Pour des fonctionnalités similaires à celles d'Amazon Timestream pour, pensez à Amazon Timestream LiveAnalytics pour InfluxDB. Il permet une ingestion simplifiée des données et des temps de réponse aux requêtes à un chiffre en millisecondes pour des analyses en temps réel. Pour en savoir plus, cliquez ici.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Agrégats simples au niveau de la flotte
Ce premier exemple décrit certains des concepts de base relatifs à l'utilisation de requêtes planifiées à l'aide d'un exemple simple de calcul d'agrégats au niveau du parc. À l'aide de cet exemple, vous allez apprendre ce qui suit.
-
Comment associer votre requête de tableau de bord utilisée pour obtenir des statistiques agrégées à une requête planifiée.
-
Comment Timestream for LiveAnalytics gère l'exécution des différentes instances de votre requête planifiée.
-
Comment faire en sorte que différentes instances de requêtes planifiées se chevauchent dans les plages temporelles et comment l'exactitude des données est maintenue dans la table cible pour garantir que votre tableau de bord utilisant les résultats de la requête planifiée vous donne des résultats correspondant au même agrégat calculé sur les données brutes.
-
Comment définir la plage horaire et la cadence d'actualisation de votre requête planifiée.
-
Comment suivre en libre-service les résultats des requêtes planifiées afin de les ajuster de manière à ce que la latence d'exécution des instances de requête soit dans les délais acceptables pour l'actualisation de vos tableaux de bord.
Rubriques
Agrégation à partir des tables sources
Dans cet exemple, vous suivez le nombre de métriques émises par les serveurs d'une région donnée par minute. Le graphique ci-dessous est un exemple illustrant cette série chronologique pour la région us-east-1.
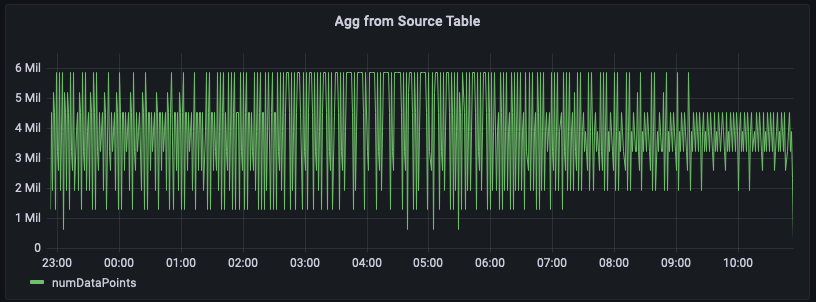
Vous trouverez ci-dessous un exemple de requête pour calculer cet agrégat à partir des données brutes. Il filtre les lignes pour la région us-east-1, puis calcule la somme par minute en prenant en compte les 20 mesures (si measure_name est une métrique) ou 5 événements (si measure_name est un événement). Dans cet exemple, l'illustration graphique montre que le nombre de métriques émises varie entre 1,5 million et 6 millions par minute. Lorsque vous tracez cette série chronologique pendant plusieurs heures (les 12 dernières heures sur cette figure), cette requête sur les données brutes analyse des centaines de millions de lignes.
WITH grouped_data AS ( SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY region, measure_name, bin(time, 1m) ) SELECT minute, SUM(numDataPoints) AS numDataPoints FROM grouped_data GROUP BY minute ORDER BY 1 desc, 2 desc
Requête planifiée pour précalculer les agrégats
Si vous souhaitez optimiser vos tableaux de bord afin de les charger plus rapidement et de réduire vos coûts en analysant moins de données, vous pouvez utiliser une requête planifiée pour précalculer ces agrégats. Les requêtes planifiées dans Timestream for vous LiveAnalytics permettent de matérialiser ces précalculs dans une autre LiveAnalytics table Timestream for, que vous pourrez ensuite utiliser pour vos tableaux de bord.
La première étape de la création d'une requête planifiée consiste à identifier la requête que vous souhaitez précalculer. Notez que le tableau de bord précédent a été dessiné pour la région us-east-1. Cependant, un autre utilisateur peut vouloir obtenir le même agrégat pour une région différente, par exemple us-west-2 ou eu-west-1. Pour éviter de créer une requête planifiée pour chacune de ces requêtes, vous pouvez précalculer l'agrégat pour chaque région et matérialiser les agrégats par région dans un autre Timestream for table. LiveAnalytics
La requête ci-dessous fournit un exemple du précalcul correspondant. Comme vous pouvez le constater, elle est similaire à l'expression de table courante grouped_data utilisée dans la requête sur les données brutes, à deux différences près : 1) elle n'utilise pas de prédicat de région, de sorte que nous pouvons utiliser une seule requête pour précalculer pour toutes les régions ; et 2) elle utilise un prédicat temporel paramétré avec un paramètre spécial @scheduled_runtime qui est expliqué en détail ci-dessous.
SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region
La requête précédente peut être convertie en requête planifiée à l'aide de la spécification suivante. Un nom est attribué à la requête planifiée, qui est un mnémotechnique convivial. Il inclut ensuite le QueryString, a ScheduleConfiguration, qui est une expression cron. Il indique TargetConfiguration qui fait correspondre les résultats de la requête à la table de destination dans Timestream for. LiveAnalytics Enfin, il spécifie un certain nombre d'autres configurations, telles que le NotificationConfiguration, où les notifications sont envoyées pour les exécutions individuelles de la requête, ErrorReportConfiguration où un rapport est rédigé au cas où la requête rencontrerait des erreurs, et le ScheduledQueryExecutionRoleArn, quel est le rôle utilisé pour effectuer les opérations pour la requête planifiée.
{ "Name": "MultiPT5mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/5 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt5m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
Dans l'exemple, le ScheduleExpression cron (0/5 * * * ? *) implique que la requête est exécutée une fois toutes les 5 minutes aux 5, 10, 15,... minutes de chaque heure de chaque jour. Ces horodatages lorsqu'une instance spécifique de cette requête est déclenchée sont ce qui se traduit par le paramètre @scheduled_runtime utilisé dans la requête. Par exemple, considérez l'instance de cette requête planifiée exécutée le 2021-12-01 00:00:00. Pour cette instance, le paramètre @scheduled_runtime est initialisé à l'horodatage 2021-12-01 00:00:00 lors de l'appel de la requête. Par conséquent, cette instance spécifique s'exécutera à l'horodatage 2021-12-01 00:00:00 et calculera les agrégats par minute entre le 2021-11-30 23:50:00 et le 2021-12-01 00:01:00. De même, l'instance suivante de cette requête est déclenchée à l'horodatage 2021-12-01 00:05:00 et dans ce cas, la requête calculera des agrégats par minute à partir de la plage horaire 2021-11-30 23:55:00 à 2021-12-01 00:06:00. Par conséquent, le paramètre @scheduled_runtime fournit une requête planifiée pour précalculer les agrégats pour les plages de temps configurées en utilisant le temps d'invocation des requêtes.
Notez que les deux instances suivantes de la requête se chevauchent dans leurs plages temporelles. C'est quelque chose que vous pouvez contrôler en fonction de vos besoins. Dans ce cas, ce chevauchement permet à ces requêtes de mettre à jour les agrégats en fonction des données dont l'arrivée a été légèrement retardée, jusqu'à 5 minutes dans cet exemple. Pour garantir l'exactitude des requêtes matérialisées, Timestream for LiveAnalytics garantit que la requête du 2021-12-01 00:05:00 ne sera exécutée qu'une fois la requête du 2021-12-01 00:00:00 terminée et que les résultats de ces dernières requêtes peuvent mettre à jour tout agrégat précédemment matérialisé en utilisant si une nouvelle valeur est générée. Par exemple, si certaines données à l'horodatage 2021-11-30 23:59:00 sont arrivées après l'exécution de la requête pour 2021-12-01 00:00:00 mais avant la requête pour 2021-12-01 00:05:00, alors l'exécution au 2021-12-01 00:05:00 recalculera les agrégats pour la minute 2021-11-30 23:59:00 et cela entraînera la mise à jour de l'agrégat précédent avec la valeur nouvellement calculée. Vous pouvez vous fier à cette sémantique des requêtes planifiées pour trouver un compromis entre la rapidité avec laquelle vous mettez à jour vos précalculs et la manière dont vous pouvez gérer certaines données avec élégance en cas d'arrivée différée. D'autres considérations sont abordées ci-dessous concernant la manière dont vous pouvez concilier cette cadence d'actualisation avec la fraîcheur des données et comment vous gérez la mise à jour des agrégats pour les données qui arrivent encore plus tard ou si la source du calcul planifié contient des valeurs mises à jour qui nécessiteraient le recalcul des agrégats.
Chaque calcul planifié possède une configuration de notification dans laquelle Timestream for LiveAnalytics envoie une notification de chaque exécution d'une configuration planifiée. Vous pouvez configurer une rubrique SNS pour recevoir des notifications pour chaque appel. Outre le statut de réussite ou d'échec d'une instance spécifique, elle contient également plusieurs statistiques telles que le temps d'exécution de ce calcul, le nombre d'octets analysés par le calcul et le nombre d'octets que le calcul a écrits dans sa table de destination. Vous pouvez utiliser ces statistiques pour affiner votre requête, planifier la configuration ou suivre les dépenses liées à vos requêtes planifiées. Un aspect à noter est le temps d'exécution d'une instance. Dans cet exemple, le calcul planifié est configuré pour être exécuté toutes les 5 minutes. Le temps d'exécution déterminera le délai dans lequel le précalcul sera disponible, ce qui définira également le décalage dans votre tableau de bord lorsque vous utilisez les données précalculées dans vos tableaux de bord. En outre, si ce délai est constamment supérieur à l'intervalle d'actualisation, par exemple, si le temps d'exécution est supérieur à 5 minutes pour un calcul configuré pour être actualisé toutes les 5 minutes, il est important de régler votre calcul pour qu'il s'exécute plus rapidement afin d'éviter tout retard supplémentaire dans vos tableaux de bord.
Agrégation à partir d'une table dérivée
Maintenant que vous avez configuré les requêtes planifiées et que les agrégats sont précalculés et matérialisés dans un autre Timestream pour la LiveAnalytics table spécifiée dans la configuration cible du calcul planifié, vous pouvez utiliser les données de cette table pour écrire des requêtes SQL destinées à alimenter vos tableaux de bord. Vous trouverez ci-dessous un équivalent de la requête qui utilise les pré-agrégats matérialisés pour générer l'agrégat du nombre de points de données par minute pour us-east-1.
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY bin(time, 1m) ORDER BY 1 desc
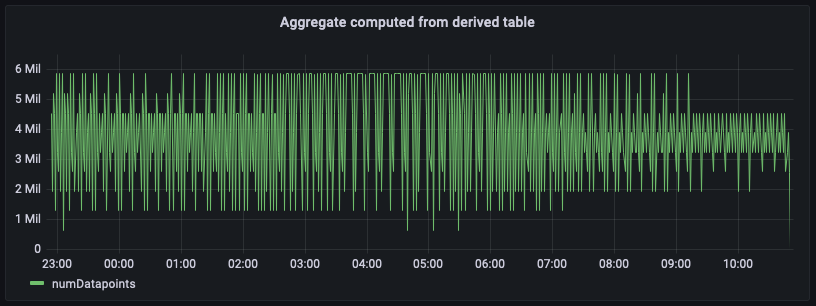
La figure précédente représente l'agrégat calculé à partir du tableau des agrégats. En comparant ce panneau avec le panneau calculé à partir des données source brutes, vous remarquerez qu'ils correspondent exactement, bien que ces agrégats soient retardés de quelques minutes, en fonction de l'intervalle d'actualisation que vous avez configuré pour le calcul planifié et du temps d'exécution de celui-ci.
Cette requête sur les données précalculées analyse les données de plusieurs ordres de grandeur en moins par rapport aux agrégats calculés sur les données sources brutes. En fonction de la granularité des agrégations, cette réduction peut facilement se traduire par une réduction de 100 fois des coûts et de la latence des requêtes. L'exécution de ce calcul planifié entraîne un coût. Toutefois, en fonction de la fréquence à laquelle ces tableaux de bord sont actualisés et du nombre d'utilisateurs qui les chargent simultanément, vous finissez par réduire considérablement vos coûts globaux en utilisant ces précalculs. Et cela s'ajoute à des temps de chargement 10 à 100 fois plus rapides pour les tableaux de bord.
Agrégation combinant des tables source et dérivées
Les tableaux de bord créés à l'aide des tables dérivées peuvent présenter un décalage. Si le scénario de votre application nécessite que les tableaux de bord contiennent les données les plus récentes, vous pouvez utiliser la puissance et la flexibilité du support SQL LiveAnalytics de Timestream for pour combiner les dernières données de la table source avec les agrégats historiques de la table dérivée afin de former une vue fusionnée. Cette vue fusionnée utilise la sémantique d'union du SQL et les plages de temps non superposées de la table source et de la table dérivée. Dans l'exemple ci-dessous, nous utilisons le terme « dérivé ». » per_minute_aggs_pt5m » table dérivée. Comme le calcul planifié pour cette table dérivée est actualisé toutes les 5 minutes (conformément à la spécification de l'expression de planification), la requête ci-dessous utilise les 15 dernières minutes de données de la table source et toutes les données datant de plus de 15 minutes de la table dérivée, puis réunit les résultats pour créer la vue fusionnée qui offre le meilleur des deux mondes : économie et faible latence en lisant les anciens agrégats précalculés de la table dérivée et la fraîcheur des agrégats provenant de la source pour optimiser vos cas d'utilisation de l'analyse en temps réel.
Notez que cette approche d'union aura une latence de requête légèrement plus élevée que celle consistant à interroger uniquement la table dérivée et qu'elle permettra également d'analyser un peu plus de données, car elle agrège les données brutes en temps réel pour remplir l'intervalle de temps le plus récent. Cependant, cette vue fusionnée restera nettement plus rapide et moins coûteuse que l'agrégation à la volée à partir de la table source, en particulier pour les tableaux de bord affichant des jours ou des semaines de données. Vous pouvez ajuster les plages de temps pour cet exemple en fonction des besoins d'actualisation et de tolérance aux délais de votre application.
WITH aggregated_source_data AS ( SELECT bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDatapoints FROM "raw_data"."devops" WHERE time BETWEEN bin(from_milliseconds(1636743196439), 1m) - 15m AND from_milliseconds(1636743196439) AND region = 'us-east-1' GROUP BY bin(time, 1m) ), aggregated_derived_data AS ( SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996439) AND bin(from_milliseconds(1636743196439), 1m) - 15m AND region = 'us-east-1' GROUP BY bin(time, 1m) ) SELECT minute, numDatapoints FROM ( ( SELECT * FROM aggregated_derived_data ) UNION ( SELECT * FROM aggregated_source_data ) ) ORDER BY 1 desc
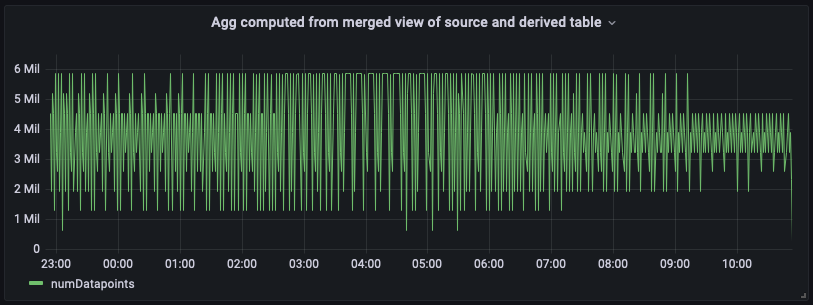
Vous trouverez ci-dessous le panneau du tableau de bord avec cette vue fusionnée unifiée. Comme vous pouvez le constater, le tableau de bord est presque identique à la vue calculée à partir de la table dérivée, sauf qu'il aura le plus d' up-to-dateagrégats à l'extrémité droite.
Agrégation à partir de calculs planifiés fréquemment actualisés
En fonction de la fréquence de chargement de vos tableaux de bord et de la latence que vous souhaitez pour votre tableau de bord, il existe une autre approche pour obtenir des résultats plus récents dans votre tableau de bord : faire en sorte que les calculs planifiés actualisent les agrégats plus fréquemment. Par exemple, vous trouverez ci-dessous la configuration du même calcul planifié, sauf qu'il est actualisé une fois par minute (notez le calendrier express cron (0/1 * * * ? *). Avec cette configuration, la table dérivée per_minute_aggs_pt1m aura des agrégats beaucoup plus récents par rapport au scénario dans lequel le calcul spécifiait un programme d'actualisation toutes les 5 minutes.
{ "Name": "MultiPT1mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/1 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt1m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt1m" WHERE time BETWEEN from_milliseconds(1636699996446) AND from_milliseconds(1636743196446) AND region = 'us-east-1' GROUP BY bin(time, 1m), region ORDER BY 1 desc
Comme la table dérivée contient des agrégats plus récents, vous pouvez désormais interroger directement la table dérivée per_minute_aggs_pt1m pour obtenir des agrégats plus récents, comme le montrent la requête précédente et l'instantané du tableau de bord ci-dessous.
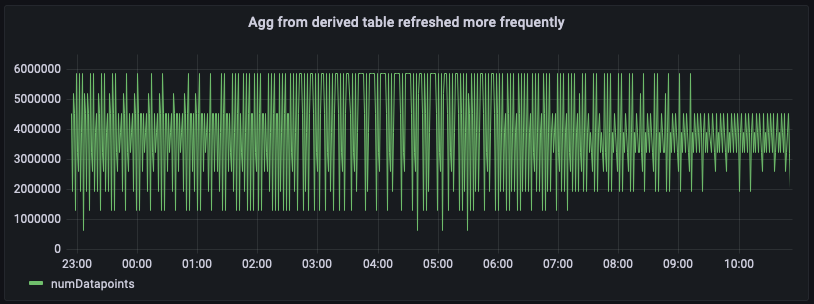
Notez que l'actualisation du calcul planifié à un rythme plus rapide (disons 1 minute au lieu de 5 minutes) augmentera les coûts de maintenance du calcul planifié. Le message de notification pour l'exécution de chaque calcul fournit des statistiques sur la quantité de données scannée et la quantité écrite dans la table dérivée. De même, si vous utilisez la vue fusionnée pour unir la table dérivée, vous interrogez les coûts sur la vue fusionnée et la latence de chargement du tableau de bord sera plus élevée par rapport à une simple interrogation de la table dérivée. Par conséquent, l'approche que vous choisirez dépendra de la fréquence d'actualisation de vos tableaux de bord et des coûts de maintenance des requêtes planifiées. Si des dizaines d'utilisateurs actualisent les tableaux de bord une fois par minute environ, une actualisation plus fréquente de votre table dérivée se traduira probablement par une réduction globale des coûts.
