REL10-BP03 Utiliser des architectures cloisonnées pour limiter la portée de l’impact
Mettez en œuvre des architectures de cloisonnement (également connues sous le nom d’architectures cellulaires) pour restreindre l’effet d’une panne au sein d’une charge de travail à un nombre limité de composants.
Résultat escompté : une architecture cellulaire utilise plusieurs instances isolées d’une charge de travail, chaque instance étant appelée cellule. Chaque cellule est indépendante, ne partage pas d’état avec les autres cellules et traite un sous-ensemble des demandes de la charge de travail globale. L’impact potentiel d’une défaillance, telle qu’une mauvaise mise à jour logicielle, sur une cellule individuelle et sur les demandes qu’elle traite est ainsi réduit. Si une charge de travail utilise 10 cellules pour traiter 100 demandes, lorsqu’une panne survient, 90 % des demandes globales ne sont pas affectées par la panne.
Anti-modèles courants :
-
Permettre aux cellules de se développer sans limites.
-
Appliquer des mises à jour ou des déploiements de code à toutes les cellules en même temps.
-
Partage de l’état ou des composants entre les cellules (à l’exception de la couche routeur).
-
Ajout d’une logique métier ou de routage complexe à la couche routeur.
-
Ne pas minimiser les interactions entre les cellules.
Avantages liés au respect de cette bonne pratique : avec les architectures cellulaires, de nombreux types de défaillances courants sont contenus dans la cellule elle-même, ce qui permet une isolation supplémentaire des pannes. Ces limites de défaillances peuvent apporter de la résilience face à des types de défaillances difficiles à contenir, tels que des déploiements de code infructueux ou des demandes corrompues ou invoquant un mode de défaillance spécifique (également appelées demandes de pilules empoisonnées).
Niveau d’exposition au risque si cette bonne pratique n’est pas respectée : élevé
Directives d’implémentation
Sur un navire, les cloisons permettent de contenir une brèche dans la coque dans une seule section de la coque. Dans les systèmes complexes, ce modèle est souvent répliqué pour permettre d’isoler des pannes. Les limites isolées pour les défaillances restreignent l’effet d’une panne au sein d’une charge de travail à un nombre limité de composants. Les composants situés en dehors du périmètre ne sont pas affectés par la défaillance. En utilisant plusieurs périmètres d’isolation des pannes, vous pouvez limiter l’impact sur votre charge de travail. Sur AWS, les clients peuvent utiliser plusieurs zones de disponibilité et régions pour isoler des pannes, mais le concept d’isolement des pannes peut également être étendu à l’architecture de votre charge de travail.
La charge de travail globale est divisée en cellules par une clé de partition. Celle-ci doit s’aligner sur la base de granularité du service, ou sur la manière naturelle dont la charge de travail d’un service peut être subdivisée avec un minimum d’interactions entre les cellules. Des exemples de clés de partition sont l’ID du client, l’ID de la ressource ou tout autre paramètre facilement accessible dans la plupart des appels d’API. Une couche de routage des cellules distribue les requêtes aux cellules individuelles en fonction de la clé de partition et présente un point de terminaison unique aux clients.
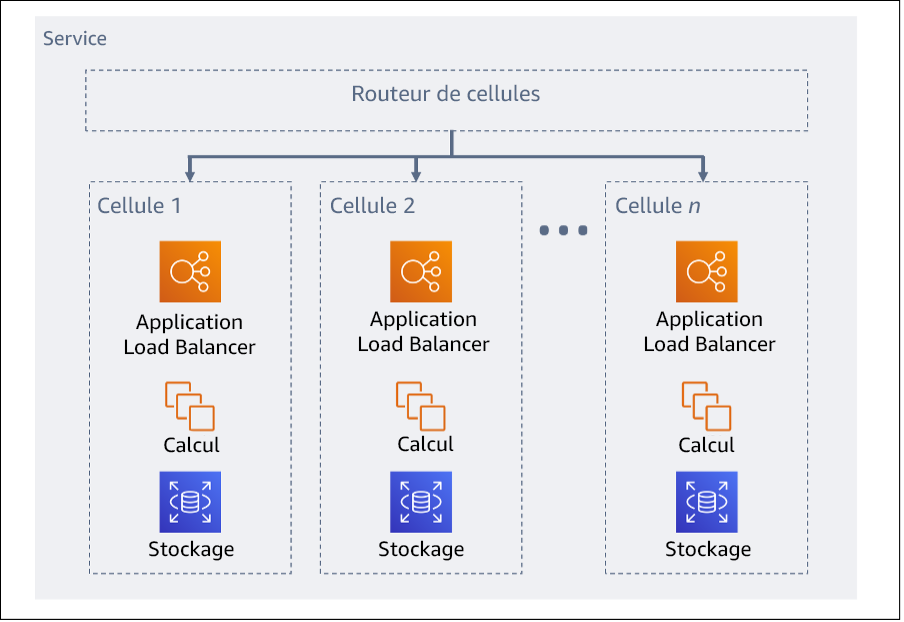
Figure 11 : architecture cellulaire
Étapes d’implémentation
Lors de la conception d’une architecture cellulaire, vous devez tenir compte de plusieurs éléments :
-
Clé de partition : une attention particulière doit être prise lors du choix de la clé de partition.
-
Celle-ci doit s’aligner sur la base de granularité du service, ou sur la manière naturelle dont la charge de travail d’un service peut être subdivisée avec un minimum d’interactions entre les cellules. Exemples :
customer IDouresource ID. -
La clé de partition doit être disponible dans toutes les requêtes, soit directement, soit d’une manière qui pourrait être facilement déduite de façon déterministe par d’autres paramètres.
-
-
Mappage cellulaire persistant : les services en amont ne doivent interagir qu’avec une seule cellule pendant le cycle de vie de leurs ressources.
-
En fonction de la charge de travail, vous devrez peut-être concevoir une stratégie de migration de cellules pour faire migrer les données d’une cellule à l’autre. La migration d’une cellule peut s’avérer nécessaire si un utilisateur ou une ressource particulière de votre charge de travail devient trop importante et nécessite une cellule dédiée.
-
Les cellules ne doivent pas partager d’état ou de composants entre elles.
-
Par conséquent, les interactions entre cellules doivent être évitées ou réduites au minimum, car elles créent des dépendances entre les cellules et diminuent donc les bénéfices de l’isolement des défaillances.
-
-
Couche routeur : la couche routeur est un composant partagé entre les cellules et ne peut donc pas suivre la même stratégie de compartimentage qu’avec les cellules.
-
Nous recommandons de paramétrer la couche routeur pour distribuer les requêtes à des cellules individuelles à l’aide d’un algorithme de mappage de partition d’une manière efficace sur le plan des calculs. Par exemple, en combinant des fonctions de hachage cryptographiques et de l’arithmétique modulaire pour mapper les clés de partition aux cellules.
-
Pour éviter les impacts sur plusieurs cellules, la couche de routage doit rester le plus simple possible et être doté d’une capacité de mise à l’échelle horizontale optimale, ce qui nécessite d’éviter toute logique métier complexe au sein de cette couche. L’avantage supplémentaire est qu’il est facile de comprendre le comportement attendu à tout moment, ce qui permet de réaliser des tests approfondis. Comme l’explique Colm MacCárthaigh dans Fiabilité, travail constant et une bonne tasse de café
, des conceptions simples et des modèles de travail constants produisent des systèmes fiables et réduisent la fragilité.
-
-
Taille des cellules : les cellules doivent avoir une taille maximale et ne doivent pas être autorisées à croître au-delà de cette taille.
-
La taille maximale doit être identifiée en effectuant des tests approfondis, jusqu’à ce que les points de rupture soient atteints et que des marges de fonctionnement sûres soient établies. Pour en savoir plus sur la mise en œuvre des pratiques de test, consultez REL07-BP04 Testez votre charge de travail
-
La charge de travail globale doit se développer en ajoutant des cellules supplémentaires, ce qui lui permet de s’adapter à l’augmentation de la demande.
-
-
Stratégies multi-AZ ou multi-régions : plusieurs niveaux de résilience doivent être exploités pour se protéger contre différents domaines de défaillance.
-
Pour la résilience, vous devez adopter une approche qui repose sur des couches de défense. Une couche protège contre les perturbations de petite envergure et courantes en créant une architecture hautement disponible à l’aide de plusieurs AZ. Une autre couche de défense est destinée à protéger contre les événements rares tels que les catastrophes naturelles généralisées et les perturbations au niveau régional. Cette deuxième couche implique de concevoir l’architecture de votre application pour qu’elle s’étende sur plusieurs Régions AWS. La mise en œuvre d’une stratégie multi-région pour votre charge de travail permet de la protéger contre les catastrophes naturelles généralisées qui affectent une grande région géographique d’un pays, ou les défaillances techniques à l’échelle régionale. Sachez que la mise en œuvre d’une architecture multi-région peut être très complexe et n’est généralement pas requise pour la plupart des charges de travail. Pour en savoir plus, veuillez consulter REL10-BP01 Déploiement de la charge de travail sur plusieurs emplacements.
-
-
Déploiement du code : une stratégie de déploiement de code échelonnée doit être préférée au déploiement de modifications de code dans toutes les cellules en même temps.
-
Les risques de panne de plusieurs cellules sont ainsi réduits en raison d’un mauvais déploiement ou d’une erreur humaine. Pour en savoir plus, consulter Automatiser un déploiement sûr et sans intervention
.
-
Ressources
Bonnes pratiques associées :
Documents connexes :
Vidéos connexes :
-
AWS re:Invent 2018: Close Loops and Opening Minds: How to Take Control of Systems, Big and Small
-
AWS re:Invent 2018: How AWS Minimizes the Blast Radius of Failures (ARC338)
-
Shuffle-sharding: AWS re:Invent 2019: Introducing The Amazon Builders’ Library (DOP328)
-
AWS Summit ANZ 2021 - Everything fails, all the time: Designing for resilience
