COST09-BP03 Fournir des ressources de manière dynamique
Les ressources sont allouées de façon planifiée. Cela peut reposer sur la demande, par exemple, via une mise à l’échelle automatique, ou sur le temps, lorsque la demande est prévisible et que les ressources sont fournies en fonction de la durée. Ces méthodes permettent de réduire au minimum la surallocation ou la sous-allocation.
Niveau d’exposition au risque si cette bonne pratique n’est pas respectée : faible
Directives d’implémentation
Les AWS clients disposent de plusieurs moyens pour augmenter les ressources disponibles pour leurs applications et fournir des ressources pour répondre à la demande. L'une de ces options consiste à utiliser AWS Instance Scheduler, qui automatise le démarrage et l'arrêt des instances Amazon Elastic Compute Cloud (AmazonEC2) et Amazon Relational Database Service (Amazon). RDS L'autre option consiste à utiliser AWS Auto Scaling, ce qui vous permet de dimensionner automatiquement vos ressources informatiques en fonction de la demande de votre application ou de votre service. La fourniture de ressources en fonction de la demande vous permettra de payer uniquement les ressources que vous utilisez, de réduire les coûts en lançant des ressources lorsqu’elles sont nécessaires et d’y mettre fin lorsqu’elles ne le sont pas.
AWS Instance Scheduler
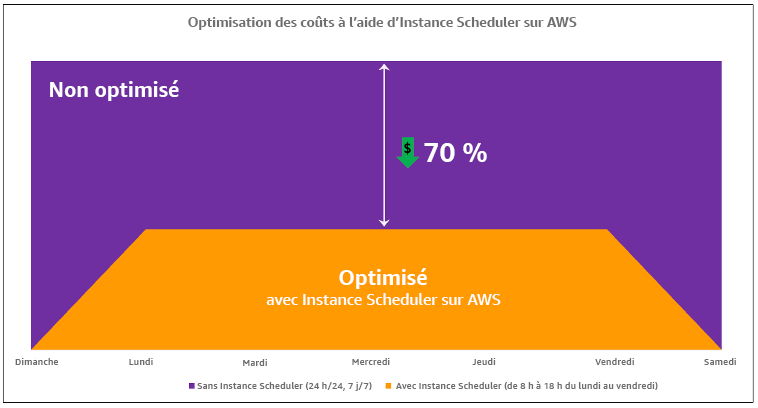
Optimisation des coûts avec AWS Instance Scheduler.
Vous pouvez également configurer facilement les plannings de vos EC2 instances Amazon sur l'ensemble de vos comptes et de vos régions à l'aide d'une interface utilisateur (UI) simple utilisant la configuration AWS Systems Manager rapide. Vous pouvez planifier des RDS instances Amazon EC2 ou Amazon avec AWS Instance Scheduler et arrêter et démarrer des instances existantes. Cependant, vous ne pouvez pas arrêter et démarrer des instances qui font partie de votre groupe Auto Scaling (ASG) ou qui gèrent des services tels qu'Amazon Redshift ou Amazon OpenSearch Service. Les groupes Auto Scaling ont leur propre planification pour les instances du groupe et ces instances sont créées.
AWS Auto Scaling
Plusieurs options sont disponibles pour mettre à l’échelle votre groupe Auto Scaling :
-
Maintenir les niveaux d’instance actuels à tout moment
-
Mise à l’échelle manuelle
-
Mise à l’échelle selon un calendrier
-
Mise à l’échelle en fonction de la demande
-
Utiliser la mise à l’échelle prédictive
Les stratégies d’autoscaling diffèrent et peuvent être classées dans la catégorie des stratégies de mise à l’échelle dynamiques et planifiées. Les stratégies dynamiques sont une mise à l’échelle manuelle ou dynamique, une mise à l’échelle planifiée ou prédictive. Vous pouvez utiliser des stratégies de mise à l’échelle pour une mise à l’échelle dynamique, planifiée et prédictive. Vous pouvez également utiliser les métriques et les alarmes d'Amazon CloudWatch
Vous pouvez utiliser AWS Auto Scaling ou intégrer la mise à l'échelle dans votre code avec AWS APIsou SDKs
Elastic Load Balancing (ELB)
Les métriques typiques peuvent être des EC2 métriques Amazon standard, telles que CPU l'utilisation, le débit du réseau et la latence observée par Elastic Load Balancing pour les demandes et les réponses. Dans la mesure du possible, vous devez utiliser une métrique qui indique l’expérience du client, généralement une métrique personnalisée qui peut provenir du code d’application au sein de votre charge de travail. Pour expliquer comment répondre à la demande de manière dynamique dans ce document, nous allons regrouper l’autoscaling en deux catégories, à savoir les modèles d’offre basés sur la demande et les modèles d’offre basés sur le temps, puis approfondir chacune d’entre elles.
Offre basée sur la demande : tirez parti de l’élasticité du cloud pour fournir les ressources nécessaires à l’évolution de la demande en vous appuyant sur l’état de la demande en temps quasi réel. Pour les fonctionnalités d'approvisionnement, d'utilisation APIs ou de service basées sur la demande afin de faire varier par programmation la quantité de ressources cloud dans votre architecture. Cela vous permet de mettre à l’échelle les composants de votre architecture, d’augmenter le nombre de ressources pendant les pics de demande pour maintenir les performances, et de diminuer la capacité lorsque la demande diminue pour réduire les coûts.

Stratégies de mise à l’échelle dynamique basées sur la demande
-
Mise à l’échelle simple/par étape : surveille les métriques et ajoute/supprime des instances selon des étapes définies manuellement par les clients.
-
Suivi des cibles : mécanisme de contrôle semblable à un thermostat qui ajoute ou supprime automatiquement des instances afin de maintenir les métriques à une cible définie par le client.
Lorsque vous concevez une architecture en adoptant une approche basée sur la demande, gardez à l’esprit deux considérations clés. Premièrement, vous devez comprendre à quelle vitesse vous devez allouer de nouvelles ressources. Deuxièmement, vous devez comprendre que l’importance de la marge entre l’offre et la demande variera. Vous devez être prêt à faire face au taux de variation de la demande, ainsi qu’aux défaillances de ressources.
Offre basée sur le temps : une approche fondée sur le temps permet d’aligner la capacité des ressources sur la demande qui est prévisible ou bien définie par le temps. Cette approche ne dépend généralement pas des niveaux d’utilisation des ressources. Une approche basée sur le temps garantit que les ressources sont disponibles au moment précis où elles sont nécessaires et peuvent être fournies sans aucun retard dû à des procédures de démarrage et aux vérifications du système ou de la cohérence. Grâce à une approche basée sur le temps, vous pouvez fournir des ressources supplémentaires ou augmenter la capacité pendant les périodes de pointe.
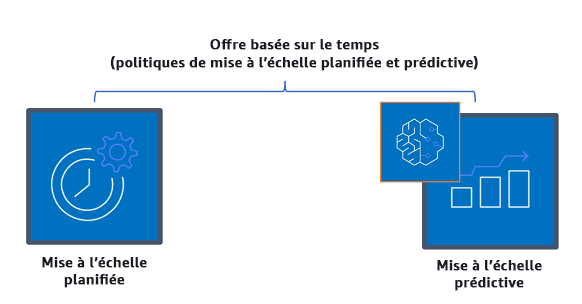
Stratégies de mise à l’échelle basées sur le temps
Vous pouvez utiliser l’autoscaling planifié pour mettre en place une approche basée sur le temps. Les charges de travail peuvent être programmées de manière à être réduites ou augmentées horizontalement à des moments définis (par exemple, au début des heures de travail), ce qui rend les ressources disponibles lorsque les utilisateurs arrivent ou que la demande augmente. La mise à l’échelle prédictive utilise des modèles pour augmenter horizontalement, tandis que la mise à l’échelle planifiée utilise des heures prédéfinies pour augmenter horizontalement. Vous pouvez également utiliser la stratégie de sélection du type d'instance (ABS) basée sur les attributs dans les groupes Auto Scaling, qui vous permet d'exprimer les besoins de votre instance sous la forme d'un ensemble d'attributs, tels que vCPU, memory et storage. Cela vous permet également d'utiliser automatiquement des types d'instances de nouvelle génération lors de leur sortie et d'accéder à une gamme plus large de capacités avec les instances Amazon EC2 Spot. Amazon EC2 Fleet et Amazon EC2 Auto Scaling sélectionnent et lancent des instances qui correspondent aux attributs spécifiés, ce qui évite de devoir sélectionner manuellement les types d'instances.
Vous pouvez également tirer parti du AWS APIsand SDKs
Lorsque vous concevez une architecture en adoptant une approche basée sur le temps, gardez à l’esprit deux considérations clés. Premièrement, dans quelle mesure le modèle d’utilisation est-il cohérent ? Deuxièmement, quel est l’impact d’un changement de modèle ? Vous pouvez augmenter la précision des prédictions en surveillant vos charges de travail et en utilisant l’informatique décisionnelle. Si vous constatez des modifications importantes dans le modèle d'utilisation, vous pouvez ajuster les heures pour vous assurer que la couverture est fournie.
Étapes d’implémentation
-
Configuration d’une mise à l’échelle planifiée : pour des changements prévisibles de la demande, une mise à l’échelle temporelle peut fournir le nombre correct de ressources en temps utile. Elle est également utile si la création et la configuration des ressources ne sont pas assez rapides pour répondre à l’évolution de la demande. À l’aide de l’analyse de la charge de travail, configurez la mise à l’échelle programmée via AWS Auto Scaling. Pour configurer la planification basée sur le temps, vous pouvez utiliser le dimensionnement prédictif du dimensionnement planifié pour augmenter à l'avance le nombre d'EC2instances Amazon dans vos groupes Auto Scaling en fonction des changements de charge attendus ou prévisibles.
-
Configurer le dimensionnement prédictif : le dimensionnement prédictif vous permet d'augmenter le nombre d'EC2instances Amazon dans votre groupe Auto Scaling avant les tendances quotidiennes et hebdomadaires des flux de trafic. Si vous avez des pics de trafic réguliers et des applications lentes au démarrage, vous devez envisager la mise à l’échelle prédictive. La mise à l’échelle prédictive vous permet de mettre à l’échelle le système plus rapidement en initialisant de la capacité avant d’atteindre la charge projetée par comparaison avec la mise à l’échelle dynamique seule, qui est réactive par nature. Par exemple, si les utilisateurs commencent à utiliser votre charge de travail au début des heures de bureau mais pas pendant les heures qui suivent, la mise à l’échelle prédictive peut ajouter de la capacité avant le début des heures de bureau, ce qui supprime le retard lié au fait d’attendre que la mise à l’échelle dynamique réagisse au changement de trafic.
-
Configuration de la mise à l’échelle automatique dynamique : pour configurer la mise à l’échelle en fonction des mesures de la charge de travail active, utilisez l’autoscaling Utilisez l’analyse et configurez l’autoscaling pour déclencher les bons niveaux de ressources, et vérifiez que la charge de travail est mise à l’échelle dans les délais requis. Vous pouvez lancer et mettre automatiquement à l’échelle une flotte d’instances à la demande et d’instances Spot au sein d’un même groupe Auto Scaling. Outre les remises accordées sur l’utilisation des instances Spot, vous pouvez utiliser des instances réservées ou un Savings Plan afin de bénéficier de réductions sur les tarifs standard des instances à la demande. Tous ces facteurs combinés vous aident à optimiser les économies réalisées sur les EC2 instances Amazon et à obtenir l'échelle et les performances souhaitées pour votre application.
Ressources
Documents connexes :
-
Mettre la taille de votre groupe Auto Scaling à l’échelle
Vidéos connexes :
Exemples connexes :
