Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation de l’architecture
Cette section fournit un schéma d'architecture d'implémentation de référence pour les composants déployés avec cette solution.
Diagramme d'architecture
Le déploiement de cette solution avec les paramètres par défaut permet de créer l'environnement suivant dans le cloud AWS.
Découverte de la charge de travail sur l'architecture AWS
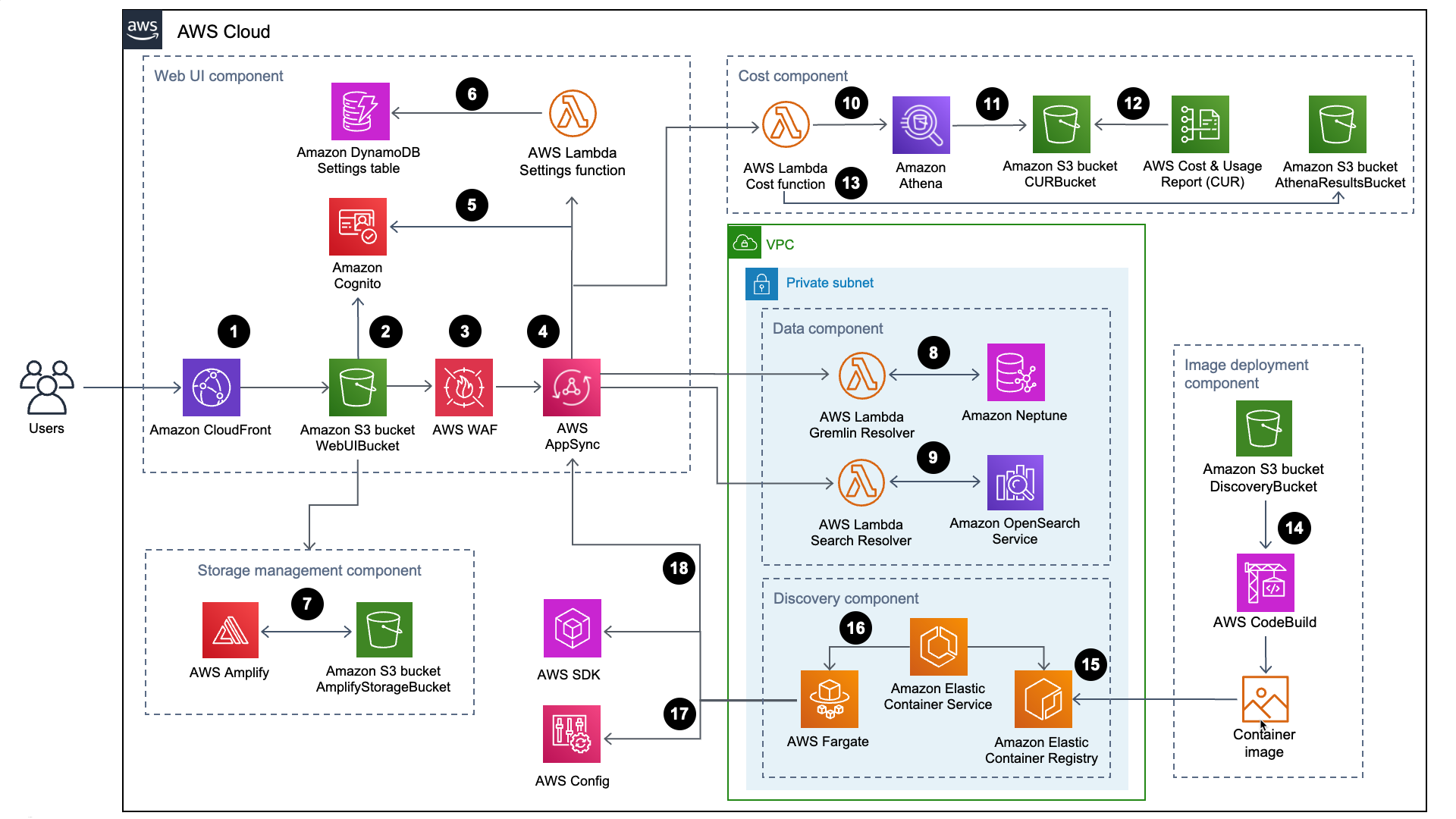
Le flux de processus de haut niveau pour les composants de solution déployés avec le CloudFormation modèle AWS est le suivant :
-
Le protocole HTTP Strict-Transport-Security (HSTS)
ajoute des en-têtes de sécurité à chaque réponse de la distribution Amazon CloudFront . -
Un compartiment Amazon Simple Storage Service
(Amazon S3) héberge l'interface utilisateur Web, qui est distribuée avec Amazon CloudFront. Amazon Cognito authentifie l'accès des utilisateurs à l'interface utilisateur Web. -
AWS WAF
protège l' AppSync API contre les exploits et les robots courants susceptibles d'affecter la disponibilité, de compromettre la sécurité ou de consommer des ressources excessives. -
Les AppSync points de terminaison AWS
permettent au composant de l'interface utilisateur Web de demander des données sur les relations entre les ressources, de demander les coûts, d'importer de nouvelles régions AWS et de mettre à jour les préférences. AWS permet AppSync également au composant de découverte de stocker des données persistantes dans les bases de données de la solution. -
AWS AppSync utilise des jetons Web JSON
(JWTs) fournis par Amazon Cognito pour authentifier chaque demande. -
La fonction
SettingsAWS Lambda conserveles régions importées et les autres configurations dans Amazon DynamoDB . -
La solution déploie AWS
Amplify et un compartiment Amazon S3 en tant que composant de gestion du stockage pour stocker les préférences des utilisateurs et les diagrammes d'architecture enregistrés. -
Le composant de données utilise la fonction
Gremlin ResolverAWS Lambda pour interroger et renvoyer des données depuis une base de données Amazon Neptune. -
Le composant de données utilise la fonction
Search ResolverLambda pour interroger et conserver les données de ressources dans un domaine Amazon OpenSearch Service. -
La fonction
CostLambda utilise Amazon Athenapour interroger les rapports sur les coûts et l'utilisation d'AWS (AWS CUR) afin de fournir des données de coûts estimées à l'interface utilisateur Web. -
Amazon Athena exécute des requêtes sur AWS CUR.
-
AWS CUR envoie les rapports au compartiment
CostAndUsageReportBucketAmazon S3. -
La fonction
CostLambda stocke les résultats Amazon Athena dans leAthenaResultsBucketcompartiment Amazon S3. -
AWS CodeBuild
crée l'image du conteneur du composant de découverte dans le composant de déploiement d'images. -
Amazon Elastic Container Registry
(Amazon ECR) contient une image Docker fournie par le composant de déploiement d'images. -
Amazon Elastic Container Service
(Amazon ECS) gère la tâche AWS Fargate et fournit la configuration requise pour exécuter la tâche. AWS Fargate exécute une tâche de conteneur toutes les 15 minutes pour actualiser les données d'inventaire et de ressources. -
Les appels AWS Config
et AWS SDK aident le composant de découverte à maintenir un inventaire des données de ressources provenant des régions importées, puis à stocker ses résultats dans le composant de données. -
La tâche AWS Fargate conserve les résultats des appels AWS Config et AWS SDK dans une base de données Amazon Neptune et un domaine OpenSearch Amazon Service avec des appels d'API vers l'API. AppSync
