Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créez, stockez et partagez des fonctionnalités avec Feature Store
Le processus de développement de l'apprentissage automatique (ML) inclut l'extraction de données brutes, leur transformation en fonctionnalités (entrées significatives pour votre modèle de machine learning). Ces fonctionnalités sont ensuite stockées de manière fonctionnelle pour l'exploration des données, l'apprentissage automatique et l'inférence du machine learning. Amazon SageMaker Feature Store simplifie la création, le stockage, le partage et la gestion des fonctionnalités. Cela se fait en proposant des options de feature store et en réduisant le traitement répétitif des données et le travail de curation.
Avec Feature Store, vous pouvez notamment :
-
Simplifiez le traitement, le stockage, la récupération et le partage des fonctionnalités pour le développement du machine learning entre comptes ou au sein d'une organisation.
-
Suivez le développement de votre code de traitement des fonctionnalités, appliquez votre processeur de fonctionnalités aux données brutes et intégrez vos fonctionnalités dans Feature Store de manière cohérente. Cela réduit l'asymétrie entre les sessions d'entraînement, un problème courant dans le ML où la différence entre les performances pendant l'entraînement et pendant le service peut avoir un impact sur la précision de votre modèle de machine learning.
-
Stockez vos entités et les métadonnées associées dans des groupes d'entités, afin que les entités puissent être facilement découvertes et réutilisées. Les groupes de fonctionnalités sont modifiables et peuvent faire évoluer leur schéma après leur création.
-
Créez des groupes de fonctionnalités qui peuvent être configurés pour inclure un magasin en ligne ou hors ligne, ou les deux, afin de gérer vos fonctionnalités et d'automatiser le stockage des fonctionnalités pour vos tâches de machine learning.
-
La boutique en ligne ne conserve que les derniers enregistrements relatifs à vos fonctionnalités. Ceci est principalement conçu pour prendre en charge les prédictions en temps réel qui nécessitent des lectures à faible latence en millisecondes et des écritures à haut débit.
-
Le magasin hors ligne conserve tous les enregistrements de vos fonctionnalités sous forme de base de données historique. Ceci est principalement destiné à l'exploration des données, à l'apprentissage des modèles et aux prédictions par lots.
-
Le schéma suivant montre comment vous pouvez utiliser Feature Store dans le cadre de votre pipeline ML. Une fois que vous avez lu vos données brutes, vous pouvez utiliser Feature Store pour transformer les données brutes en entités et les intégrer dans votre groupe de fonctionnalités. Les fonctionnalités peuvent être ingérées par streaming ou par lots dans les boutiques en ligne et hors ligne du groupe de fonctionnalités. Les fonctionnalités peuvent ensuite être utilisées pour l'exploration des données, l'apprentissage des modèles et l'inférence en temps réel ou par lots.
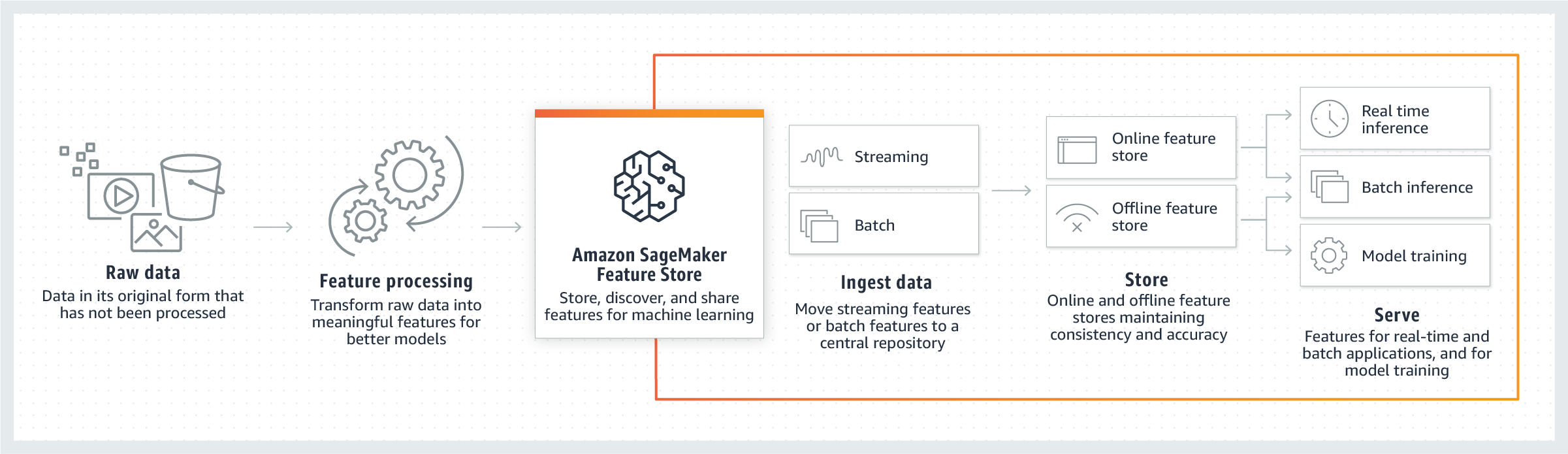
Fonctionnement de Feature Store
Dans le Feature Store, les fonctions sont stockées dans un ensemble appelé groupe de fonctions. Un groupe de fonctions peut se présenter sous la forme d'une table dans laquelle chaque colonne est une fonction, avec un identifiant unique pour chaque ligne. En principe, un groupe de fonctions est composé de fonctions et de valeurs spécifiques à chaque fonction. Un Record est un ensemble de valeurs pour les fonctions qui correspondent à un RecordIdentifier. Globalement, un FeatureGroup est un groupe de fonctions défini dans votre FeatureStore pour décrire un Record.
Vous pouvez utiliser le Feature Store dans les modes suivants :
-
En ligne : dans ce mode, les fonctions sont lues avec une faible latence (quelques millisecondes) et utilisées pour des prédictions de débit élevé. Dans ce mode, un groupe de fonctions doit être stocké dans une boutique en ligne.
-
Hors ligne : dans ce mode, des flux de données volumineux sont envoyés à une boutique hors ligne, qui peut être utilisée pour l'entraînement et l'inférence par lots. Dans ce mode, un groupe de fonctions doit être stocké dans une boutique hors ligne. La boutique hors ligne utilise votre compartiment S3 pour le stockage et peut aussi récupérer des données à l'aide de requêtes Athena.
-
En ligne et hors ligne : cela inclut les deux modes, en ligne et hors ligne.
Vous pouvez intégrer des données dans des groupes de fonctions du Feature Store de deux manières : par streaming ou par lots. Lorsque vous intégrez des données par streaming, un ensemble d'enregistrements est envoyé au Feature Store en appelant un appel d'API PutRecord synchrone. Cette API vous permet de gérer les dernières valeurs de fonctions dans le Feature Store et d'envoyer de nouvelles valeurs de fonctions dès qu'une mise à jour est détectée.
En variante, le Feature Store peut traiter et intégrer des données par lots. Par exemple, vous pouvez créer des fonctionnalités à l'aide d'Amazon SageMaker Data Wrangler et exporter un bloc-notes depuis Data Wrangler. Le bloc-notes peut être une tâche de SageMaker traitement qui intègre les fonctionnalités par lots dans un groupe de fonctionnalités Feature Store. Ce mode permet l'ingestion de lots dans la boutique hors ligne. Il prend également en charge l'ingestion dans la boutique en ligne si le groupe de fonctions est configuré pour une utilisation tant en ligne qu'hors ligne.
Création de groupes de fonctionnalités
Pour intégrer des fonctions dans le Feature Store, vous devez d'abord définir le groupe de fonctions et les définitions de fonctions (nom de fonction et type de données) pour toutes les fonctions appartenant au groupe de fonctions. Une fois créés, les groupes de fonctionnalités sont mutables et peuvent faire évoluer leur schéma. Les noms des groupes de fonctionnalités sont uniques au sein d'un Région AWS et Compte AWS. Lorsque vous créez un groupe d'entités, vous pouvez également créer les métadonnées du groupe d'entités. Les métadonnées peuvent contenir une brève description, la configuration du stockage, des fonctionnalités permettant d'identifier chaque enregistrement et l'heure de l'événement. En outre, les métadonnées peuvent inclure des balises pour stocker des informations telles que l'auteur, la source de données, la version, etc.
Important
Les noms des FeatureGroup ou les métadonnées associées telles que la description ou les balises ne doivent pas contenir de données d'identification personnelle (PII) ou d'informations confidentielles.
Recherche, découverte et partage de fonctionnalités
Une fois qu'un groupe de fonctions est créé dans le Feature Store, les autres utilisateurs autorisés du Feature Store peuvent le partager et le découvrir. Les utilisateurs peuvent parcourir une liste de tous les groupes de fonctions dans le Feature Store ou découvrir des groupes de fonctions existants en effectuant une recherche par nom de groupe de fonctions, description, nom d'identificateur d'enregistrement, date de création et balises.
Inférence en temps réel pour les fonctionnalités stockées dans le magasin en ligne
Avec le Feature Store, vous pouvez enrichir les fonctions stockées dans votre boutique en ligne en temps réel avec des données provenant d'une source de streaming (données de flux propres d'une autre application) et servir les fonctions avec une faible latence de quelques millisecondes pour une inférence en temps réel.
Vous pouvez également effectuer des jonctions entre différents FeatureGroups pour une inférence en temps réel en interrogeant deux FeatureGroups différents dans l'application cliente.
Magasin hors connexion pour l'entraînement de modèle et l'inférence par lots
Le Feature Store fournit un stockage hors ligne pour les valeurs de fonctions dans votre compartiment S3. Les données sont stockées dans votre compartiment S3 à partir d'un schéma de préfixation basé sur l'instant d'événement. La boutique hors ligne est une boutique « append-only » (ajout seulement), ce qui permet au Feature Store de maintenir un enregistrement historique de toutes les valeurs de fonctions. Les données sont stockées dans la boutique hors ligne au format Parquet pour optimiser le stockage et l'accès aux requêtes.
Vous pouvez interroger, explorer et visualiser des fonctionnalités à l'aide de Data Wrangler depuis la console. Le Feature Store prend en charge la combinaison de données pour produire, entraîner, valider et tester des jeux de données, et vous permet d'extraire des données à différents points dans le temps.
Ingestion de données de fonctionnalités
Des pipelines de génération de fonctions peuvent être créés pour traiter des lots volumineux (1 million de lignes de données ou plus) ou de petits lots, et pour écrire des données de fonctions dans la boutique hors ligne ou en ligne. Les sources de streaming telles que Amazon Managed Streaming for Apache Kafka ou Amazon Kinesis peuvent également être utilisées comme sources de données à partir desquelles les fonctions sont extraites et directement transmises à la boutique en ligne pour l'entraînement, l'inférence ou la création de fonctions.
Vous pouvez envoyer des enregistrements au Feature Store en appelant l'appel d'API PutRecord synchrone. Comme il s'agit d'un appel d'API synchrone, vous pouvez envoyer de petits lots de mises à jour dans un seul appel d'API. Vous pouvez ainsi actualiser les valeurs de fonctions régulièrement et les publier dès qu'une mise à jour est détectée. Celles-ci sont également appelées fonctions de streaming.
Lorsque les données de fonctions sont intégrées et mises à jour, le Feature Store stocke l'historique de données de toutes les fonctions de la boutique hors ligne. Pour l'intégration par lots, vous pouvez extraire des valeurs de fonctions de votre compartiment S3 ou utiliser Athena pour l'interrogation. Vous pouvez également utiliser Data Wrangler pour traiter et orchestrer de nouvelles fonctions qui peuvent ensuite être exportées vers un compartiment S3 choisi pour être accessible par le Feature Store. Pour l'ingestion de lots, vous pouvez configurer une tâche de traitement pour intégrer vos données par lots dans le Feature Store, ou vous pouvez extraire des valeurs de fonctions de votre compartiment S3 à l'aide d'Athena.
Pour supprimer un Record de votre boutique en ligne, utilisez l'appel d'API DeleteRecord. Cela ajoutera également l'enregistrement supprimé à la boutique hors ligne.
Résilience dans Feature Store
Le Feature Store est réparti sur plusieurs zones de disponibilité (AZs). Une zone de disponibilité est un emplacement isolé au sein d'une Région AWS. Si certaines AZs échouent, Feature Store peut en utiliser d'autres AZs. Pour plus d'informations sur AZs, voirLa résilience dans Amazon SageMaker AI.
