Pour des fonctionnalités similaires à celles d'Amazon Timestream pour, pensez à Amazon Timestream LiveAnalytics pour InfluxDB. Il permet une ingestion simplifiée des données et des temps de réponse aux requêtes à un chiffre en millisecondes pour des analyses en temps réel. Pour en savoir plus, cliquez ici.
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
UNLOAD
Timestream for LiveAnalytics prend en charge une UNLOAD commande en tant qu'extension de son support SQL. Les types de données pris en charge par UNLOAD sont décrits dansTypes de données pris en charge. Les unknown types time et ne s'appliquent pas àUNLOAD.
UNLOAD (SELECT statement) TO 's3://bucket-name/folder' WITH ( option = expression [, ...] )
où se trouve l'option
{ partitioned_by = ARRAY[ col_name[,…] ] | format = [ '{ CSV | PARQUET }' ] | compression = [ '{ GZIP | NONE }' ] | encryption = [ '{ SSE_KMS | SSE_S3 }' ] | kms_key = '<string>' | field_delimiter ='<character>' | escaped_by = '<character>' | include_header = ['{true, false}'] | max_file_size = '<value>' }
- Déclaration SELECT
-
L'instruction de requête utilisée pour sélectionner et récupérer les données d'un ou de plusieurs Timestream pour les LiveAnalytics tables.
(SELECT column 1, column 2, column 3 from database.table where measure_name = "ABC" and timestamp between ago (1d) and now() ) - Clause TO
-
TO 's3://bucket-name/folder'or
TO 's3://access-point-alias/folder'La
TOclause contenue dans l'UNLOADinstruction indique la destination de sortie des résultats de la requête. Vous devez fournir le chemin complet, y compris soit le nom du compartiment Amazon S3, soit Amazon S3 access-point-alias avec l'emplacement du dossier sur Amazon S3 où Timestream for LiveAnalytics écrit les objets du fichier de sortie. Le compartiment S3 doit appartenir au même compte et se trouver dans la même région. Outre le jeu de résultats de la requête, Timestream for LiveAnalytics écrit le manifeste et les fichiers de métadonnées dans le dossier de destination spécifié. - Clause PARTITIONED_BY
-
partitioned_by = ARRAY [col_name[,…] , (default: none)La
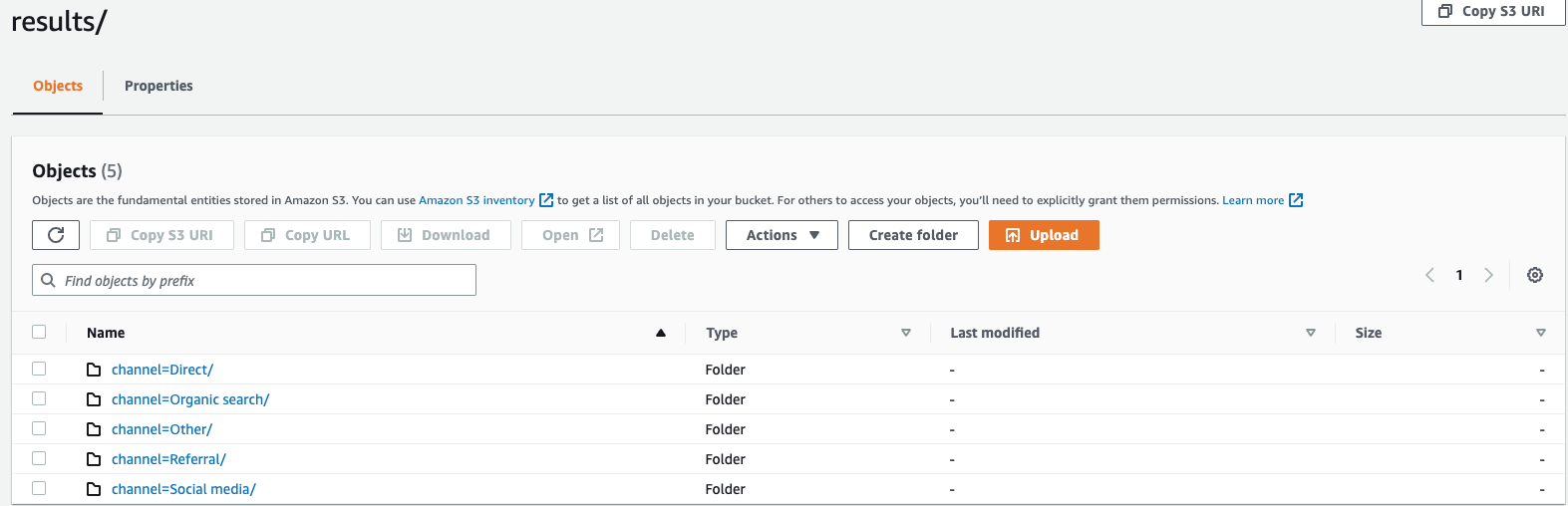
partitioned_byclause est utilisée dans les requêtes pour regrouper et analyser les données à un niveau granulaire. Lorsque vous exportez les résultats de votre requête vers le compartiment S3, vous pouvez choisir de partitionner les données en fonction d'une ou de plusieurs colonnes de la requête de sélection. Lors du partitionnement des données, les données exportées sont divisées en sous-ensembles en fonction de la colonne de partition et chaque sous-ensemble est stocké dans un dossier distinct. Dans le dossier de résultats qui contient vos données exportées, un sous-dossierfolder/results/partition column = partition value/est automatiquement créé. Notez toutefois que les colonnes partitionnées ne sont pas incluses dans le fichier de sortie.partitioned_byn'est pas une clause obligatoire dans la syntaxe. Si vous choisissez d'exporter les données sans partitionnement, vous pouvez exclure la clause dans la syntaxe.En supposant que vous surveillez les données du flux de clics de votre site Web et que vous disposiez de 5 canaux de trafic
directSocial Media, à savoirOrganic Search,Other, etReferral. Lorsque vous exportez les données, vous pouvez choisir de les partitionner à l'aide de la colonneChannel. Dans votre dossier de donnéess3://bucketname/results, vous aurez cinq dossiers portant chacun leur nom de chaîne respectif. Par exemple,s3://bucketname/results/channel=Social Media/.dans ce dossier, vous trouverez les données de tous les clients qui ont accédé à votre site Web via leSocial Mediacanal. De même, vous aurez d'autres dossiers pour les chaînes restantes.Données exportées partitionnées par colonne de canal
- FORMAT
-
format = [ '{ CSV | PARQUET }' , default: CSVLes mots clés permettant de spécifier le format des résultats de requête écrits dans votre compartiment S3. Vous pouvez exporter les données soit sous forme de valeur séparée par des virgules (CSV) en utilisant une virgule (,) comme séparateur par défaut, soit au format Apache Parquet, un format de stockage en colonnes ouvert efficace pour les analyses.
- COMPRESSION
-
compression = [ '{ GZIP | NONE }' ], default: GZIPVous pouvez compresser les données exportées à l'aide de l'algorithme de compression GZIP ou les décompresser en spécifiant l'
NONEoption. - CHIFFREMENT
-
encryption = [ '{ SSE_KMS | SSE_S3 }' ], default: SSE_S3Les fichiers de sortie sur Amazon S3 sont chiffrés à l'aide de l'option de chiffrement que vous avez sélectionnée. Outre vos données, le manifeste et les fichiers de métadonnées sont également chiffrés en fonction de l'option de chiffrement que vous avez sélectionnée. Nous prenons actuellement en charge le chiffrement SSE_S3 et SSE_KMS. SSE_S3 est un chiffrement côté serveur, Amazon S3 chiffrant les données à l'aide d'un chiffrement AES (Advanced Encryption Standard) 256 bits. SSE_KMS est un chiffrement côté serveur qui permet de chiffrer les données à l'aide de clés gérées par le client.
- KMS_KEY
-
kms_key = '<string>'La clé KMS est une clé définie par le client pour chiffrer les résultats de requête exportés. La clé KMS est gérée de manière sécurisée par le service de gestion des AWS clés (AWS KMS) et utilisée pour chiffrer les fichiers de données sur Amazon S3.
- DÉLIMITEUR DE CHAMP
-
field_delimiter ='<character>' , default: (,)Lors de l'exportation des données au format CSV, ce champ spécifie un seul caractère ASCII utilisé pour séparer les champs du fichier de sortie, tel qu'un tube (|), une virgule (,) ou un onglet (/t). Le délimiteur par défaut pour les fichiers CSV est un caractère de virgule. Si une valeur de vos données contient le délimiteur choisi, celui-ci sera mis entre guillemets. Par exemple, si la valeur de vos données contient
Time,stream, elle sera indiquée entre guillemets comme"Time,stream"dans les données exportées. Les guillemets utilisés par Timestream LiveAnalytics sont des guillemets doubles («).Évitez de spécifier le caractère de renvoi (ASCII 13, hexadécimal
0D, texte « \ r ») ou le caractère de saut de ligne (ASCII 10, hexadécimal 0A, texte «\n»)FIELD_DELIMITERsi vous souhaitez inclure des en-têtes dans le CSV, car cela empêcherait de nombreux analyseurs de les analyser correctement dans la sortie CSV résultante. - ÉVADÉ PAR
-
escaped_by = '<character>', default: (\)Lors de l'exportation des données au format CSV, ce champ indique le caractère qui doit être traité comme un caractère d'échappement dans le fichier de données écrit dans le compartiment S3. L'évasion se produit dans les scénarios suivants :
-
Si la valeur elle-même contient le caractère guillemet («), elle sera échappée à l'aide d'un caractère d'échappement. Par exemple, si la valeur est
Time"stream, où (\) est le caractère d'échappement configuré, il sera échappé en tant queTime\"stream. -
Si la valeur contient le caractère d'échappement configuré, il sera échappé. Par exemple, si la valeur est
Time\stream, elle sera ignorée en tant queTime\\stream.
Note
Si la sortie exportée contient des types de données complexes tels que des tableaux, des lignes ou des séries temporelles, elle sera sérialisée sous forme de chaîne JSON. Voici un exemple.
Type de données Valeur réelle Comment la valeur est échappée au format CSV [chaîne JSON sérialisée] Tableau
[ 23,24,25 ]"[23,24,25]"Rangée
( x=23.0, y=hello )"{\"x\":23.0,\"y\":\"hello\"}"Chronologique
[ ( time=1970-01-01 00:00:00.000000010, value=100.0 ),( time=1970-01-01 00:00:00.000000012, value=120.0 ) ]"[{\"time\":\"1970-01-01 00:00:00.000000010Z\",\"value\":100.0},{\"time\":\"1970-01-01 00:00:00.000000012Z\",\"value\":120.0}]" -
- INCLUDE_EN-TÊTE
-
include_header = 'true' , default: 'false'Lorsque vous exportez les données au format CSV, ce champ vous permet d'inclure les noms de colonnes dans la première ligne des fichiers de données CSV exportés.
Les valeurs acceptées sont « vrai » et « faux » et la valeur par défaut est « faux ». Les options de transformation de texte telles que
escaped_byetfield_delimiters'appliquent également aux en-têtes.Note
Lorsque vous incluez des en-têtes, il est important de ne pas sélectionner un caractère de renvoi (ASCII 13, hexadécimal 0D, texte « \ r ») ou un caractère de saut de ligne (ASCII 10, hexadécimal 0A, texte «\n»)
FIELD_DELIMITER, car cela empêcherait de nombreux analyseurs d'analyser correctement les en-têtes dans la sortie CSV résultante. - TAILLE MAXIMALE DU FICHIER
-
max_file_size = 'X[MB|GB]' , default: '78GB'Ce champ indique la taille maximale des fichiers créés par l'
UNLOADinstruction dans Amazon S3. L'UNLOADinstruction peut créer plusieurs fichiers, mais la taille maximale de chaque fichier écrit sur Amazon S3 sera approximativement celle spécifiée dans ce champ.La valeur du champ doit être comprise entre 16 Mo et 78 Go inclus. Vous pouvez le spécifier en nombre entier tel que
12GB, ou en décimaux tels que0.5GBou.24.7MBLa valeur par défaut est de 78 Go.La taille réelle du fichier est approximative au moment de l'écriture du fichier, de sorte que la taille maximale réelle peut ne pas être exactement égale au nombre que vous spécifiez.
