Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fonctionnement des machines de factorisation
La tâche de prédiction d'un modèle Factorization Machines consiste à estimer une fonction ŷ à partir d'un ensemble de fonctions xi vers un domaine cible. Ce domaine s'emploie à valeur réelle pour la régression et sous forme binaire pour la classification. Le modèle Factorization Machines est supervisé et possède par conséquent un jeu de données d'entraînement (xi,yj) disponible. Il présente l'avantage d'utiliser une paramétrisation factorisée pour capturer les interactions de caractéristiques par paire. Il peut être représenté mathématiquement comme suit :

Les trois termes de cette équation correspondent respectivement aux trois composantes du modèle :
-
Le terme w0 représente le biais global.
-
Les termes linéaires wi modélisent la puissance de la variable ie.
-
Les termes de factorisation <vi,vj> modélisent l'interaction par paire entre les variables ie et je.
Les termes de biais global et les termes linaires sont identiques à ceux d'un modèle linéaire. Les interactions de caractéristiques par paire sont modélisées dans le troisième terme comme le produit interne des facteurs correspondants formés pour chaque caractéristique. Les facteurs formés peuvent aussi être considérés comme des vecteurs d'intégration pour chaque fonction. Par exemple, dans une tâche de classification, si une paire de caractéristiques a tendance à se produire plus souvent dans des exemples étiquetés positivement, le produit interne de leurs facteurs sera élevé. En d'autres termes, leurs vecteurs d'intégration sont proches les uns des autres en similarité de cosinus. Pour plus d'informations sur le modèle Factorization Machines, consultez l'article relatif à Factorization Machines
Pour les tâches de régression, le modèle est entraîné en réduisant l'erreur mise au carré entre la prédiction du modèle ŷn et la valeur cible yn. C'est ce que l'on appelle la « perte quadratique » :
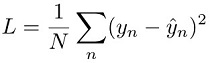
Pour une tâche de classification, le modèle est formé en réduisant la perte d'entropie croisée, ou perte logistique :
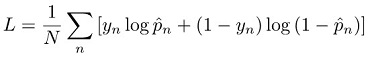
où :
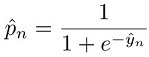
Pour plus d'informations sur les fonctions de perte relatives à la classification, consultez Loss functions for classification
