Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Disponibilité avec redondance
Lorsqu'une charge de travail utilise plusieurs sous-systèmes indépendants et redondants, elle peut atteindre un niveau de disponibilité théorique plus élevé qu'en utilisant un seul sous-système. Prenons l'exemple d'une charge de travail composée de deux sous-systèmes identiques. Il peut être complètement opérationnel si le sous-système 1 ou le sous-système 2 est opérationnel. Pour que l'ensemble du système soit hors service, les deux sous-systèmes doivent être hors service en même temps.
Si la probabilité de défaillance d'un sous-système est de 1 − α, la probabilité que deux sous-systèmes redondants soient en panne en même temps est le produit de la probabilité de défaillance de chaque sous-système, F = (1− α1) × (1− α). 2 Pour une charge de travail comportant deux sous-systèmes redondants, l'équation (3) permet d'obtenir une disponibilité définie comme suit :

Équation 5
Ainsi, pour deux sous-systèmes dont la disponibilité est de 99 %, la probabilité que l'un tombe en panne est de 1 % et la probabilité que les deux échouent est de (1− 99 %) × (1− 99 %) = 0,01 %. Cela porte la disponibilité à 99,99 % à l'aide de deux sous-systèmes redondants.
Cela peut être généralisé pour intégrer également des pièces de rechange redondantes supplémentaires. Dans l'équation (5), nous n'avons supposé qu'une seule réserve, mais une charge de travail peut en comporter deux, trois ou plus, de sorte qu'elle puisse survivre à la perte simultanée de plusieurs sous-systèmes sans affecter la disponibilité. Si une charge de travail comporte trois sous-systèmes et que deux sont des sous-systèmes de rechange, la probabilité que les trois sous-systèmes tombent en panne en même temps est de (1− α) × (1− α) × (1− α) ou (1− α) 3. En général, une charge de travail avec s spare échouera uniquement si les sous-systèmes s + 1 tombent en panne.
Pour une charge de travail comportant n sous-systèmes et s pièces de rechange, f est le nombre de modes de défaillance ou la manière dont s + 1 sous-systèmes peuvent tomber en panne sur n.
Il s'agit en fait du théorème binomial, du calcul combinatoire qui consiste à choisir k éléments dans un ensemble de n, ou « n choisit k ». Dans ce cas, k est s + 1.
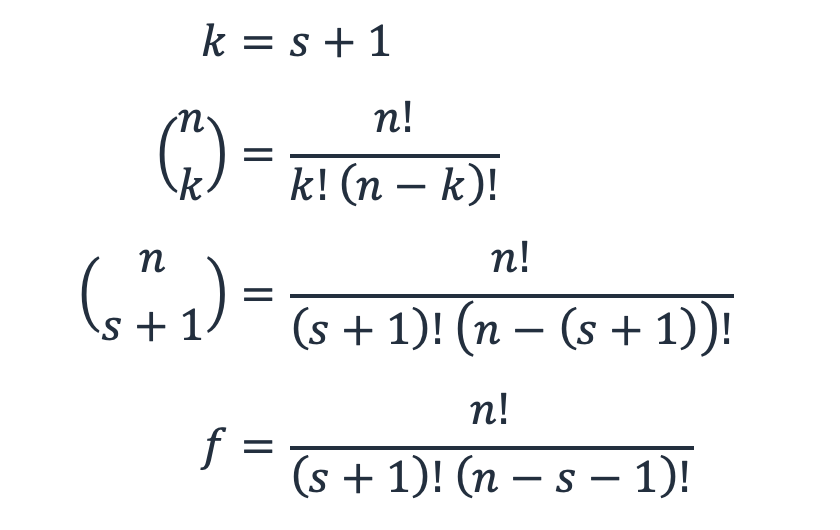
Équation 6
Nous pouvons ensuite produire une approximation de disponibilité généralisée qui intègre le nombre de modes de défaillance et le nombre de modes d'épargne. (Pour comprendre pourquoi il s'agit d'une approximation, reportez-vous à l'annexe 2 de Highleyman, et al. Briser la barrière de disponibilité
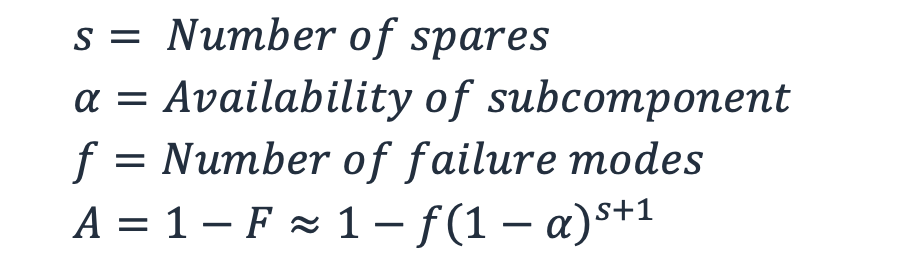
Équation 7
L'épargne peut être appliquée à toute dépendance fournissant des ressources défaillantes de manière indépendante. Les instances Amazon EC2 situées dans différentes zones de disponibilité ou les compartiments Amazon S3 situés dans des zones différentes en Régions AWS sont des exemples. L'utilisation de pièces de rechange permet à cette dépendance d'atteindre une disponibilité totale plus élevée afin de répondre aux objectifs de disponibilité de la charge de travail.
Règle 5
Utilisez l'épargne pour augmenter la disponibilité des dépendances dans une charge de travail.
Cependant, l'épargne a un coût. Chaque pièce de rechange supplémentaire coûte le même prix que le module d'origine, le coût étant au moins linéaire. La création d'une charge de travail pouvant utiliser des pièces de rechange augmente également sa complexité. Il doit savoir comment identifier les défaillances liées à la dépendance, affecter le travail à une ressource saine et gérer la capacité globale de la charge de travail.
La redondance est un problème d'optimisation. Si le nombre de pièces de rechange est insuffisant, la charge de travail risque d'échouer plus fréquemment que prévu, le nombre de pièces de rechange est trop élevé et l'exécution de la charge de travail est trop coûteuse. Il existe un seuil à partir duquel l'ajout de pièces de rechange coûtera plus cher que la disponibilité supplémentaire pour laquelle elles sont garanties.
En utilisant notre formule de disponibilité générale avec des pièces de rechange, équation (7), pour un sous-système dont la disponibilité est de 99,5 %, avec deux pièces de rechange, la disponibilité de la charge de travail est A ≈ 1 − (1) (1−0,995) 3 = 99,9999875 % (environ 3,94 secondes d'indisponibilité par an), et avec 10 pièces de rechange, nous obtenons A ≈ 1 − (1) (1−0,995) 11 = 25,5 9 ′ s (environ le temps d'arrêt serait de 1,26252 × 10 −15 m s par an, soit effectivement 0). En comparant ces deux charges de travail, nous avons multiplié par 5 le coût des pièces de rechange, ce qui nous a permis de réduire de quatre secondes les temps d'arrêt par an. Pour la plupart des charges de travail, l'augmentation des coûts ne serait pas justifiée pour cette augmentation de la disponibilité. La figure suivante illustre cette relation.
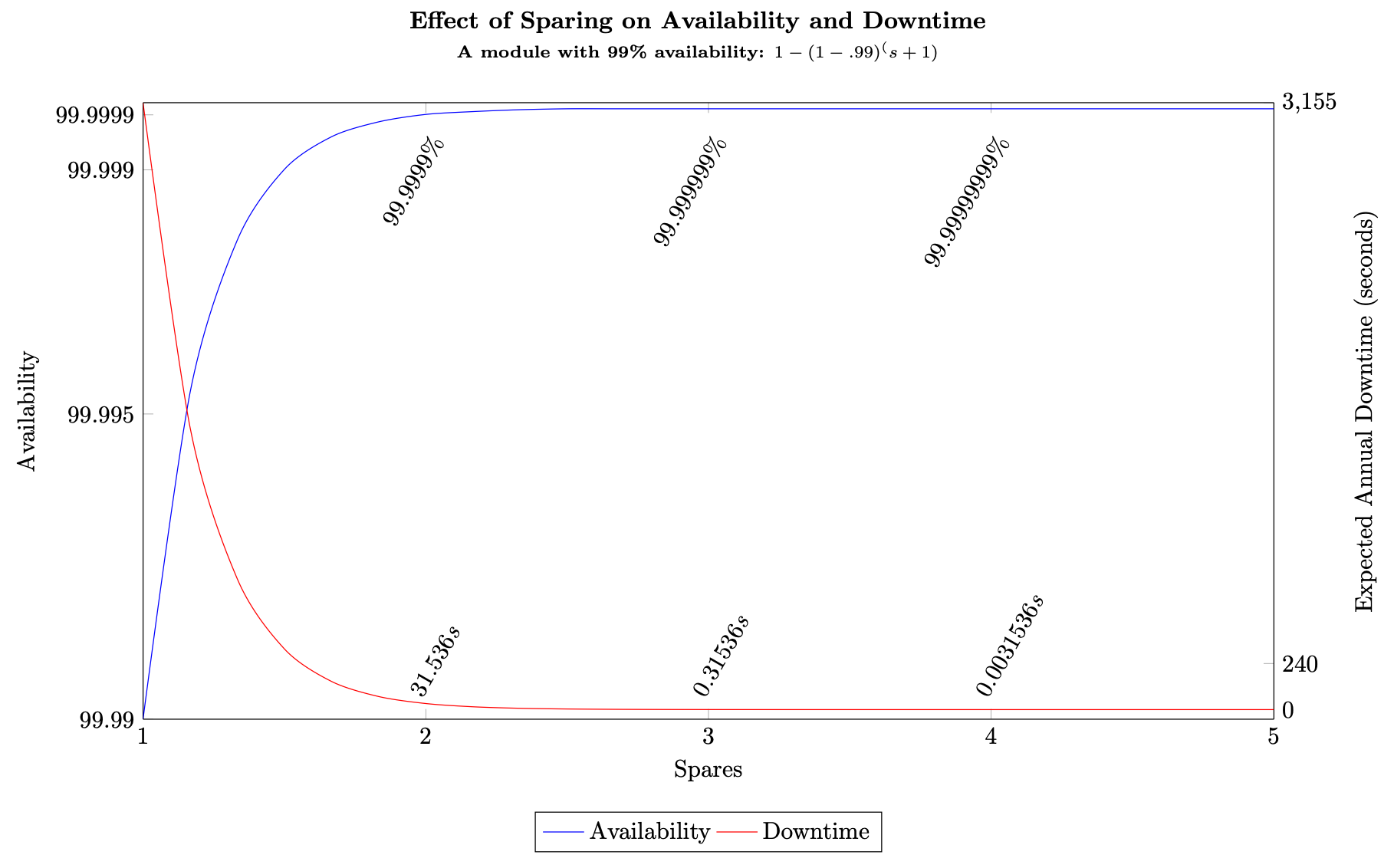
Rendements décroissants en raison de l'augmentation de l'épargne
À trois pièces de rechange et plus, le résultat est une fraction de seconde d'indisponibilité prévue par an, ce qui signifie qu'après ce point, vous atteignez la zone des rendements décroissants. Il peut y avoir une envie de « simplement en ajouter » pour atteindre des niveaux de disponibilité plus élevés, mais en réalité, le rapport coût-avantage disparaît très rapidement. L'utilisation de plus de trois pièces de rechange n'apporte aucun gain matériel et notable pour presque toutes les charges de travail lorsque le sous-système lui-même est disponible à au moins 99 %.
Règle 6
Il existe une limite supérieure à la rentabilité de l'épargne. Utilisez le moins de pièces de rechange nécessaires pour atteindre la disponibilité requise.
Vous devez tenir compte de l'unité de défaillance lorsque vous sélectionnez le nombre correct de pièces de rechange. Par exemple, examinons une charge de travail qui nécessite 10 instances EC2 pour gérer la capacité maximale et qui sont déployées dans une seule zone de disponibilité.
Les zones Z étant conçues pour être des limites d'isolation des pannes, l'unité de défaillance n'est pas une seule instance EC2, car une instance EC2 complète peut tomber en panne en même temps. Dans ce cas, vous souhaiterez ajouter de la redondance avec un autre AZ, en déployant 10 instances EC2 supplémentaires pour gérer la charge en cas de défaillance d'AZ, pour un total de 20 instances EC2 (suivant le schéma de stabilité statique).
Bien qu'il s'agisse apparemment de 10 instances EC2 de rechange, il ne s'agit en réalité que d'une seule AZ de rechange. Nous n'avons donc pas dépassé le point de baisse des rendements. Cependant, vous pouvez être encore plus rentable tout en augmentant votre disponibilité en utilisant trois AZ et en déployant cinq instances EC2 par AZ.
Cela fournit à une zone de réserve un total de 15 instances EC2 (contre deux zones de 20 instances), tout en fournissant les 10 instances nécessaires pour répondre aux pics de capacité lors d'un événement ayant un impact sur une seule zone de disponibilité. Vous devez donc intégrer l'épargne pour être tolérant aux pannes au-delà de toutes les limites d'isolation des pannes utilisées par la charge de travail (instance, cellule, AZ et région).
