Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
SageMaker Rapport interactif du débogueur
Recevez des rapports de profilage générés automatiquement par Debugger. Le rapport Debugger fournit des informations sur vos tâches d'entraînement et suggère des recommandations pour améliorer les performances de votre modèle. La capture d'écran suivante montre un collage du rapport de profilage Debugger. Pour en savoir plus, consultez SageMaker Rapport interactif du débogueur.
Note
Vous pouvez télécharger un rapport Debugger pendant que votre tâche d'entraînement est en cours d'exécution ou une fois la tâche terminée. Pendant l'entraînement, Debugger met à jour le rapport reflétant le statut d'évaluation des règles actuelles. Vous ne pouvez télécharger un rapport Debugger complet qu'une fois la tâche d'entraînement terminée.
Important
Dans les rapports, les diagrammes et les recommandations sont fournis à titre informatif et ne sont pas définitifs. Vous êtes tenu de réaliser votre propre évaluation indépendante des informations.
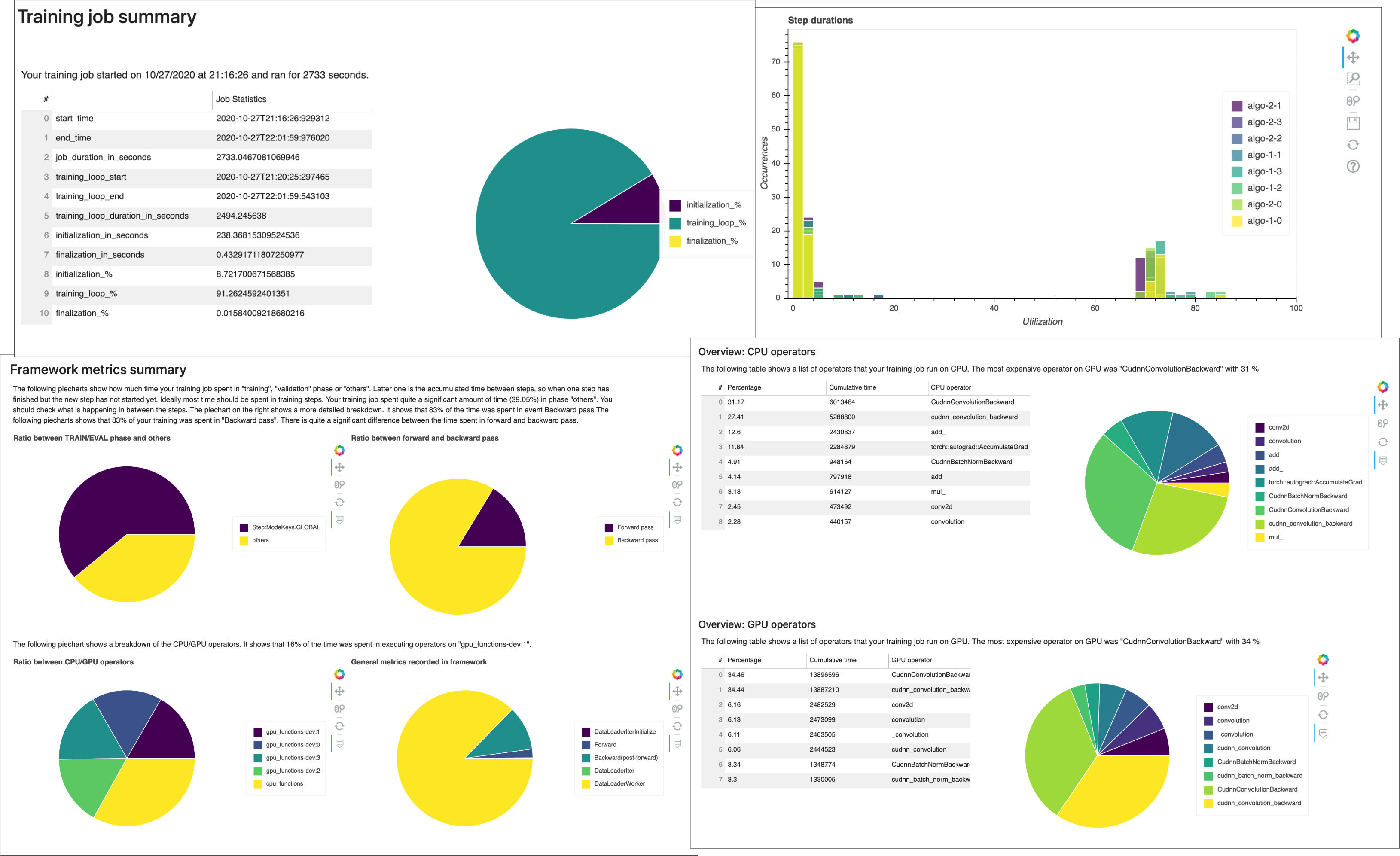
Pour tous les travaux de SageMaker formation, la ProfilerReport règle SageMaker Debugger invoque toutes les règles de surveillance et de profilage et regroupe l'analyse des règles dans un rapport complet. En suivant ce guide, téléchargez le rapport à l'aide du SDK Amazon SageMaker Python
Important
Dans le rapport, les diagrammes et les recommandations sont fournis à titre informatif et ne sont pas définitifs. Vous êtes tenu de réaliser votre propre évaluation indépendante des informations.
