REL12-BP04 Tester la résilience à l’aide de l’ingénierie du chaos
Exécutez régulièrement des expériences de chaos dans des environnements dont les conditions se rapprochent autant que possible de la production pour comprendre comment nos systèmes réagissent à des conditions défavorables.
Résultat escompté :
la résilience de la charge de travail est régulièrement vérifiée en appliquant l’ingénierie du chaos sous la forme d’expériences d’injection de pannes ou de charge inattendue, en plus des tests de résilience qui confirment le comportement attendu connu de votre charge de travail lors d’un événement. Associez l’ingénierie du chaos aux tests de résilience pour avoir l’assurance que votre charge de travail peut résister en cas de défaillance des composants et récupérer suite à des perturbations inattendues avec peu ou pas d’impact.
Anti-modèles courants :
-
Conception à des fins de résilience, mais pas de vérification du fonctionnement de la charge de travail dans son ensemble en cas de défaillances.
-
Pas d’expériences dans des conditions concrètes et pour la charge prévue.
-
Pas de traitement de vos expériences en tant que code ou de maintenance de vos expériences tout au long du cycle de développement.
-
Pas d’exécution d’expériences de chaos dans le cadre de votre pipeline CI/CD, ainsi qu’en dehors des déploiements.
-
Pas d’utilisation des analyses passées post-incident pour déterminer les défaillances à tester.
Avantages du respect de cette bonne pratique : l’injection de défaillances pour vérifier la résilience de votre charge de travail vous permet d’avoir l’assurance que les procédures de récupération de votre conception résiliente fonctionneront en cas de défaillances réelles.
Niveau d’exposition au risque si cette bonne pratique n’est pas respectée : moyen
Directives d’implémentation
L’ingénierie du chaos offre la possibilité à vos équipes d’injecter en continu des perturbations concrètes (simulations) de manière contrôlée au niveau du fournisseur de services, de l’infrastructure, de la charge de travail et des composants, avec peu ou pas d’impact pour vos clients. Ainsi, vos équipes tirent les leçons de ces défaillances et observent, mesurent et améliorent la résilience de vos charges de travail, tout en confirmant que les alertes se déclenchent et que les équipes sont informées en cas d’événement.
Une pratique de l’ingénierie du chaos en continu peut mettre en évidence des défaillances dans vos charges de travail qui, si elles ne sont pas résolues, peuvent impacter de manière négative la disponibilité et le fonctionnement.
Note
L’ingénierie du chaos est la discipline d’expérimentation d’un système. Elle permet de s’assurer de la capacité du système à résister à des conditions de production difficiles. – Principes de l’ingénierie du chaos
Si un système est capable de résister à ces perturbations, l’expérience de chaos doit être maintenue en tant que test de régression automatisé. De cette façon, les expériences de chaos doivent être réalisées dans le cadre de votre cycle de développement des systèmes et de votre pipeline CI/CD.
Pour veiller à ce que votre charge de travail résiste en cas de défaillance des composants, injectez des événements concrets dans le cadre de vos expériences. Par exemple, expérimentez une perte des instances Amazon EC2 ou un basculement de l’instance de base de données Amazon RDS principale, puis vérifiez que votre charge de travail n’est pas impactée (ou très peu). Utilisez plusieurs défaillances des composants pour simuler des événements capables de causer une perturbation dans une zone de disponibilité.
Pour les défaillances de niveau application (telles que les plantages), commencez par des tests de stress comme l’épuisement de la mémoire et du processeur.
Afin de valider des mécanismes de remplacement ou de basculement
D’autres modes de dégradation peuvent entraîner des fonctionnalités limitées et ralentir les réponses, ce qui se traduit par une perturbation de vos services. Généralement, cette dégradation résulte d’une latence accrue sur les services critiques et d’une communication réseau peu fiable (perte de paquets). Les expériences avec ces défaillances, dont les effets de mise en réseau tels que la latence, les messages supprimés et les défaillances DNS, peuvent inclure l’incapacité de résoudre un nom, d’atteindre un service DNS ou de se connecter aux services dépendants.
Outils de l’ingénierie du chaos :
AWS Fault Injection Service (AWS FIS) est un service entièrement géré permettant l’exécution d’expériences d’injection de pannes qui peuvent être utilisées dans le cadre de votre pipeline CD, ou en dehors du pipeline. AWS FIS s’impose donc comme un choix judicieux lors des tests de simulation de pannes. Il prend en charge l’introduction simultanée de défaillances sur différents types de ressources, notamment Amazon EC2, Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS) et Amazon RDS. Ces défaillances incluent l’arrêt des ressources, les basculements forcés, le stress du processeur ou de la mémoire, la limitation, la latence et la perte de paquets. Comme il est intégré aux alarmes Amazon CloudWatch, vous pouvez définir des conditions d’arrêt comme barrières de protection pour annuler une expérience si elle provoque un impact inattendu.
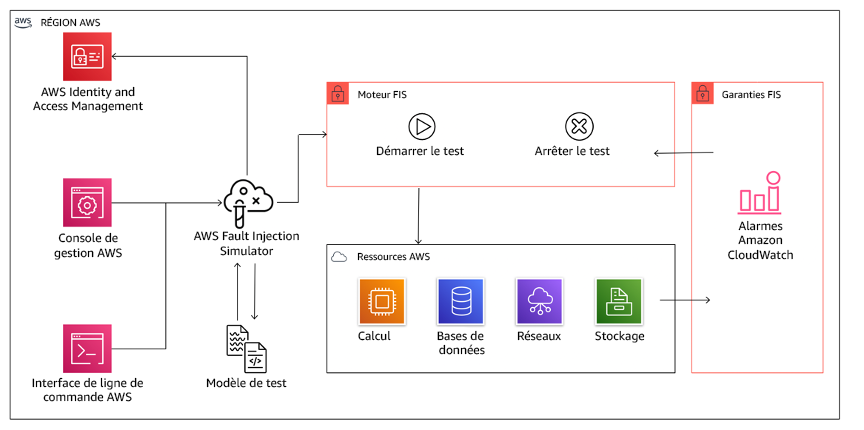
AWS Fault Injection Service s’intègre aux ressources AWS pour vous permettre d’exécuter des expériences d’injection de pannes pour vos charges de travail.
Il existe également plusieurs options tierces pour les expériences d’injection de pannes. Il s’agit notamment d’outils open source tels que Chaos Toolkit
Étapes d’implémentation
-
Déterminez les défaillances à utiliser pour les expériences.
Évaluez la conception de votre charge de travail à des fins de résilience. Ces conceptions (créées selon les bonnes pratiques du cadre Well-Architected) tiennent compte des risques basés sur les dépendances critiques, les événements passés, les problèmes connus et les exigences de conformité. Répertoriez chaque élément de la conception destiné à maintenir la résilience et les défaillances qu’il entend réduire. Pour plus d’informations sur la création de telles listes, consultez le livre blanc consacré à l’examen de la préparation opérationnelle, qui explique comment créer un processus visant à empêcher que de tels incidents ne se reproduisent. Le processus de Failure Modes and Effects Analysis (FMEA) ou d’analyse des modes de défaillance et de leurs effets vous propose un framework pour réaliser une analyse de niveau composant des défaillances et de leur impact sur votre charge de travail. Le FMEA est décrit plus en détail par Adrian Cockcroft dans Failure Modes and Continuous Resilience
. -
Attribuer une priorité à chaque défaillance.
Commencez par définir une classification grossière telle que élevée, moyenne et basse. Pour évaluer les priorités, tenez compte de la fréquence de la défaillance et de son impact sur la charge de travail dans son ensemble.
Lors de la prise en compte de la fréquence d’une défaillance donnée, analysez les données passées de cette charge de travail, le cas échéant. Si aucune donnée passée n’est disponible, utilisez les données des autres charges de travail s’exécutant dans un environnement semblable.
Lors de la prise en compte de l’impact d’une défaillance donnée, souvenez-vous qu’en général plus le champ de la défaillance est large, plus grand est l’impact. Tenez compte également de la conception de la charge de travail et de son objectif. Par exemple, la capacité à accéder aux magasins de données sources est essentielle pour une charge de travail effectuant des transformations et de l’analyse de données. Dans ce cas, vous donnerez la priorité aux expériences liées aux défaillances d’accès ainsi qu’aux accès limités et à l’insertion de la latence.
Les analyses post-incident constituent une excellente source de données pour comprendre à la fois la fréquence et l’impact des modes de défaillance.
Utilisez la priorité attribuée pour déterminer les défaillances à expérimenter en premier lieu, puis l’ordre dans lequel développer de nouvelles expériences d’injection de pannes.
-
Suivre le volant d’inertie de l’ingénierie du chaos et de la résilience continue figurant sur la figure suivante pour chaque expérience réalisée.
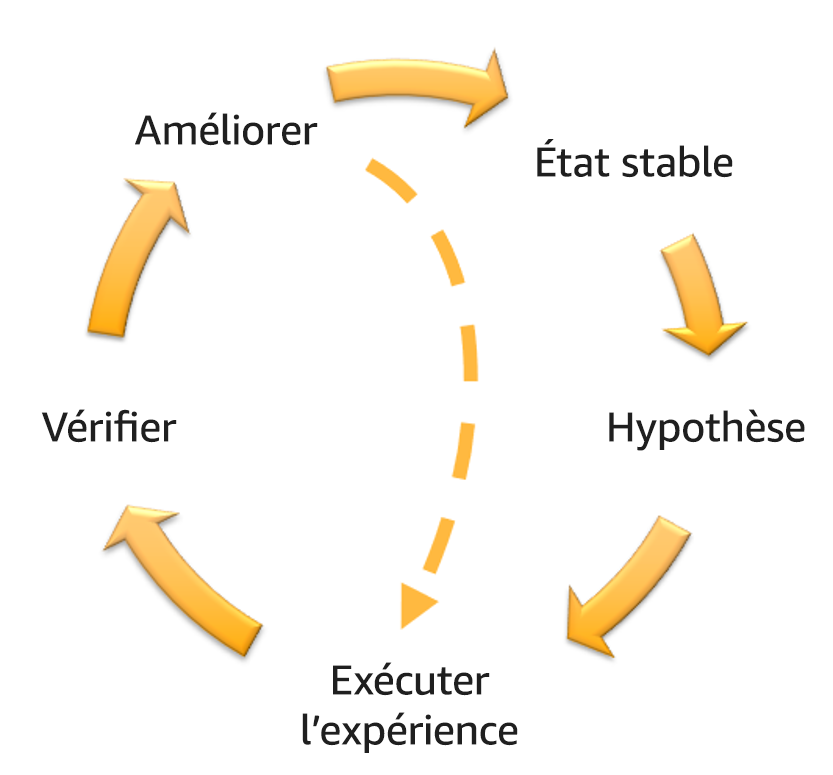
Volant d’inertie de l’ingénierie du chaos et de la résilience continue réalisé grâce à la méthode scientifique d’Adrian Hornsby.
-
Définir l’état stable comme le résultat mesurable d’une charge de travail qui indique un comportement normal.
Votre charge de travail présente un état stable si elle fonctionne de manière fiable et comme prévu. Par conséquent, confirmez que votre charge de travail est saine avant de définir un état stable. L’état stable ne signifie pas forcément sans impact pour la charge de travail en cas de défaillance, car un certain pourcentage des défaillances n’excède pas des limites supportables. L’état stable constitue le repère que vous observerez pendant l’expérience, qui mettra en évidence des anomalies si votre hypothèse formulée dans l’étape suivante ne donne pas les résultats escomptés.
Par exemple, un état stable d’un système de paiements peut être défini comme le traitement de 300 TPS avec un taux de réussite de 99 % et un temps de transmission aller-retour de 500 ms.
-
Formuler une hypothèse sur la façon dont la charge de travail réagira à la défaillance.
Une bonne hypothèse repose sur la façon dont la charge de travail est destinée à réduire la défaillance pour maintenir l’état stable. L’hypothèse indique que vu qu’il s’agit d’une défaillance d’un type particulier, le système ou la charge de travail maintiendra un état stable, car la charge de travail a été conçue avec une atténuation des risques spécifique. Le type particulier de défaillance et d’atténuation des risques doit être spécifié dans l’hypothèse.
Le modèle suivant peut être utilisé pour l’hypothèse (mais une autre formulation est aussi acceptable) :
Note
En cas de
panne spécifique, lenom de la charge de travaildécrira les contrôles d’atténuationvisant à maintenir l’impact des métriques commerciales ou techniques.Par exemple :
-
Si 20 % des nœuds du node-group Amazon EKS sont supprimés, l’API Transaction Create continue de répondre au 99e centile des demandes en moins de 100 ms (état stable). Les nœuds Amazon EKS seront opérationnels dans les cinq minutes, et les pods seront planifiés et traiteront le trafic huit minutes après le début de l’expérience. Les alertes se déclencheront sous trois minutes.
-
En cas de défaillance d’une seule instance Amazon EC2, la surveillance de l’état Elastic Load Balancing du système de commandes permet à Elastic Load Balancing d’envoyer uniquement des demandes aux instances saines restantes, tandis qu’Amazon EC2 Auto Scaling remplace l’instance en échec, tout en maintenant une augmentation des erreurs (5xx) côté serveur (état stable) inférieure à 0,01 %.
-
Si l’instance de base de données Amazon RDS principale échoue, la charge de travail de collecte des données Chaîne d’approvisionnement basculera et se connectera à l’instance de base de données Amazon RDS de secours pour maintenir les erreurs de lecture ou d’écriture de base de données (état stable) inférieures à 1 minute.
-
-
Exécuter l’expérience en injectant la défaillance.
Une expérience doit par défaut être sécurisée et tolérée par la charge de travail. Si vous savez que la charge de travail va échouer, n’exécutez pas l’expérience. L’ingénierie du chaos doit être utilisée pour rechercher les risques connus ou inconnus. Les risques connus sont des choses dont vous êtes conscient mais que vous ne comprenez pas complètement, et les risques inconnus sont des choses dont vous n’êtes pas conscient et que vous ne comprenez pas complètement. Exécuter une expérience sur une charge de travail que vous savez défaillante ne vous apportera rien de plus. Votre expérience doit être soigneusement préparée, disposer d’un champ d’impact défini et fournir un mécanisme de protection pouvant être appliqué en cas de perturbations inattendues. Si votre vérification préalable indique que votre charge de travail doit résister à l’expérience, exécutez cette dernière. Il existe plusieurs moyens d’injecter les défaillances. Pour les charges de travail sur AWS, AWS FIS fournit de nombreuses simulations de pannes prédéfinies appelées actions. Vous pouvez également définir des actions personnalisées qui s’exécutent dans AWS FIS à l’aide des documents AWS Systems Manager.
Nous déconseillons l’utilisation de scripts personnalisés pour les expériences de chaos, sauf si ces derniers sont capables de comprendre l’état actuel de la charge de travail, d’émettre des journaux, de fournir des mécanismes de protection pour annuler une expérience et des conditions d’arrêt dans la mesure du possible.
Un framework ou des outils efficaces capables de prendre en charge l’ingénierie du chaos doivent suivre l’état actuel d’une expérience, émettre des journaux et fournir des mécanismes de protection pour prendre en charge l’exécution contrôlée d’une expérience. Commencez par un service établi comme AWS FIS qui vous permet d’exécuter des expériences avec un champ clairement défini et des mécanismes de sécurité capables de protéger l’expérience en cas de perturbations inattendues. Pour en savoir plus sur une plus grande variété d’expériences utilisant AWS FIS, consultez également l’atelier Applications résilientes et Well-Architected avec l’ingénierie du chaos
. AWS Resilience Hub analysera votre charge de travail et créera des expériences que vous pourrez choisir d’implémenter et d’exécuter dans AWS FIS. Note
Pour chaque expérience, vous devez bien comprendre le champ et son impact. Nous recommandons que les défaillances soient d’abord simulées sur un environnement hors production avant d’être exécutées en production.
Les expériences doivent être menées en production sous une charge réelle à l’aide de déploiements Canary
qui permettent de déployer à la fois un système de contrôle et un déploiement de système expérimental, dans la mesure du possible. L’exécution d’expériences pendant les heures creuses est une bonne pratique pour réduire l’impact potentiel de la première expérience en production. De plus, si l’utilisation du trafic client réel s’avère trop risquée, vous pouvez exécuter des expériences à l’aide du trafic synthétique sur l’infrastructure de production pour des déploiements de système de contrôles et d’expériences. Lorsqu’une exécution en production n’est pas possible, exécutez les expériences dans des environnements de pré-production aussi proches que possible de la production. Vous devez définir des barrières de protection pour veiller à ce que l’expérience n’impacte pas le trafic de la production ou d’autres systèmes au-delà des limites acceptables. Définissez des conditions d’arrêt pour stopper une expérience si elle atteint le seuil d’une métrique de barrière de protection défini par vos soins. Ces conditions doivent inclure les métriques de l’état stable de la charge de travail, ainsi que celles sur les composants dans lesquels vous injectez la défaillance. Un moniteur synthétique (également appelée un utilisateur canary) est une métrique que vous devez généralement inclure en tant que proxy utilisateur. Les conditions d’arrêt de AWS FIS sont prises en charge dans le cadre d’un modèle de test, autorisant jusqu’à cinq conditions d’arrêt par modèle.
L’un des principes de l’ingénierie du chaos est de minimiser le champ de l’expérience et son impact :
Bien qu’un impact négatif à court terme soit autorisé, l’ingénieur du chaos a la responsabilité et l’obligation de minimiser et de maîtriser les conséquences des expériences.
Pour vérifier le champ et l’impact potentiel, vous pouvez dans un premier temps exécuter l’expérience dans un environnement hors production, en vérifiant que les seuils des conditions d’arrêt s’activent comme prévu pendant l’expérience et que l’observabilité est en place pour détecter une exception, plutôt que d’exécuter l’expérience directement en production.
Lorsque vous exécutez des expériences d’injection de pannes, vérifiez que toutes les parties responsables sont bien informées. Communiquez avec les équipes appropriées, telles que les équipes en charge des opérations, les équipes chargées de la fiabilité du service et le service client pour leur indiquer quand les expériences seront exécutées et à quoi ils doivent s’attendre. Donnez à ces équipes les outils de communication nécessaires pour informer les personnes en charge de l’exécution de l’expérience si elles constatent des effets négatifs.
Vous devez restaurer la charge de travail et ses systèmes sous-jacents dans leur état fonctionnel et connu d’origine. En général, la conception résiliente de la charge de travail lui permet de s’auto-réparer. Cependant, certaines conceptions défaillantes ou échecs d’expériences peuvent laisser votre charge de travail dans un état d’échec inattendu. À la fin de l’expérience, vous devez en être conscient et restaurer la charge de travail et les systèmes. Avec AWS FIS, vous pouvez définir une configuration de barrière de protection (également appelée post action) dans les paramètres d’action. Une post action restaure la cible dans l’état dans lequel elle se trouvait avant l’exécution de l’action. Qu’elles soient automatisées (comme lorsque vous utilisez AWS FIS) ou manuelles, ces post actions doivent faire partie d’un playbook décrivant la façon de détecter et de gérer les échecs.
-
Vérifier l’hypothèse.
Principes de l’ingénierie du chaos
donne des conseils sur la façon de vérifier l’état stable de votre charge de travail : Concentrez-vous sur le résultat mesurable d’un système, plutôt que sur les attributs internes du système. Les mesures de ce résultat sur une courte période de temps constituent un proxy pour l’état stable du système. Le débit général du système, les taux d’erreur et les centiles de latence peuvent tous être des métriques d’intérêt représentant un comportement d’état stable. En se focalisant sur les modèles de comportement systémique pendant les expériences, l’ingénierie du chaos vérifie que le système fonctionne, au lieu d’essayer de confirmer qu’il fonctionne.
Dans nos deux exemples précédents, nous incluons la métrique de l’état stable inférieure à 0,01 % d’augmentation des erreurs (5xx) côté serveur et la métrique inférieure à 1 minute d’erreurs de lecture ou d’écriture de base de données.
Les erreurs 5xx constituent une bonne métrique, car elles sont une conséquence du mode de défaillance dont le client de la charge de travail fera l’expérience directement. La mesure des erreurs de base de données est correcte en tant que conséquence directe de la défaillance, mais doit être également complétée par une mesure d’impact, telle que les échecs de demandes client ou les erreurs remontées. Par ailleurs, incluez une surveillance synthétique (également appelée utilisateur canary) sur n’importe quelle API ou URI directement accessible par le client de votre charge de travail.
-
Améliorer la conception de la charge de travail à des fins de résilience.
Si l’état stable n’a pas été maintenu, enquêtez sur les moyens d’améliorer la conception de la charge de travail afin de réduire la défaillance, tout en appliquant les bonnes pratiques du pilier AWS Well-Architected Reliability. Vous trouverez des conseils et des ressources supplémentaires dans la AWS Builder’s Library
, qui contient des articles sur la manière d’améliorer vos surveillances de l’état ou d’utiliser des nouvelles tentatives avec retard dans le code de votre application , entre autres. Une fois ces changements implémentés, exécutez de nouveau l’expérience (illustrée par la ligne pointillée dans le volant d’inertie de l’ingénierie du chaos) pour déterminer son efficacité. Si l’étape de vérification indique que l’hypothèse est vraie, alors la charge de travail sera en état stable et le cycle continuera.
-
-
Exécuter régulièrement des expériences.
Une expérience de chaos est un cycle, et les expériences doivent être exécutées régulièrement dans le cadre de l’ingénierie du chaos. Lorsqu’une charge de travail correspond à l’hypothèse d’une expérience, cette dernière doit être automatisée pour s’exécuter en continu en tant que test de régression de votre pipeline CI/CD. Pour savoir comment procéder, consultez ce blog sur la façon de mener des expériences AWS FIS à l’aide d’AWS CodePipeline
. Ce laboratoire sur les expériences AWS FIS récurrentes dans un pipeline CI/CD vous permet de travailler sur le terrain. Les expériences d’injection de pannes font également partie des tests de simulation de pannes (consultez REL12-BP05 Organiser régulièrement des tests de simulation de panne). Les tests de simulation de pannes simulent une défaillance ou un événement pour vérifier les systèmes, les processus et la réponse de l’équipe. L’objectif est d’effectuer les actions que l’équipe effectuerait si un événement exceptionnel se produisait.
-
Enregistrer et stocker les résultats des expériences.
Les résultats des expériences d’injection de pannes doivent être enregistrés et conservés. Incluez toutes les données nécessaires (telles que l’heure, la charge de travail et les conditions) afin de pouvoir analyser ultérieurement les résultats de l’expérience et les tendances. Les exemples de résultats peuvent inclure des captures d’écran des tableaux de bord, des fichiers CSV de la base de données de votre/vos métriques ou un registre manuscrit des événements et observations pendant l’expérience. La journalisation des expériences avec AWS FIS peut faire partie de cette capture de données.
Ressources
Bonnes pratiques associées :
Documents connexes :
Vidéos connexes :
Outils associés :
