Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fonctionnement d'Object2Vec
Lorsque vous utilisez l'algorithme Amazon SageMaker AI Object2Vec, vous suivez le flux de travail standard : traiter les données, entraîner le modèle et produire des inférences.
Rubriques
Étape 1 : Traitement des données
Pendant le prétraitement, convertissez les données au format de fichier texte Lignes JSONnp.random.shuffle ; pour Unix, shuf.
Étape 2 : Entraîner un modèle
L'algorithme SageMaker AI Object2Vec comporte les principaux composants suivants :
-
Deux canaux d'entrée : les 2 canaux d'entrée acceptent une paire d'objets du même type ou de types différents comme entrées, et les transmettent à des encodeurs personnalisables et indépendants.
-
Deux encodeurs : les encodeurs enc0 et enc1 convertissent chaque objet en un vecteur d'intégration de longueur fixe. Intégrations encodées des objets de la paire, qui sont ensuite transmises à un comparateur.
-
Comparateur : le comparateur compare les intégrations de différentes manières et génère des scores qui indiquent la force de la relation entre les objets associés pour chaque type de relation spécifiée par l'utilisateur. Dans le score de sortie pour une paire de phrases. Par exemple, 1 indique une relation forte entre une paire de phrases et 0 représente une relation faible.
Au moment de l'entraînement, l'algorithme accepte les paires d'objets et leurs étiquettes ou scores de relation comme entrées. Les objets dans chaque paire peuvent être de différents types, comme indiqué plus tôt. Si les entrées pour les deux encodeurs sont composées de la même façon au niveau des unités, vous pouvez utiliser un jeton partagé ou intégrer une couche en définissant l'hyperparamètre tied_token_embedding_weight sur True lorsque vous créez la tâche d'entraînement. Cela est possible, par exemple, lors de la comparaison de phrases qui ont toutes les deux des unités de mot au niveau du jeton. Pour générer des exemples négatifs à un rythme déterminé, définissez l'hyperparamètre negative_sampling_rate sur le ratio souhaité exemples positifs/négatifs. Cet hyperparamètre accélère l'apprentissage de la distinction entre les exemples positifs observés dans les données d'entraînement et les exemples négatifs qui ont peu de probabilités d'être observés.
Ils sont transmis via des encodeurs indépendants et personnalisables, qui sont compatibles avec les types d'entrée des objets correspondants Les encodeurs convertissent chaque objet d'une paire en un vecteur d'intégration à longueur fixe d'égale longueur. La paire de vecteurs est transmise à un opérateur de comparaison, qui regroupe les vecteurs dans un vecteur unique à l'aide de la valeur spécifiée dans l'hyperparamètre comparator_list. Le vecteur assemblé transmet ensuite via une couche perceptron multicouche (MLP), qui produit une sortie que la fonction de perte compare aux étiquettes que vous avez fournies. Cette comparaison évalue la force de la relation entre les objets dans la paire comme prévu par le modèle. Le schéma suivant montre ce flux de travail.
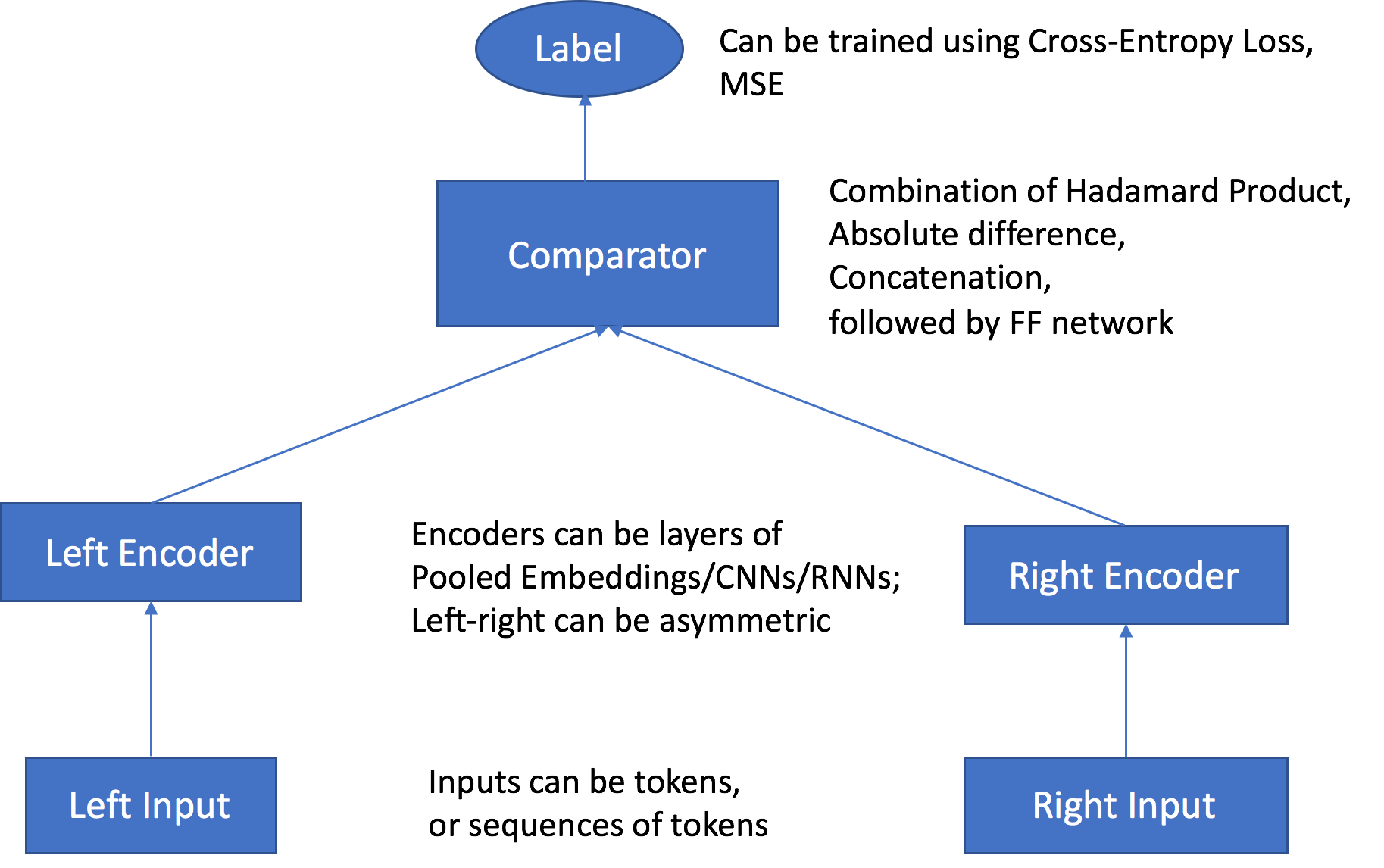
Architecture de l'algorithme Object2Vec des entrées de données aux scores
Étape 3 : Produire les inférences
Une fois que le modèle est entraîné, vous pouvez utiliser l'encodeur entraîné pour prétraiter les objets d'entrée ou pour exécuter les deux types d'inférence :
-
Pour convertir les objets d'entrée singleton en intégrations de longueur fixe à l'aide de l'encodeur correspondant
-
Pour prédire l'étiquette ou le score de relation entre une paire d'objets d'entrée
Le serveur d'inférence calcule automatiquement lequel des deux modes est demandé en fonction des données d'entrée. Pour obtenir les intégrations comme sortie, fournissez une seule entrée dans chaque instance. Pour prédire l'étiquette ou le score de relation, fournissez deux entrées dans la paire.
