Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Mesurer la disponibilité
Comme nous l'avons vu précédemment, la création d'un modèle de disponibilité prospectif pour un système distribué est difficile à réaliser et risque de ne pas fournir les informations souhaitées. Ce qui peut s'avérer plus utile, c'est de développer des méthodes cohérentes pour mesurer la disponibilité de votre charge de travail.
La définition de la disponibilité en termes de disponibilité et d'indisponibilité représente l'échec en tant qu'option binaire, que la charge de travail soit élevée ou non.
Toutefois, c'est rarement le cas. Les défaillances ont un certain degré d'impact et se produisent souvent dans certains sous-ensembles de la charge de travail, affectant un pourcentage d'utilisateurs ou de demandes, un pourcentage d'emplacements ou un centile de latence. Ce sont tous des modes de défaillance partielle.
Bien que le MTTR et le MTBF soient utiles pour comprendre ce qui détermine la disponibilité d'un système et, par conséquent, comment l'améliorer, leur utilité n'est pas une mesure empirique de la disponibilité. En outre, les charges de travail sont composées de nombreux composants. Par exemple, une charge de travail telle qu'un système de traitement des paiements est composée de nombreuses interfaces de programmation d'applications (API) et de sous-systèmes. Ainsi, lorsque nous voulons poser une question telle que « quelle est la disponibilité de l'ensemble de la charge de travail ? » , il s'agit en fait d'une question complexe et nuancée.
Dans cette section, nous allons examiner trois manières de mesurer la disponibilité de manière empirique : le taux de réussite des demandes côté serveur, le taux de réussite des demandes côté client et les interruptions annuelles.
Taux de réussite des demandes côté serveur et côté client
Les deux premières méthodes sont très similaires et ne diffèrent que du point de vue de la mesure. Les métriques côté serveur peuvent être collectées à partir de l'instrumentation du service. Cependant, ils ne sont pas complets. Si les clients ne sont pas en mesure d'accéder au service, vous ne pouvez pas collecter ces statistiques. Pour comprendre l'expérience client, au lieu de se fier aux données télémétriques des clients concernant les demandes ayant échoué, il est plus facile de collecter des statistiques côté client en simulant le trafic client à l'aide de canaries, un logiciel qui analyse régulièrement vos services et enregistre des indicateurs.
Ces deux méthodes calculent la disponibilité comme la fraction du total des unités de travail valides que le service reçoit et de celles qu'il traite avec succès (cela ignore les unités de travail non valides, comme une requête HTTP qui entraîne une erreur 404).

Équation 8
Pour un service basé sur des requêtes, l'unité de travail est la requête, comme une requête HTTP. Pour les services basés sur des événements ou des tâches, les unités de travail sont des événements ou des tâches, comme le traitement d'un message à partir d'une file d'attente. Cette mesure de la disponibilité est significative dans des intervalles de temps courts, tels que des fenêtres d'une minute ou de cinq minutes. Il convient également mieux d'un point de vue granulaire, par exemple au niveau de l'API pour un service basé sur des demandes. La figure suivante donne un aperçu de ce à quoi pourrait ressembler la disponibilité au fil du temps lorsqu'elle est calculée de cette manière. Chaque point de données du graphique est calculé à l'aide de l'équation (8) sur une fenêtre de cinq minutes (vous pouvez choisir d'autres dimensions temporelles, comme des intervalles d'une minute ou de dix minutes). Par exemple, le point de données 10 indique une disponibilité de 94,5 %. Cela signifie que pendant les minutes t+45 à t+50, si le service a reçu 1 000 demandes, seules 945 d'entre elles ont été traitées avec succès.
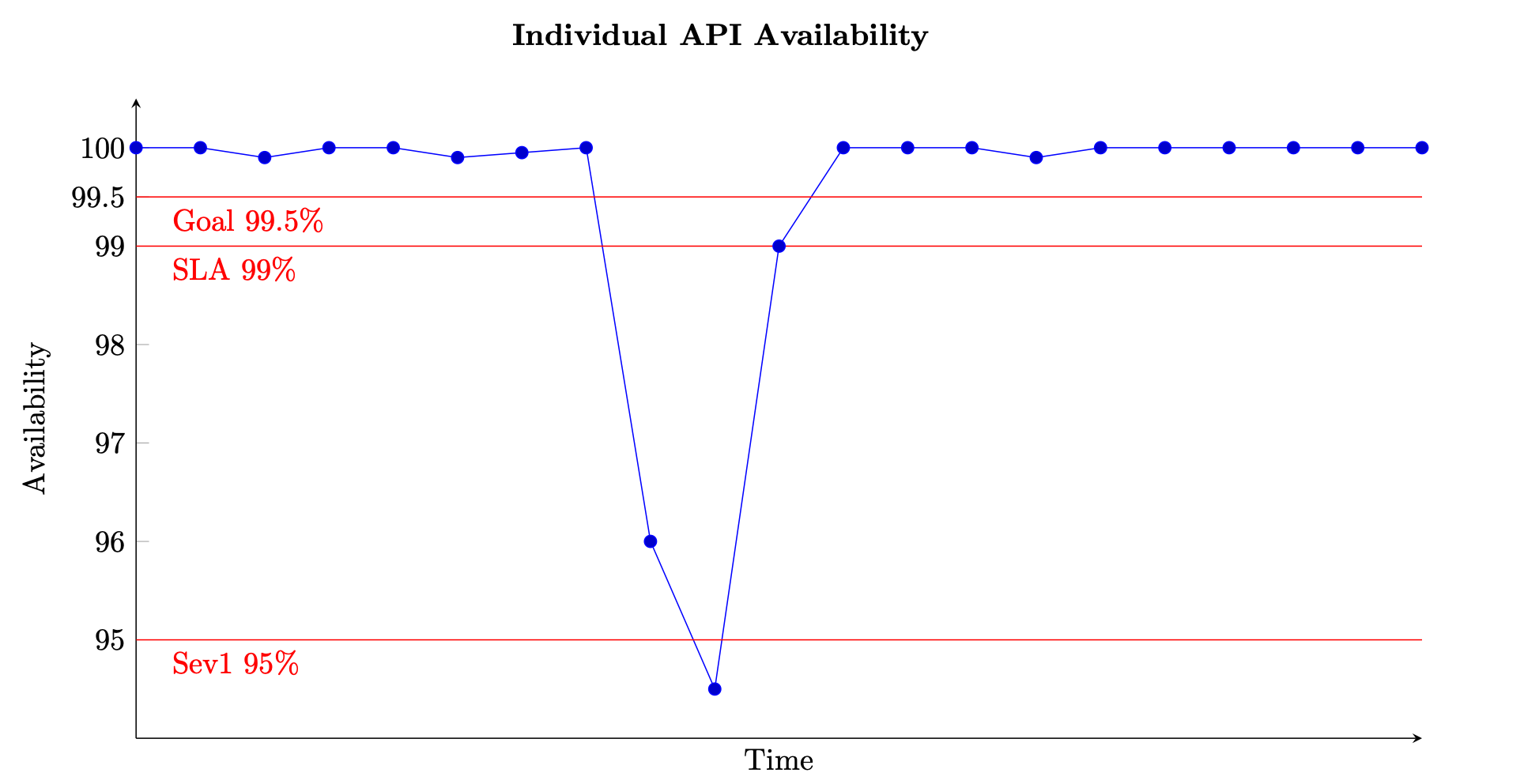
Exemple de mesure de la disponibilité au fil du temps pour une seule API
Le graphique montre également l'objectif de disponibilité de l'API, 99,5 % de disponibilité, le contrat de niveau de service (SLA) qu'elle propose aux clients, 99 % de disponibilité et le seuil d'alerte de gravité élevée, 95 %. Sans le contexte de ces différents seuils, un graphique de disponibilité risque de ne pas fournir d'informations significatives sur le fonctionnement de votre service.
Nous voulons également être en mesure de suivre et de décrire la disponibilité d'un sous-système plus important, tel qu'un plan de contrôle ou un service complet. Pour ce faire, vous pouvez notamment prendre la moyenne de chaque point de données de cinq minutes pour chaque sous-système. Le graphique ressemblera au précédent, mais sera représentatif d'un plus grand ensemble d'entrées. Il accorde également le même poids à tous les sous-systèmes qui constituent votre service. Une autre approche pourrait consister à additionner toutes les demandes reçues et traitées avec succès par toutes les API du service afin de calculer la disponibilité par intervalles de cinq minutes.
Toutefois, cette dernière méthode peut masquer une API individuelle présentant un faible débit et une mauvaise disponibilité. À titre d'exemple simple, considérons un service doté de deux API.
La première API reçoit 1 000 000 de requêtes dans une fenêtre de cinq minutes et traite avec succès 999 000 d'entre elles, soit une disponibilité de 99,9 %. La seconde API reçoit 100 demandes dans cette même fenêtre de cinq minutes et n'en traite que 50 avec succès, soit une disponibilité de 50 %.
Si nous additionnons les requêtes de chaque API, il y a 1 000 100 demandes valides au total et 999 050 d'entre elles sont traitées avec succès, soit une disponibilité de 99,895 % pour l'ensemble du service. Mais si nous faisons la moyenne des disponibilités des deux API, selon la première méthode, nous obtenons une disponibilité de 74,95 %, ce qui est peut-être plus révélateur de l'expérience réelle.
Aucune de ces approches n'est erronée, mais elle montre à quel point il est important de comprendre ce que les indicateurs de disponibilité vous indiquent. Vous pouvez choisir de privilégier la somme des demandes pour tous les sous-systèmes si votre charge de travail reçoit un volume de demandes similaire pour chacun d'entre eux. Cette approche met l'accent sur la « demande » et son succès en tant que mesure de la disponibilité et de l'expérience client. Vous pouvez également choisir de faire la moyenne des disponibilités des sous-systèmes afin de représenter de manière égale leur criticité malgré les différences de volume de demandes. Cette approche met l'accent sur le sous-système et sur la capacité de chacun d'entre eux en tant que proxy de l'expérience client.
Indisponibilité annuelle
La troisième approche consiste à calculer les temps d'arrêt annuels. Cette forme de mesure de disponibilité est plus appropriée à l'établissement et à l'examen d'objectifs à long terme. Cela nécessite de définir ce que les temps d'arrêt signifient pour votre charge de travail. Vous pouvez ensuite mesurer la disponibilité en fonction du nombre de minutes pendant lesquelles la charge de travail n'était pas en « panne » par rapport au nombre total de minutes au cours de la période donnée.
Certaines charges de travail peuvent définir l'indisponibilité comme une baisse en dessous de 95 % de la disponibilité d'une seule API ou d'une fonction de charge de travail pendant un intervalle d'une minute ou cinq minutes (ce qui s'est produit dans le graphique de disponibilité précédent). Vous pouvez également ne prendre en compte les temps d'arrêt que dans la mesure où ils s'appliquent à un sous-ensemble d'opérations critiques du plan de données. Par exemple, le contrat de niveau de service Amazon Messaging (SQS, SNS)
Des charges de travail plus importantes et plus complexes peuvent nécessiter la définition de mesures de disponibilité à l'échelle du système. Pour un site de commerce électronique de grande envergure, un indicateur à l'échelle du système peut être quelque chose comme le taux de commandes des clients. Dans ce cas, une baisse de 10 % ou plus des commandes par rapport à la quantité prévue au cours d'une fenêtre de cinq minutes peut définir un temps d'arrêt.
Quelle que soit l'approche choisie, vous pouvez ensuite additionner toutes les périodes de panne pour calculer une disponibilité annuelle. Par exemple, si au cours d'une année civile, il y a eu 27 périodes d'indisponibilité de cinq minutes, définies comme la disponibilité d'une API de plan de données inférieure à 95 %, le temps d'arrêt total était de 135 minutes (certaines périodes de cinq minutes pouvaient être consécutives, d'autres isolées), soit une disponibilité annuelle de 99,97 %.
Cette méthode supplémentaire de mesure de la disponibilité peut fournir des données et des informations absentes des indicateurs côté client et côté serveur. Prenons l'exemple d'une charge de travail altérée et présentant des taux d'erreur très élevés. Les clients soumis à cette charge de travail peuvent cesser complètement d'appeler ses services. Peut-être ont-ils activé un disjoncteur ou suivi leur plan de reprise après sinistre
Latence
Enfin, il est également important de mesurer la latence des unités de traitement du travail au sein de votre charge de travail. La définition de la disponibilité consiste en partie à effectuer le travail dans le cadre d'un SLA établi. Si le retour d'une réponse prend plus de temps que le délai imparti au client, le client a l'impression que la demande a échoué et que la charge de travail n'est pas disponible. Toutefois, côté serveur, la demande peut sembler avoir été traitée avec succès.
La mesure de la latence fournit un autre angle d'évaluation de la disponibilité. L'utilisation de percentiles et d'une moyenne tronquée est une bonne statistique pour cette mesure. Ils sont généralement mesurés au 50e percentile (P50 et TM50) et au 99e percentile (P99 et TM99). La latence doit être mesurée à l'aide de canaries pour représenter l'expérience client ainsi qu'à l'aide de métriques côté serveur. Chaque fois que la moyenne d'un certain centile de latence, comme P99 ou TM99.9, dépasse un SLA cible, vous pouvez prendre en compte ce temps d'arrêt, qui contribue à votre calcul annuel des temps d'arrêt.
