Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migration à partir d'un cluster provisionné vers Amazon Redshift Serverless
Vous pouvez migrer vos clusters provisionnés existants vers Amazon Redshift Serverless, ce qui permet une mise à l'échelle automatique et à la demande des ressources de calcul. La migration d'un cluster provisionné vers Amazon Redshift Serverless vous permet d'optimiser les coûts en ne payant que pour les ressources que vous utilisez et en dimensionnant automatiquement la capacité en fonction des demandes de charge de travail. Les cas d'utilisation courants de la migration incluent l'exécution de requêtes ad hoc, de tâches de traitement de données périodiques ou la gestion de charges de travail imprévisibles sans surprovisionner les ressources. Effectuez les tâches suivantes pour migrer votre cluster Amazon Redshift provisionné vers l'option de déploiement sans serveur.
Création d’un instantané de votre cluster provisionné
Note
Amazon Redshift convertit automatiquement les clés entrelacées en clés composées lorsque vous restaurez un instantané de cluster provisionné dans un espace de noms sans serveur.
Pour transférer des données de votre cluster provisionné vers Amazon Redshift sans serveur, créez un instantané de votre cluster provisionné, puis restaurez l’instantané dans Amazon Redshift sans serveur.
Note
Avant de migrer vos données vers un groupe de travail sans serveur, vérifiez que les besoins de votre cluster provisionné sont compatibles avec la quantité de RPU que vous choisissez dans Amazon Redshift Serverless.
Pour créer un instantané de votre cluster provisionné
Connectez-vous à la console Amazon Redshift AWS Management Console et ouvrez-la à l'adresse. https://console.aws.amazon.com/redshiftv2/
-
Dans le menu de navigation, choisissez Clusters, Snapshots (Instantanés), puis choisissez l’onglet Create snapshot (Créer un instantané).
-
Entrez les propriétés de la définition de l’instantané, puis choisissez Create snapshot (Créer un instantané). L’instantané n’est pas toujours disponible immédiatement.
Pour restaurer un instantané de cluster provisionné dans un espace de noms sans serveur :
Connectez-vous à la console Amazon Redshift AWS Management Console et ouvrez-la à l'adresse. https://console.aws.amazon.com/redshiftv2/
-
Démarrez la console de cluster provisionné Amazon Redshift et accédez à Clusters, sur la page Snapshots (Instantanés).
-
Choisissez un instantané à utiliser.
-
Choisissez Restore snapshot (Restaurer un instantané), Restore to serverless namespace (Restaurer vers un espace de noms sans serveur).
-
Choisissez un espace de noms dans lequel restaurer votre instantané.
-
Confirmez que vous souhaitez effectuer une restauration à partir de votre instantané. Cette action remplace toutes les bases de données de votre point de terminaison sans serveur par les données de votre cluster alloué. Choisissez Restore (Restaurer).
Pour plus d’informations sur les instantanés de cluster provisionnés, consultez Instantanées Amazon Redshift.
Connexion à Amazon Redshift sans serveur à l’aide d’un pilote
Pour vous connecter à Amazon Redshift Serverless avec votre client SQL préféré, vous pouvez utiliser la version 2.x du pilote JDBC fourni par Amazon Redshift. Nous vous recommandons de vous connecter à Amazon Redshift à l'aide de la dernière version du pilote Amazon Redshift JDBC version 2.x. Le numéro de port est facultatif. Si vous ne l’incluez pas, Amazon Redshift sans serveur utilise par défaut le numéro de port 5439. Vous pouvez passer à un autre port dans la plage de ports 5431-5455 ou 8191-8215. Pour modifier le port par défaut d'un point de terminaison sans serveur, utilisez l'API AWS CLI et Amazon Redshift.
Pour connaître le point de terminaison exact à utiliser pour le pilote JDBC, ODBC ou Python, consultez Configuration du groupe de travail dans Amazon Redshift sans serveur. Vous pouvez également utiliser l'opération d'API Amazon Redshift Serverless GetWorkgroup ou l' AWS CLI opération get-workgroups pour renvoyer des informations sur votre groupe de travail, puis vous connecter.
Connexion à l’aide d’une authentification par mot de passe
Pour établir une connexion à l'aide du pilote Amazon Redshift JDBC version 2.x avec authentification par mot de passe, utilisez la syntaxe suivante :
jdbc:redshift://<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com:5439/?username=username&password=password
Pour établir une connexion à l'aide du connecteur Amazon Redshift Python avec authentification par mot de passe, utilisez la syntaxe suivante :
import redshift_connector with redshift_connector.connect( host='<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com', database='<database-name>', user='username', password='password' # port value of 5439 is specified by default ) as conn: pass
Pour établir une connexion à l'aide du pilote ODBC Amazon Redshift version 2.x avec authentification par mot de passe, utilisez la syntaxe suivante :
Driver={Amazon Redshift ODBC Driver (x64)}; Server=<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com; Database=database-name; User=username; Password=password
Connexion à l’aide d’IAM
Si vous préférez vous connecter avec IAM, utilisez l'opération d'API Amazon Redshift GetCredentialsServerless.
Pour utiliser l'authentification IAM, iam: ajoutez-la à l'URL Amazon Redshift JDBC jdbc:redshift: ci-dessous, comme indiqué dans l'exemple suivant.
jdbc:redshift:iam://<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com:5439/<database-name>
Ce point de terminaison Amazon Redshift Serverless ne prend pas en charge la personnalisation de DBUser, DBGroup ou la création automatique. Par défaut, le pilote crée automatiquement les utilisateurs de la base de données lors de la connexion. Il affecte ensuite les utilisateurs aux rôles de base de données Amazon Redshift en fonction des balises spécifiées dans IAM ou des groupes définis dans votre fournisseur d'identité (IdP).
Assurez-vous que votre AWS identité dispose de la politique IAM appropriée pour l'redshift-serverless:GetCredentialsaction. Voici un exemple de politique IAM qui accorde les autorisations appropriées à une AWS identité pour se connecter à Amazon Redshift Serverless. Pour plus d'informations sur les autorisations IAM, consultez la section Ajouter et supprimer des autorisations d'identité IAM dans le guide de l'utilisateur IAM.
Pour établir une connexion à l'aide du connecteur Amazon Redshift Python avec une authentification basée sur IAM, utilisez-le iam=true dans votre code, comme indiqué dans la syntaxe suivante :
import redshift_connector with redshift_connector.connect( iam=True, host='<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com', database='<database-name>' <IAM credentials> ) as conn: pass
En effetIAM credentials, vous pouvez utiliser toutes les informations d'identification, y compris les suivantes :
-
AWS configuration du profil.
-
Informations d'identification IAM (un identifiant de clé d'accès, une clé d'accès secrète et éventuellement un jeton de session).
-
Fédération des fournisseurs d'identité.
Pour établir une connexion à l'aide du pilote ODBC Amazon Redshift version 2.x avec une authentification basée sur IAM et un profil, utilisez la syntaxe suivante :
Driver={Amazon Redshift ODBC Driver (x64)}; IAM=true; Server=<workgroup-name>.<account-number>.<aws-region>.redshift-serverless.amazonaws.com; Database=database-name; Profile=aws-profile-name;
Connexion à l'aide d'IAM avec l'API GetClusterCredentials
Note
Lorsque vous vous connectez à Amazon Redshift Serverless, nous vous recommandons d'utiliser l'API. GetCredentials Cette API offre une fonctionnalité complète de contrôle d'accès basé sur les rôles (RBAC) ainsi que d'autres nouvelles fonctionnalités qui ne sont pas disponibles dans. GetClusterCredentials Nous prenons en charge l'GetClusterCredentialsAPI afin de simplifier la transition entre les clusters provisionnés et les groupes de travail sans serveur, mais nous vous recommandons vivement de migrer vers Using GetCredentials dès que possible pour une compatibilité optimale.
Vous pouvez établir une connexion à Amazon Redshift Serverless à l'aide de l'API. GetClusterCredentials Pour implémenter cette méthode d'authentification, modifiez votre client ou votre application en incorporant les paramètres suivants :
iam=trueclusterid/cluster_identifier=redshift-serverless-<workgroup-name>region=<aws-region>
Les exemples suivants illustrent le plug-in BrowserSAML sur les trois pilotes. Cela représente l'une des nombreuses approches d'authentification disponibles. Les exemples peuvent être modifiés pour utiliser des méthodes d'authentification ou des plugins alternatifs en fonction de vos besoins spécifiques.
Autorisations de politique IAM pour GetClusterCredentials
Voici un exemple de politique IAM avec les autorisations requises pour être utilisée GetClusterCredentials avec Amazon Redshift Serverless :
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "redshift:CreateClusterUser", "redshift:JoinGroup", "redshift:GetClusterCredentials", "redshift:ExecuteQuery", "redshift:FetchResults", "redshift:DescribeClusters", "redshift:DescribeTable" ], "Resource": [ "arn:aws:redshift:us-east-1:<account-id>:cluster:redshift-serverless-<workgroup-name>", "arn:aws:redshift:us-east-1:<account-id>:dbgroup:redshift-serverless-<workgroup-name>", "arn:aws:redshift:us-east-1:<account-id>:dbname:redshift-serverless-<workgroup-name>/${redshift:DbName}", "arn:aws:redshift:us-east-1:<account-id>:dbuser:redshift-serverless-<workgroup-name>/${redshift:DbUser}" ] } ] }
Pour établir une connexion à l'aide du pilote Amazon Redshift JDBC version 2.x avecGetClusterCredentials, utilisez la syntaxe suivante :
jdbc:redshift:iam://redshift-serverless-<workgroup-name>:<aws-region>/<database-name>?plugin_name=com.amazon.redshift.plugin.BrowserSamlCredentialsProvider&login_url=<single sign-on URL from IdP>"
Pour établir une connexion à l'aide du connecteur Python Amazon Redshift avecGetClusterCredentials, utilisez la syntaxe suivante :
import redshift_connector with redshift_connector.connect( iam=True, cluster_identifier='redshift-serverless-<workgroup-name>', region='<aws-region>', database='<database-name>', credentials_provider='BrowserSamlCredentialsProvider' login_url='<single sign-on URL from IdP>' # port value of 5439 is specified by default ) as conn: pass
Pour établir une connexion à l'aide du pilote ODBC Amazon Redshift version 2.x avecGetClusterCredentials, utilisez la syntaxe suivante :
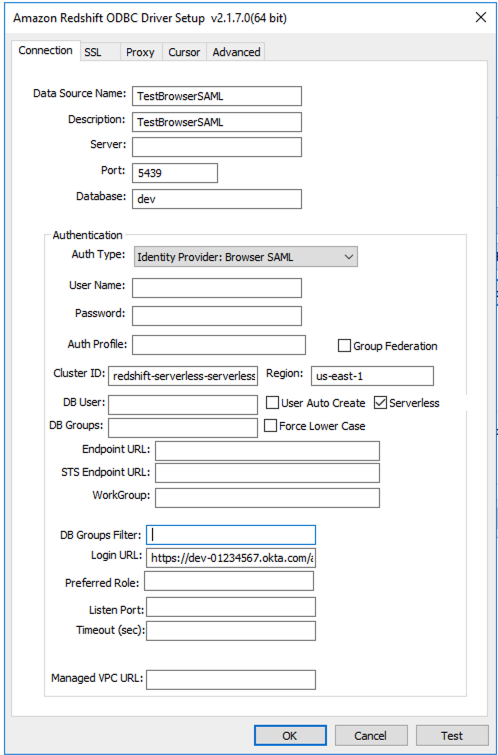
Driver= {Amazon Redshift ODBC Driver (x64)}; IAM=true; isServerless=true; ClusterId=redshift-serverless-<workgroup-name>; region=<aws-region>; plugin_name=BrowserSAML;login_url=<single sign-on URL from IdP>
Voici un exemple de configuration DSN ODBC sous Windows :
Utilisation du kit SDK Amazon Redshift sans serveur
Si vous avez écrit des scripts de gestion à l’aide du kit SDK Amazon Redshift, vous devez utiliser le nouveau kit SDK Amazon Redshift sans serveur pour gérer Amazon Redshift sans serveur et les ressources associées. Pour plus d’informations sur les opérations d’API disponibles, consultez le guide de référence de l’API de données Amazon Redshift sans serveur.
