Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fonctionnement d'IP Insights
Amazon SageMaker AI IP Insights est un algorithme non supervisé qui consomme les données observées sous forme de paires (entité, IPv4 adresse) associant des entités à des adresses IP. IP Insights détermine la probabilité qu'une entité utilise une adresse IP donnée en apprenant les représentations vectorielles latentes correspondant aux entités et aux adresses IP. La distance entre ces deux représentations peut ensuite servir d'indicateur quant à la probabilité de cette association.
L'algorithme IP Insights utilise un réseau neuronal afin d'apprendre les représentations vectorielles latentes pour les entités et les adresses IP. Les entités sont d'abord hachées en un grand espace de hachage fixe, puis encodées par une simple couche d'intégration. Les chaînes de caractères telles que les noms d'utilisateur ou de compte IDs peuvent être introduites directement dans IP Insights lorsqu'elles apparaissent dans les fichiers journaux. Vous n'avez pas besoin de prétraiter les données pour les identificateurs d'entité. Vous pouvez fournir des entités sous la forme d'une valeur de chaîne arbitraire durant l'entraînement et l'inférence. La valeur de la taille de hachage configurée doit être suffisamment élevée pour que le nombre de collisions, qui se produisent lorsque des entités distinctes sont mappées au même vecteur latent, reste négligeable. Pour plus d'informations sur la sélection de tailles de hachage appropriées, consultez Feature Hashing for Large Scale Multitask Learning
Pendant l'entraînement, IP Insights génère automatiquement des échantillons négatifs en appairant de façon aléatoire les entités et les adresses IP. Ces échantillons négatifs représentent des données moins susceptibles de se produire en réalité. Le modèle est entraîné afin de distinguer les échantillons positifs observés dans les données d'entraînement de ces échantillons négatifs générés. Plus spécifiquement, le modèle est entraîné afin de réduire l'entropie croisée, ou perte logistique, qui se définit comme suit :

yn est l'étiquette qui indique si l'échantillon est issu de la distribution réelle régissant les données observées (yn=1) ou de la distribution générant des échantillons négatifs (yn=0). pn est la probabilité que l'échantillon soit issu de la distribution réelle, comme prévu par le modèle.
La génération d'échantillons négatifs est un important processus permettant d'obtenir un modèle précis des données observées. Si les échantillons négatifs sont très peu probables, par exemple si toutes les adresses IP dans les échantillons négatifs sont 10.0.0.0, alors le modèle apprend facilement à distinguer les échantillons négatifs et ne parvient pas à caractériser avec précision l'ensemble de données observé réel. Afin que les échantillons négatifs soient plus réalistes, IP Insights les crée en générant de façon aléatoire des adresses IP et en choisissant de façon aléatoire les adresses IP issues des données d'entraînement. Vous pouvez configurer le type d'échantillonnage négatif et les fréquences de génération des échantillons négatifs à l'aide des hyperparamètres random_negative_sampling_rate et shuffled_negative_sampling_rate.
Soit une énième (paire entité, adresse IP), le modèle IP Insights génère un score, Sn, qui indique le degré de compatibilité entre l'entité et l'adresse IP. Ce score correspond au ratio du logarithme de cote (log-odds-ratio) pour un couple (entité, adresse IP) donné de la paire issue d'une distribution réelle par rapport à une paire issue d'une distribution négative. Il se définit comme suit :
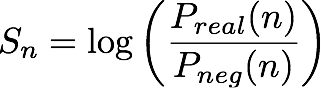
En substance, le score est une mesure de la similarité entre les représentations vectorielles de la énième entité et l'adresse IP. Il peut être interprété comme le degré de probabilité qu'il y aurait d'observer cet événement en réalité plutôt que dans un ensemble de données généré de façon aléatoire. Pendant l'entraînement, l'algorithme utilise ce score afin de calculer une estimation de la probabilité d'un échantillon issu de la distribution réelle, pn, à utiliser dans la réduction de l'entropie croisée, où :

