuses autres métriques sont disponibles. Pour voir les métriques disponibles et choisir celles qui sont affichées, choisissez l’icône Préférences.
-
Graphiques de performances de cluster
Les exemples suivants illustrent certains des graphiques affichés dans la nouvelle console Amazon Redshift.
-
Utilisation du CPU – Indique le pourcentage d’utilisation du CPU pour tous les nœuds (principal et calcul). Pour trouver une heure où l’utilisation du cluster est la plus faible avant de planifier la migration du cluster ou d’autres opérations consommant des ressources, surveillez ce graphique pour voir l’utilisation de l’UC par individu ou tous les nœuds.

-
Mode maintenance – Indique si le cluster est en mode maintenance à un moment donné à l’aide des indicateurs
OnetOff. Vous pouvez voir l’heure à laquelle le cluster est en cours de maintenance. Vous pouvez ensuite mettre en corrélation cette fois avec les opérations effectuées sur le cluster afin d’estimer ses temps d’arrêt futurs pour les événements récurrents.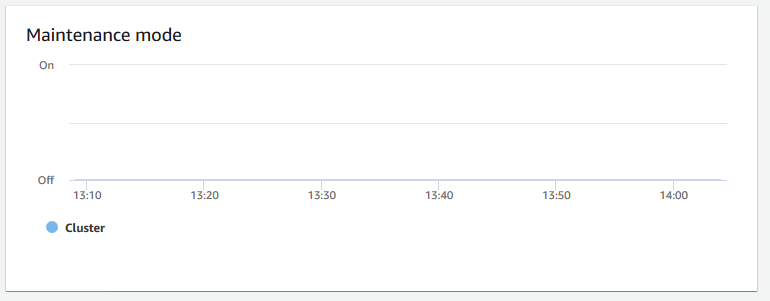
-
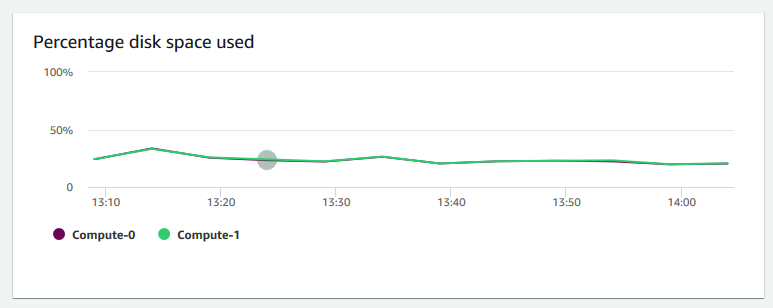
Pourcentage d’espace disque utilisé – Indique le pourcentage d’utilisation de l’espace disque pour chaque nœud de calcul, et non pour le cluster dans son ensemble. Vous pouvez explorer ce graphique pour surveiller l’utilisation du disque. Les opérations de maintenance telles que VACUUM et COPY utilisent un espace de stockage temporaire intermédiaire pour leurs opérations de tri, ce qui entraîne généralement un pic d’utilisation du disque.
-
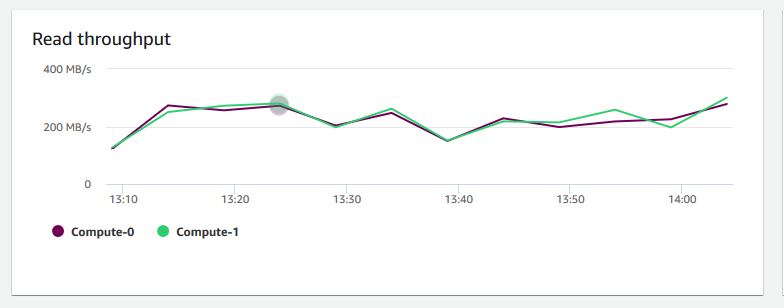
Débit de lecture – Indique le nombre moyen de mégaoctets lus sur le disque par seconde. Vous pouvez évaluer ce graphique pour surveiller l’aspect physique correspondant du cluster. Ce débit n’inclut pas le trafic réseau entre les instances du cluster et le volume de cluster.
-
Latence de lecture : indique le temps moyen nécessaire aux I/O opérations de lecture du disque par milliseconde. Vous pouvez afficher les temps de réponse pour que les données reviennent. Lorsque la latence est élevée, cela signifie que l’expéditeur passe plus de temps inactif (sans envoyer de nouveaux paquets), ce qui réduit la vitesse de croissance du débit.

-
Débit d’écriture – Indique le nombre moyen de mégaoctets écrits sur le disque par seconde. Vous pouvez évaluer cette métrique pour surveiller l’aspect physique correspondant du cluster. Ce débit n’inclut pas le trafic réseau entre les instances du cluster et le volume de cluster.
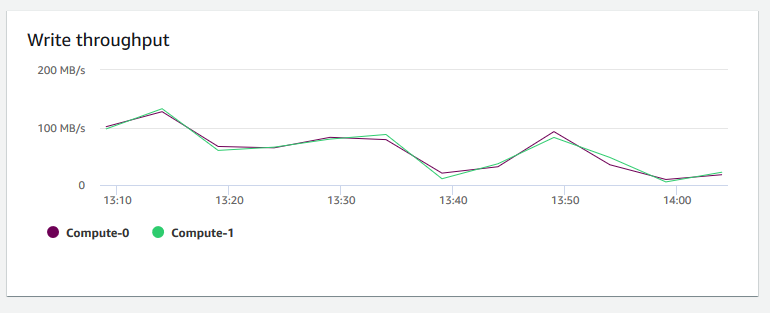
-
Latence d'écriture : indique le temps moyen, en millisecondes, nécessaire aux opérations d'écriture sur disque. I/O Vous pouvez évaluer le temps de retour de l’accusé de réception d’écriture. Lorsque la latence est élevée, cela signifie que l’expéditeur passe plus de temps inactif (sans envoyer de nouveaux paquets), ce qui réduit la vitesse de croissance du débit.

-
Connexions à la base de données – Indique le nombre de connexions à la base de données d’un cluster. Vous pouvez utiliser ce graphique pour voir le nombre de connexions établies à la base de données et trouver une heure où l’utilisation du cluster est la plus faible.

-
Nombre total de tables – Indique le nombre de tables utilisateur ouvertes à un moment donné dans un cluster. Vous pouvez surveiller les performances du cluster lorsque le nombre de tables ouvertes est élevé.
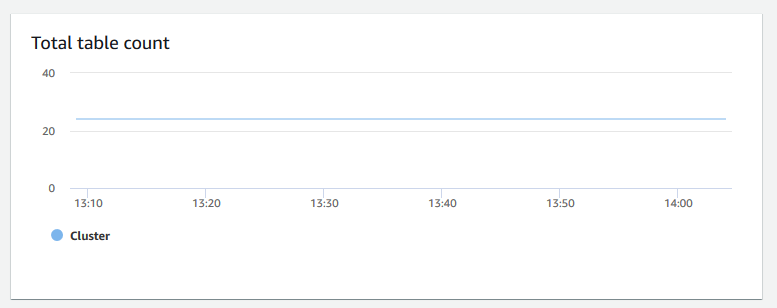
-
État d’intégrité – Indique l’état d’intégrité du cluster comme
HealthyouUnhealthy. Si le cluster peut se connecter à sa base de données et exécuter une requête simple avec succès, le cluster est considéré comme sain. Sinon, le cluster est défectueux. Un état défectueux peut se produire lorsque la base de données du cluster subit une très lourde charge ou s’il y a un problème de configuration avec une base de données du cluster.
-
Durée de la requête – Indique la durée moyenne d’exécution d’une requête en microsecondes. Vous pouvez comparer les données de ce graphique pour mesurer les I/O performances au sein du cluster et ajuster ses requêtes les plus chronophages si nécessaire.

-
Débit des requêtes – Indique le nombre moyen de requêtes terminées par seconde. Vous pouvez analyser les données de ce graphique pour mesurer les performances de la base de données et caractériser la capacité du système à traiter une charge de travail multiutilisateur de manière équilibrée.

-
Durée de la requête par file d’attente WLM – Indique la durée moyenne d’exécution d’une requête en microsecondes. Vous pouvez comparer les données de ce graphique pour mesurer les I/O performances par file d'attente WLM et ajuster les requêtes les plus chronophages si nécessaire.
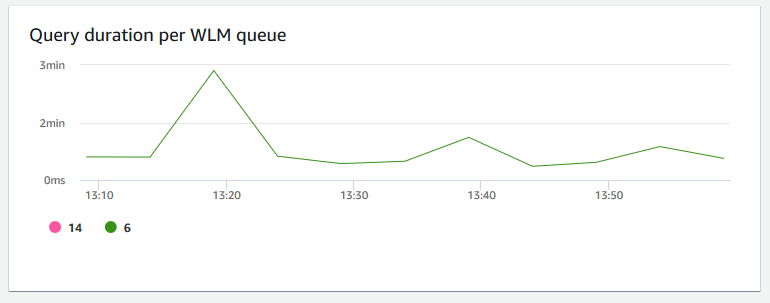
-
Débit de requêtes par file d’attente WLM – Indique le nombre moyen de requêtes terminées par seconde. Vous pouvez analyser les données de ce graphique pour mesurer les performances de base de données par file d’attente WLM.
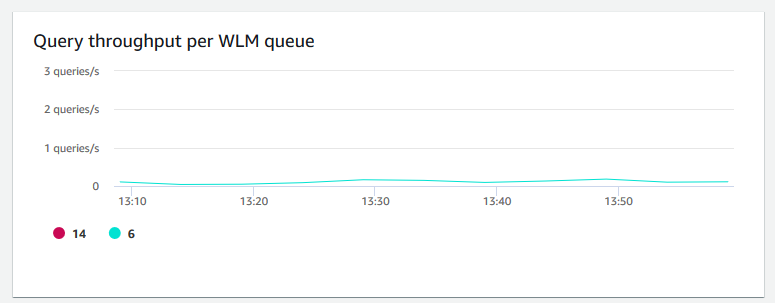
-
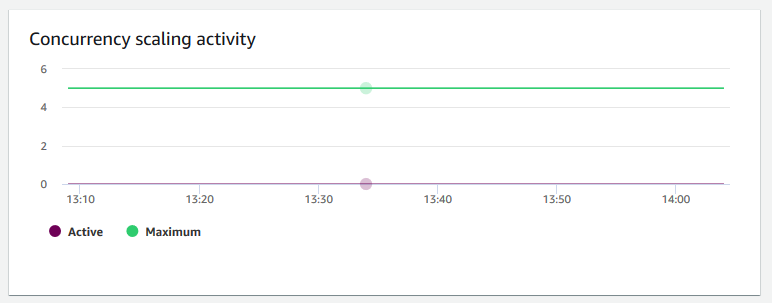
Activité de mise à l’échelle de la simultanéité – Indique le nombre de clusters de mise à l’échelle de la simultanéité. Lorsque la mise à l’échelle de la simultanéité est activée, Amazon Redshift ajoute automatiquement de la capacité de cluster supplémentaire lorsque vous en avez besoin pour traiter une augmentation des requêtes de lecture simultanées.