Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Rapport d'exploration des données du pilote automatique
Amazon SageMaker Autopilot nettoie et prétraite automatiquement votre ensemble de données. La qualité élevée des données améliore l'efficacité du machine learning et produit des modèles dont les prédictions sont plus précises.
Il existe des problèmes avec des jeux de données fournis par le client qui ne peuvent pas être résolus automatiquement sans une certaine connaissance du domaine. Par exemples, les valeurs aberrantes importantes dans la colonne cible pour les problèmes de régression peuvent entraîner des prédictions sous-optimales pour les valeurs non aberrantes. Certaines valeurs aberrantes doivent être supprimées selon l'objectif de modélisation. Si une colonne cible est incluse par accident comme l'une des ressources d'entrée, le modèle final sera bien validé, mais n'aura que peu de valeur pour les prédictions à venir.
Pour aider les clients à déceler ce genre de problèmes, Autopilot fournit un rapport d'exploration des données qui contient des informations sur les problèmes potentiels de leurs données. Le rapport suggère également la manière de traiter les problèmes.
Un bloc-notes d'exploration de données contenant le rapport est généré pour chaque tâche Autopilot. Le rapport est stocké dans un compartiment S3 et est accessible depuis votre chemin de sortie. Le chemin du rapport d'exploration de données correspond généralement au schéma suivant.
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMaker AIAutopilotDataExplorationNotebook.ipynb
L'emplacement du carnet d'exploration des données peut être obtenu à partir de l'API Autopilot à l'aide de la réponse à l'DescribeAutoMLJobopération, qui est stockée dans. DataExplorationNotebookLocation
Lorsque vous exécutez le pilote automatique depuis SageMaker Studio Classic, vous pouvez ouvrir le rapport d'exploration des données en procédant comme suit :
-
Cliquez sur l'icône Accueil dans le volet
 de navigation de gauche pour afficher le menu de navigation supérieur d'Amazon SageMaker Studio Classic.
de navigation de gauche pour afficher le menu de navigation supérieur d'Amazon SageMaker Studio Classic. -
Sélectionnez la carte AutoML dans la zone de travail principale. Ceci ouvre un nouvel onglet Autopilot.
-
Dans la section Name (Nom), sélectionnez la tâche Autopilot qui contient le bloc-notes d'exploration des données que vous souhaitez examiner. Ceci ouvre un nouvel onglet de Tâche Autopilot.
-
Sélectionnez Open data exploration notebook (Ouvrir le bloc-notes d'exploration de données) dans la section supérieure droite de l'onglet Autopilot job (Tâche Autopilot).
Le rapport d'exploration de données est généré à partir de vos données avant le début du processus d'entraînement. Cela vous permet d'arrêter les tâches Autopilot susceptibles d'entraîner des résultats dénués de sens. De même, vous pouvez résoudre l'ensemble des problèmes ou améliorations liés à votre jeu de données avant de réexécuter Autopilot. Vous pouvez ainsi utiliser savoir-faire dans votre domaine pour améliorer manuellement la qualité des données avant d'entraîner un modèle sur un jeu de données mieux organisé.
Le rapport de données ne contient qu'une syntaxe statique et peut être ouvert dans n'importe quel environnement Jupyter. Le bloc-notes contenant le rapport peut être converti en d'autres formats, tels que PDF ou HTML. Pour en savoir plus sur les conversions, veuillez consulter la section Utilisation du script nbconvert pour convertir les blocs-notes Jupyter vers d'autres formats
Rubriques
Récapitulatif du jeu de données
Ce Dataset Summary (Récapitulatif du jeu de données) fournit des statistiques clés caractérisant votre jeu de données, notamment le nombre de lignes, le nombre de colonnes, le pourcentage de lignes dupliquées et les valeurs cibles manquantes. Il est destiné à vous fournir une alerte rapide en cas de problème avec votre ensemble de données détecté par Amazon SageMaker Autopilot et susceptible de nécessiter votre intervention. Ces informations sont présentées sous forme d'avertissements classés comme étant de gravité « élevée » ou « faible ». La classification dépend du niveau de confiance dans le fait que le problème aura un impact négatif sur la performance du modèle.
Les informations sur la gravité élevée et faible apparaissent dans le résumé sous forme de fenêtres contextuelles. Dans la plupart des cas, des recommandations sont proposées pour confirmer qu'il existe un problème avec le jeu de données qui requiert votre attention. Des propositions sont également formulées sur la manière de résoudre les problèmes.
Autopilot fournit d'autres statistiques sur les valeurs cibles manquantes ou non valides dans notre jeu de données pour vous aider à détecter d'autres problèmes qui peuvent ne pas être détectés par des informations de gravité élevée. Un nombre inattendu de colonnes d'un type particulier peut indiquer que certaines colonnes que vous souhaitez utiliser sont peut-être absentes du jeu de données. Cela pourrait également indiquer qu'il y a eu un problème dans la façon dont les données ont été préparées ou stockées. La résolution de ces problèmes de données portés à votre attention par Autopilot peut améliorer les performances des modèles de machine learning entraînés sur vos données.
Les informations de gravité élevée sont présentés dans la section récapitulative et dans d'autres sections pertinentes du rapport. Des exemples d'informations de gravité élevée et faible sont généralement donnés en fonction de la section du rapport de données.
Analyse de la cible
Diverses informations de gravité élevée et faible sont présentées dans cette section concernant la distribution des valeurs dans la colonne cible. Vérifiez que la colonne cible contient les bonnes valeurs. Des valeurs incorrectes dans la colonne cible donneront probablement lieu à un modèle de machine learning qui ne servira pas l'objectif commercial visé. Plusieurs informations de données de gravité élevée et faible figurent dans cette section. Voici quelques exemples.
-
Valeurs cibles aberrantes : distribution des cibles asymétriques ou inhabituelles pour la régression, comme les cibles à ailes lourdes.
-
High or low target cardinality (Cardinalité de cible élevée ou faible) : nombre peu fréquent d'étiquettes de classe ou grand nombre de classes uniques pour la classification.
Pour les types de problèmes de régression et de classification, des valeurs non valides telles que l'infinité numérique, NaN ou un espace vide apparaissent dans la colonne cible. Selon le type de problème, différentes statistiques de jeux de données sont présentées. Une distribution de valeurs de colonne cible pour un problème de régression vous permet de vérifier si la distribution correspond à vos attentes.
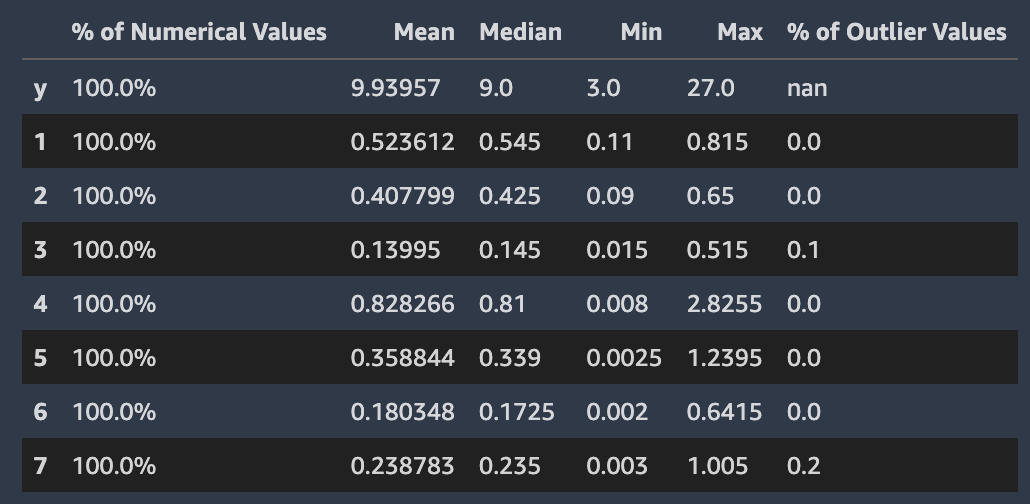
La capture d'écran suivante montre un rapport de données Autopilot, qui inclut des statistiques telles que la moyenne, la médiane, le minimum, le maximum et le pourcentage de valeurs aberrantes dans votre jeu de données. La capture d'écran inclut également un histogramme montrant la distribution des étiquettes dans la colonne cible. L'histogramme montre Target Column Values (Valeurs de colonne cible) sur l'axe horizontal et Count (Nombre) sur l'axe vertical. Un encadré met en évidence la section Outliers Percentage (Pourcentage de valeurs aberrantes) de la capture d'écran pour indiquer où cette statistique apparaît.
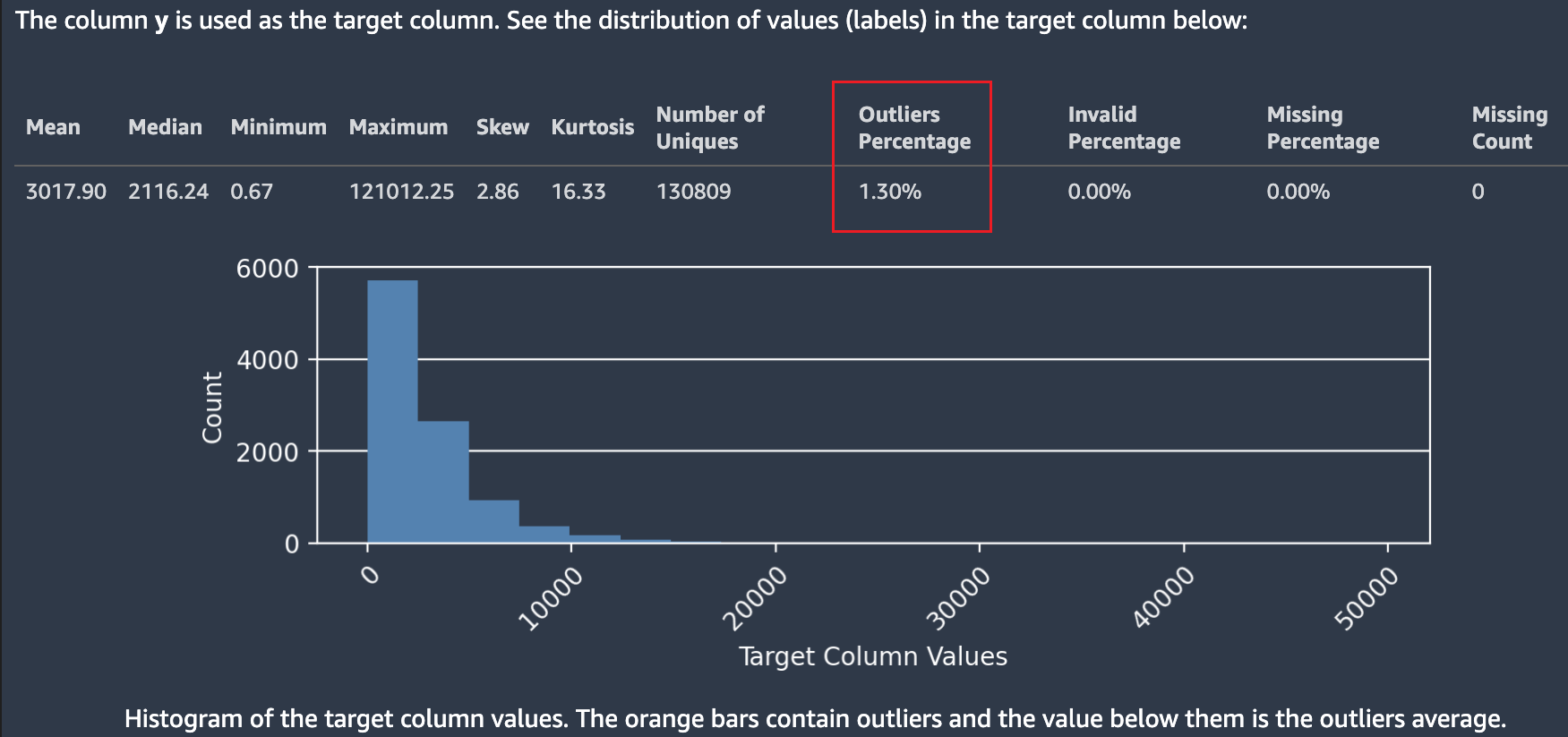
Plusieurs statistiques sont affichées concernant les valeurs cibles et leur distribution. Si l'une des valeurs aberrantes, des valeurs non valides ou des pourcentages manquants est supérieure à zéro, ces valeurs sont mises en évidence afin que vous puissiez étudier pourquoi vos données contiennent des valeurs cibles inutilisables. Certaines valeurs cibles inutilisables sont mises en évidence par un avertissement de faible gravité.
Dans la capture d'écran suivante, un symbole ` a été ajouté par erreur à la colonne cible, ce qui a empêché l'analyse de la valeur numérique de la cible. Un avertissement Low severity insight: "Invalid target values" (Information de faible gravité : « Valeurs cibles non valides ») s'affiche. Dans cet exemple, l'avertissement indique que « 0,14 % des étiquettes de la colonne cible n'ont pas pu être converties en valeurs numériques. Les valeurs non numériques les plus courantes sont : [« -3,8e-05 »,« -9-05 »,« -4,7e-05 »,« -1,4999999999999999e-05 »,« -4,3e-05 »]. Cela indique généralement qu'il existe des problèmes de collecte ou de traitement des données. Amazon SageMaker Autopilot ignore toutes les observations dont l'étiquette cible n'est pas valide. »

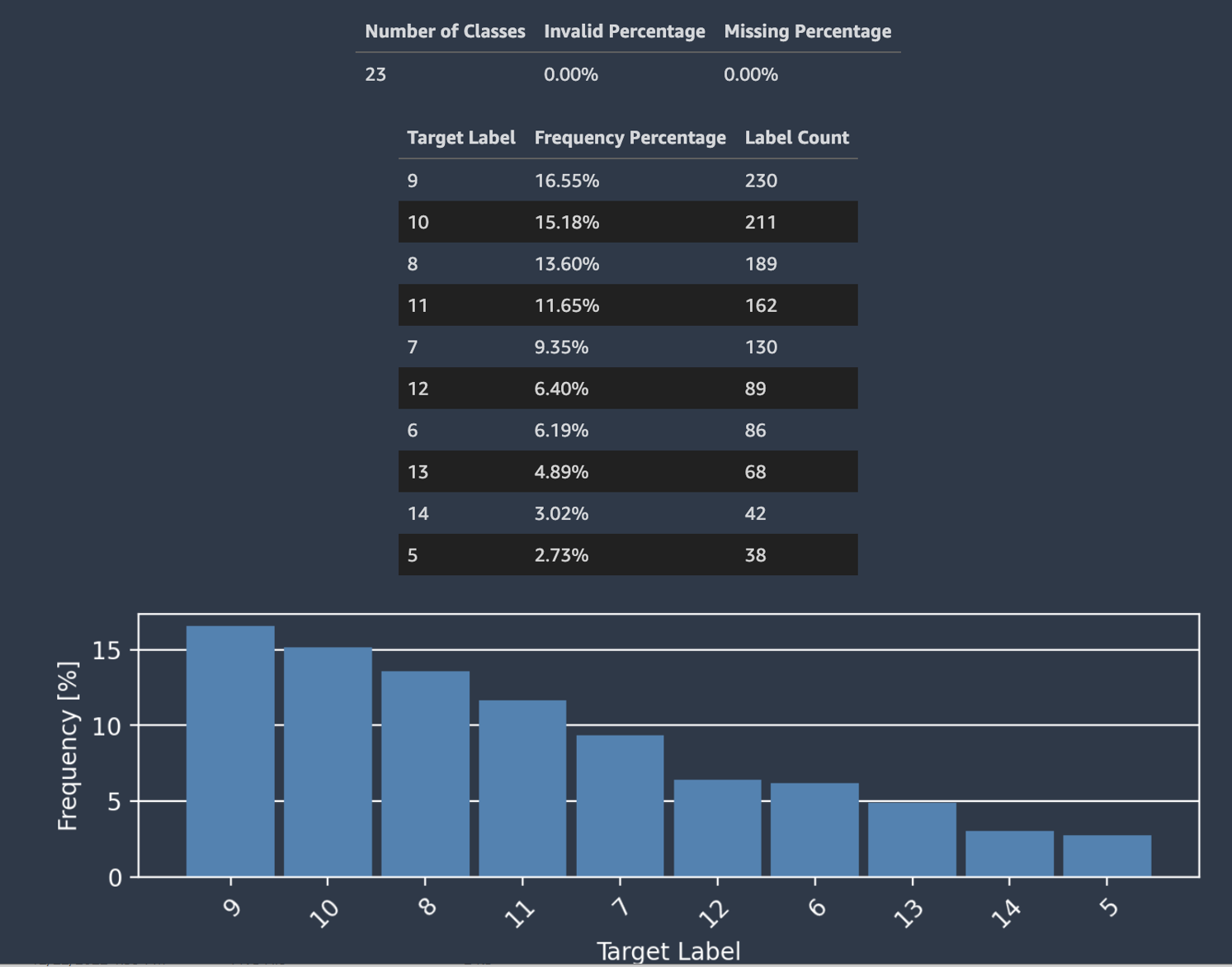
Autopilot fournit également un histogramme indiquant la distribution des étiquettes à des fins de classification.
La capture d'écran suivante montre un exemple de statistiques fournies pour votre colonne cible, notamment le nombre de classes, les valeurs manquantes ou non valides. Un histogramme avec Target Label (Étiquette cible) sur l'axe horizontal et Frequency (Fréquence) sur l'axe vertical montre la distribution de chaque catégorie d'étiquettes.
Note
Vous trouverez des définitions de tous les termes présentés dans cette section et dans d'autres sections dans la section Definitions (Définitions) au bas du bloc-notes du rapport.
Échantillon de données
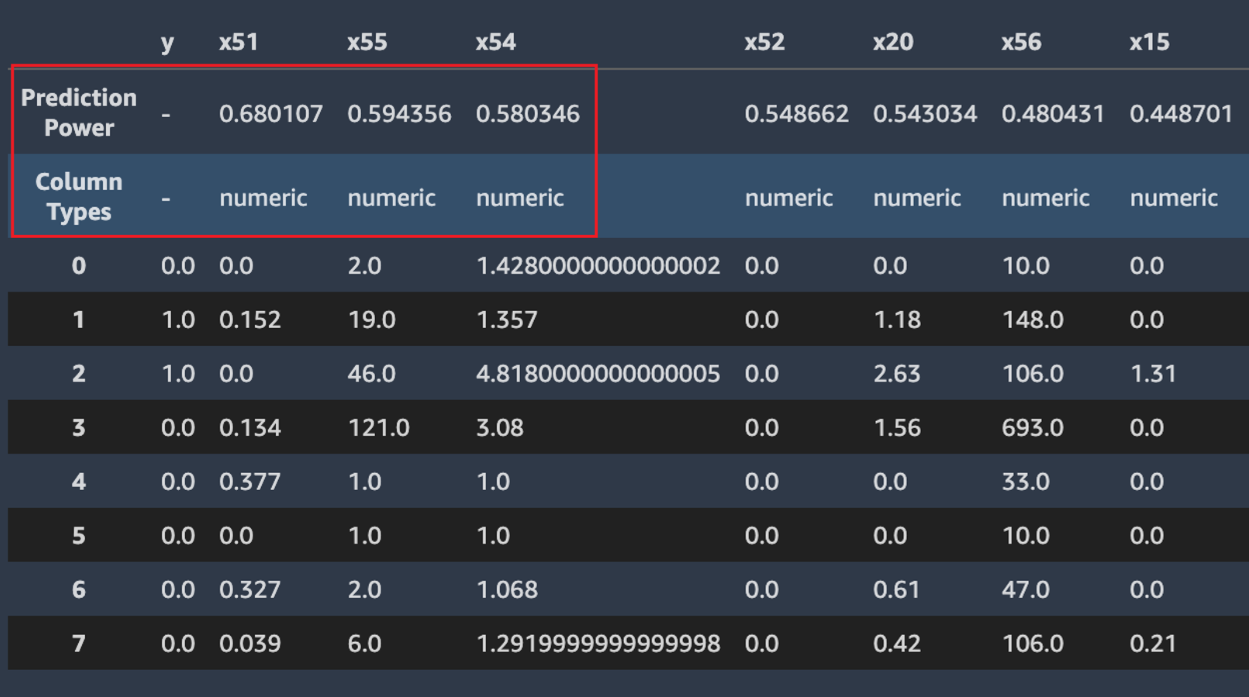
Autopilot présente un échantillon réel de vos données pour vous aider à identifier les problèmes liés à votre jeu de données. La table d'échantillon défile horizontalement. Inspectez les données de l'échantillon pour vérifier que toutes les colonnes nécessaires sont présentes dans le jeu de données.
Autopilot calcule également une mesure du pouvoir prédictif, qui peut être utilisée pour identifier une relation linéaire ou non linéaire entre une caractéristique et la variable cible. La valeur 0 indique que la caractéristique n'a aucune valeur prédictive dans la prédiction de la variable cible. La valeur 1 indique le pouvoir prédictif le plus élevé pour la variable cible. Pour plus d'informations sur le pouvoir prédictif, consultez la section Definitions (Définitions).
Note
Il n'est pas recommandé d'utiliser le pouvoir prédictif comme substitut à l'importance d'une caractéristique. Ne l'utilisez que si vous êtes certain que le pouvoir prédictif est une mesure appropriée pour votre cas d'utilisation.
La capture d'écran suivante montre un exemple d'échantillon de données. La ligne du haut contient le pouvoir prédictif de chaque colonne dans votre jeu de données. La deuxième ligne contient le type de données de colonne. Les lignes suivantes contiennent les étiquettes. Les colonnes contiennent la colonne cible suivie de chaque colonne de caractéristique. Un pouvoir prédictif est associé à chaque colonne de caractéristique, encadré dans cette capture d'écran. Dans cet exemple, la colonne contenant la caractéristique x51 a un pouvoir prédictif de 0.68 pour la variable cible y. La caractéristique x55 est légèrement moins prédictive avec un pouvoir prédictif de 0.59.
Lignes dupliquées.
Si des lignes dupliquées sont présentes dans l'ensemble de données, Amazon SageMaker Autopilot en affiche un échantillon.
Note
Il n'est pas recommandé d'équilibrer un jeu de données par sur-échantillonnage avant de le fournir à Autopilot. Cela peut entraîner des scores de validation inexacts pour les modèles entraînés par Autopilot, et les modèles produits peuvent être inutilisables.
Corrélations croisées de colonnes
Autopilot utilise le coefficient de corrélation de Pearson, une mesure de la corrélation linéaire entre deux caractéristiques, pour remplir une matrice de corrélation. Dans cette matrice de corrélation, les caractéristiques numériques sont tracées sur les axes horizontal et vertical, avec le coefficient de corrélation de Pearson tracé à leurs intersections. Plus la corrélation entre deux caractéristiques est élevée, plus le coefficient est élevé, avec une valeur maximale de |1|.
-
La valeur
-1indique que les caractéristiques présente une parfaite corrélation négative. -
La valeur
1, qui apparaît lorsqu'une caractéristique est corrélée à elle-même, indique une parfaite corrélation positive.
Vous pouvez utiliser les informations de la matrice de corrélation pour supprimer les caractéristiques fortement corrélées. Un nombre réduit de ressources diminue les risques de surajustement d'un modèle et peut baisser les coûts de production de deux manières. Cela raccourcit le temps d'exécution d'Autopilot et, pour certaines applications, peut réduire le coût des procédures de collecte de données.
La capture d'écran suivante montre un exemple de matrice de corrélation entre 7 caractéristiques. Chaque caractéristique est affichée dans une matrice sur les axes horizontal et vertical. Le coefficient de corrélation de Pearson est affiché à l'intersection de deux caractéristiques. Une tonalité de couleur est associée à chaque intersection de caractéristiques. Plus la corrélation est élevée, plus la tonalité est foncée. Les tonalités les plus foncées occupent la diagonale de la matrice, où chaque caractéristique est corrélée à elle-même, ce qui représente une parfaite corrélation.

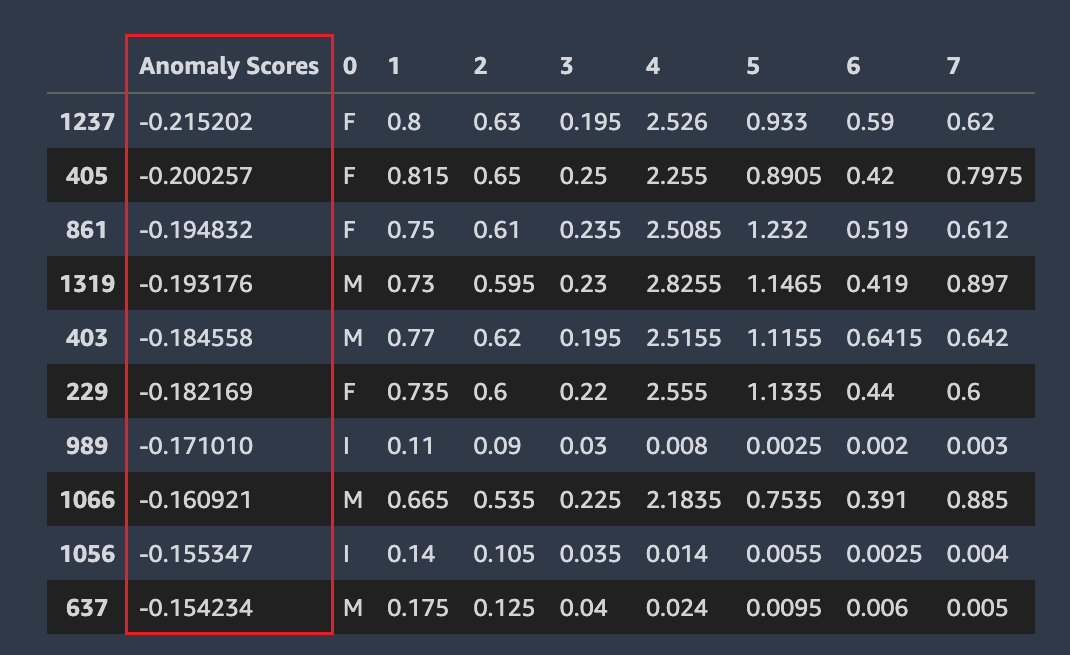
Lignes anormales
Amazon SageMaker Autopilot détecte les lignes de votre ensemble de données susceptibles de présenter des anomalies. Il attribue ensuite un score d'anomalie à chaque ligne. Les lignes présentant un score d'anomalie négatif sont considérées comme anormales.
La capture d'écran suivante montre le résultat d'une analyse Autopilot pour les lignes contenant des anomalies. Une colonne contenant un score anormal apparaît à côté des colonnes du jeu de données pour chaque ligne.
Valeurs manquantes, cardinalité et statistiques descriptives
Amazon SageMaker Autopilot examine et génère des rapports sur les propriétés des différentes colonnes de votre ensemble de données. Dans chaque section du rapport de données qui présente cette analyse, le contenu est classé dans l'ordre. Cela vous permet de vérifier en priorité les valeurs les plus « suspectes ». Grâce à ces statistiques, vous pouvez améliorer le contenu des colonnes individuelles et améliorer la qualité du modèle produit par Autopilot.
Autopilot calcule plusieurs statistiques sur les valeurs catégoriques des colonnes qui les contiennent. Celles-ci incluent notamment le nombre d'entrées uniques et, pour le texte, le nombre de mots uniques.
Autopilot calcule plusieurs statistiques standard sur les valeurs numériques des colonnes qui les contiennent. L'image suivante illustre ces statistiques, notamment les valeurs moyennes, médianes, minimales et maximales, ainsi que les pourcentages de types numériques et de valeurs aberrantes.