Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Valeurs de Shapley asymétriques
La solution d'explication du modèle de prévision des séries chronologiques SageMaker Clarify est une méthode d'attribution de fonctionnalités ancrée dans la théorie des jeux coopératifs
Contexte
L'objectif est de calculer les attributions des entités en entrée pour un modèle de prévision donné f. Le modèle de prévision prend les entrées suivantes :
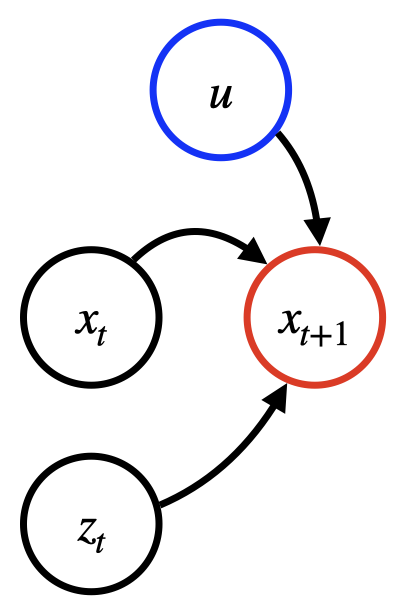
Séries chronologiques passées (TS cible). Par exemple, il peut s'agir d'anciens passagers quotidiens sur le trajet Paris-Berlin, indiqué par x. t
(Facultatif) Une série chronologique à covariables. Par exemple, il peut s'agir de fêtes et de données météorologiques, désignées par z t ou R S. Lorsqu'elle est utilisée, la covariable TS peut être disponible uniquement pour les étapes passées ou également pour les étapes futures (incluses dans le calendrier des fêtes).
(Facultatif) Covariables statiques, telles que la qualité de service (comme la première ou la deuxième classe), désignées par u ou R E.
Les covariables statiques, les covariables dynamiques ou les deux peuvent être omises, selon le scénario d'application spécifique. Étant donné un horizon de prévision K ≥ 0 (par exemple K = 30 jours), la prédiction du modèle peut être caractérisée par la formule suivante : f (x[1:T], z[1:T+K], u) = x. [T+1:T +K+1]
Le schéma suivant montre une structure de dépendance pour un modèle de prévision classique. La prédiction à l'instant t+1 dépend des trois types d'entrées mentionnés précédemment.
Méthode
Les explications sont calculées en interrogeant le modèle de série chronologique f sur une série de points dérivés de l'entrée d'origine. En suivant les constructions de la théorie des jeux, Clarify fait la moyenne des différences entre les prédictions en obfusquant (c'est-à-dire en fixant une valeur de référence) de manière itérative à certaines parties des entrées. La structure temporelle peut être parcourue dans un ordre chronologique ou antichronologique, ou les deux. Les explications chronologiques sont élaborées en ajoutant de manière itérative des informations à partir de la première étape, tandis qu'elles sont antichronologiques à partir de la dernière étape. Ce dernier mode peut être plus approprié en présence d'un biais de récence, par exemple lors de la prévision des cours des actions. L'une des propriétés importantes des explications calculées est que leur somme correspond à la sortie du modèle d'origine si le modèle fournit des sorties déterministes.
Attributions résultantes
Les attributions qui en résultent sont des scores qui marquent les contributions individuelles d'étapes temporelles spécifiques ou de caractéristiques d'entrée à la prévision finale à chaque étape de prévision. Clarify propose les deux granularités suivantes pour les explications :
Les explications temporelles sont peu coûteuses et ne fournissent que des informations sur des étapes temporelles spécifiques, telles que la mesure dans laquelle les informations du 19e jour dans le passé ont contribué aux prévisions du premier jour dans le futur. Ces attributions n'expliquent pas les covariables statiques individuelles ni les explications agrégées des séries chronologiques cibles et covariables. Les attributions sont une matrice A où chaque A tk est l'attribution du pas de temps t vers la prévision du pas de temps t+k. Notez que si le modèle accepte de futures covariables, t peut être supérieur à T.
Les explications détaillées nécessitent davantage de calculs et fournissent une ventilation complète de toutes les attributions des variables d'entrée.
Note
Les explications détaillées ne prennent en charge que l'ordre chronologique.
Les attributions qui en résultent sont un triplet composé des éléments suivants :
Matrice A x, R, T×K, relative à la série chronologique d'entrée, où A tk x est l'attribution de x à l'étape de prévision t t+K
Tenseur A z, R T+K×S×K, lié à la série chronologique des covariables, où A z est l'attribution de tskz ts (c'est-à-dire la sth covariable TS) à l'étape de prévision t+K
Matrice A u, R E×K, relative aux covariables statiques, où A ek u est l'attribution de u e (la covariable statique eth) à l'étape de prévision t+K
Quelle que soit la granularité, l'explication contient également un vecteur de décalage B et R K qui représente le « comportement de base » du modèle lorsque toutes les données sont obfusquées.
