Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Effectuer des prédictions pour les données de texte
Les procédures suivantes expliquent comment effectuer des prédictions uniques ou par lots pour les jeux de données de texte. Chaque Ready-to-use modèle prend en charge à la fois les prédictions simples et les prédictions par lots pour votre ensemble de données. Une prédiction unique est lorsque vous n'avez besoin d'effectuer qu'une seule prédiction. Par exemple, vous avez une image dont vous souhaitez extraire du texte ou un paragraphe de texte dont vous souhaitez détecter la langue dominante. Une prédiction par lots est lorsque vous souhaitez effectuer des prédictions pour un jeu de données complet. Par exemple, vous pouvez disposer d'un fichier CSV d'avis clients pour lequel vous souhaitez analyser le sentiment des clients, ou vous pouvez avoir des fichiers images dans lesquels vous souhaitez détecter des objets.
Vous pouvez utiliser ces procédures pour les types de Ready-to-use modèles suivants : analyse des sentiments, extraction d'entités, détection de langue et détection d'informations personnelles.
Note
Pour l'analyse de sentiment, vous ne pouvez utiliser que des textes en anglais.
Prédictions uniques
Pour effectuer une prédiction unique pour les Ready-to-use modèles qui acceptent des données texte, procédez comme suit :
-
Dans le volet de navigation de gauche de l'application Canvas, sélectionnez R eady-to-use models.
-
Sur la page Ready-to-use des modèles, choisissez le Ready-to-use modèle correspondant à votre cas d'utilisation. Pour les données de texte, il doit s'agir de l'un des modèles suivants : Analyse de sentiment, Extraction d'entités, Détection de la langue ou Détection d'informations personnelles.
-
Sur la page Exécuter les prédictions pour le Ready-to-use modèle que vous avez choisi, sélectionnez Prédiction unique.
-
Pour Champ de texte, entrez le texte pour lequel vous souhaitez obtenir une prédiction.
-
Choisissez Générer les résultats de prédiction pour obtenir votre prédiction.
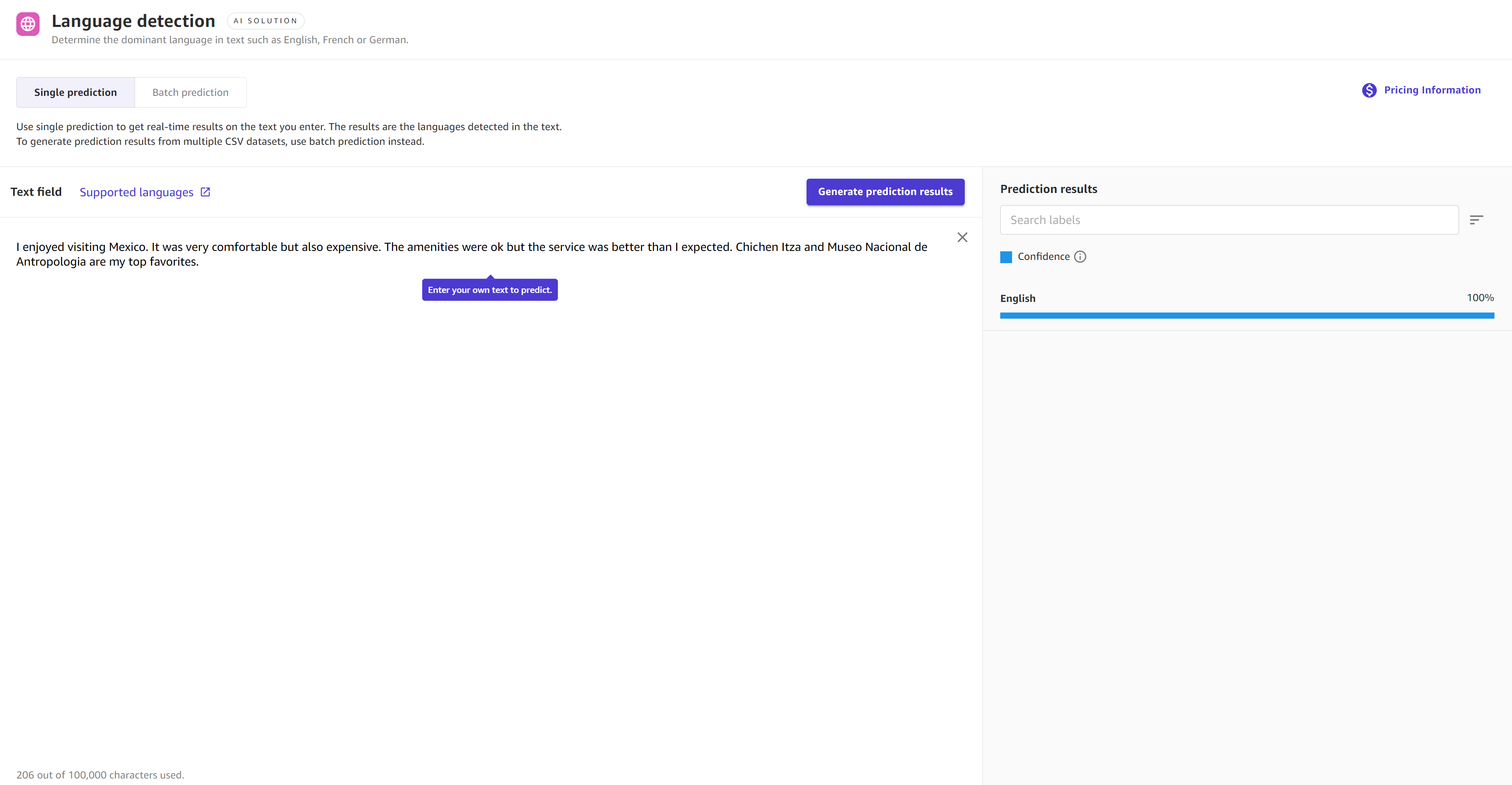
Dans le volet droit Résultats de prédiction, vous recevez une analyse de votre texte et un score de Confiance pour chaque résultat ou étiquette. Par exemple, si vous avez choisi la détection de langue et que vous avez entré un passage de texte en français, vous pourriez obtenir un score de confiance de 95 % pour le français et un score de confiance de 5 % pour des traces d'autres langues, comme l'anglais.
La capture d'écran suivante illustre les résultats d'une prédiction unique utilisant la détection de la langue où le modèle est sûr à 100 % que le passage est en anglais.
Des prédictions par lots
Pour effectuer des prédictions par lots pour les Ready-to-use modèles qui acceptent des données texte, procédez comme suit :
-
Dans le volet de navigation de gauche de l'application Canvas, sélectionnez R eady-to-use models.
-
Sur la page Ready-to-use des modèles, choisissez le Ready-to-use modèle correspondant à votre cas d'utilisation. Pour les données de texte, il doit s'agir de l'un des modèles suivants : Analyse de sentiment, Extraction d'entités, Détection de la langue ou Détection d'informations personnelles.
-
Sur la page Exécuter les prédictions pour le Ready-to-use modèle que vous avez choisi, sélectionnez Prédiction par lots.
-
Choisissez Sélectionner un jeu de données si vous avez déjà importé votre jeu de données. Si ce n'est pas le cas, choisissez Importer un nouveau jeu de données. Vous êtes ensuite dirigé vers le flux de travail d'importation de données.
-
Dans la liste des jeux de données disponibles, sélectionnez votre jeu de données et choisissez Générer des prédictions pour obtenir vos prédictions.
Une fois la tâche de prédiction terminée, sur la page Exécuter les prédictions, vous pouvez voir un jeu de données en sortie répertorié sous Prédictions. Ce jeu de données contient vos résultats, et si vous sélectionnez l'icône Plus d'options (
![]() ), vous pouvez prévisualiser les données de sortie. Ensuite, vous pouvez choisir Télécharger pour télécharger les résultats.
), vous pouvez prévisualiser les données de sortie. Ensuite, vous pouvez choisir Télécharger pour télécharger les résultats.
