Additional considerations
PySpark vs. Python Shell vs. Scala
AWS Glue ETL scripts can be coded in Python or Scala. Python scripts use a language that is an extension of the PySpark Python dialect for ETL jobs. The script contains extended constructs to deal with ETL transformations. When you automatically generate the source code logic for your job, a script is created. You can edit this script, or you can provide your own script to process your ETL work.
Python shell
AWS Glue ETL supports running plain non-distributed Python scripts as a shell script to run small to medium-sized generic tasks that are often part of an ETL workflow. For example, to submit SQL queries to services such as Amazon Redshift, Amazon Athena, or Amazon EMR, or run machine learning (ML) and scientific analyses.
Python shell jobs in AWS Glue come pre-loaded with libraries
such as
Boto3
You can run Python shell jobs using one Data Processing Unit (DPU) or 0.0625 DPU (which is 1/16 DPU), allowing you to run cost effective small to medium jobs that does not require Spark runtime.
Compared to AWS Lambda, which has a strict 15-minute maximum timeout, AWS Glue Python Shell can be configured with a much longer timeout and higher memory, often required for data engineering jobs.
PySpark jobs
AWS Glue version 2.0 and later (PySpark and Scala) provides an upgraded infrastructure for running Apache Spark ETL jobs in AWS Glue with reduced startup times. With the reduced wait times, data engineers can be more productive and increase their interactivity with AWS Glue. The reduced variance in job start times can help you with your SLAs of making data available for analytics.
AWS Glue PySpark extensions of Apache Spark provides additional capabilities and convenience functions to manipulate data. For example, PySpark extensions such as Dynamic Dataframe, Relationalize, FindMatches, FillMissingValues, and so on can be used to easily enrich transform and normalize data with few lines of code. For more information, refer to the AWS Glue PySpark Transforms Reference.
Scala jobs
AWS Glue provides high-level APIs in Scala and Python for scripting ETL Spark jobs. Customers who use Scala as their primary language to develop Spark jobs can now run those jobs on AWS Glue with little or no changes to their code. AWS Glue provides all PySpark equivalent extension libraries in Scala as well, such as Dynamic DataFrame, Relationalize, and so on. You can take full benefit of these extensions in both Scala and PySpark based ETL jobs.
Comparison chart
Table 6 — Comparing available AWS Glue ETL programing languages
| Topic | Glue PySpark | Glue Scala | Glue Python Shell |
|---|---|---|---|
| Batch job DPUs | Minimum two, default ten | Minimum two, default 10 | Minimum 0.0625, maximum one, default 0.0625 |
| Batch job billing duration | Per second billing, minimum of one minute | Per second billing, minimum of one minute | Per second billing, minimum of one minute |
| Streaming job DPUs | Minimum two, default five | Minimum two, default five | N/A |
| Glue worker type | Standard (about to be deprecated in favor of AWS Glue 1.x), AWS Glue 1.x, AWS Glue 2.X (memory intensive jobs) | Standard (about to be deprecated in favor of AWS Glue 1.x), AWS Glue 1.x, AWS Glue 2.X (memory intensive jobs) | N/A |
| Streaming job billing duration | Per second billing, minimum of ten minutes | Per second billing, minimum of ten minutes | N/A |
| Language | Python | Scala | Python |
| Visual authoring | Yes (AWS Glue Studio) | No | No |
| Additional libraries | S3, Pip | S3 | S3 |
| Typical use case | Big data ETL, ML transforms | Big data ETL, ML transforms |
Data integration jobs that typically do not need to run in a distributed environment (such as REST API calls, Amazon Redshift SQL queries, and so on) |
| Spark runtime | 2.2, 2.4, and 3.1 | 2.2, 2.4, and 3.1 | N/A |
| AWS Glue Studio support (visual authoring) | Yes | No | No |
| Notebook development support | Yes | Yes | Yes |
Custom classifiers
Classifiers in AWS Glue are mechanisms that help the crawlers
determine the schema of our data. In most cases the default
classifiers work well and suits the requirements. However, there
are scenarios where we have to author our own customer
classifiers. For example, log files that may not fall into regular
CSV/JSON or XML messages, but would need a
GROK
Once attached to a crawler, a custom classifier is executed before the built-in classifiers. If the data is matched, the classification and schema is returned to the crawler, which is used to create the target tables.
Glue allows you to create custom classifiers for CSV, XML, JSON, and GROK-based datasets. In this document, we will explore how to create a classifier for a given dataset.
Assume you have a log file with the following structure:
2017-03-30npelling04C-50-CC-BB-F9-57/erat/nulla/tempus/vivamus.jpg
In this scenario, the data is unstructured, but you can apply a GROK expressions, such as a named regular expression (regex), to parse it to the form you want.
The target data structure is:
Table 7 — Expected data structure for log data
| Column name | Sample value |
|---|---|
log_year
|
2017 |
log_month
|
03 |
log_day
|
30 |
username
|
npelling |
mac_address
|
04C-50-CC-BB-F9-57 |
referer_url
|
/erat/nulla/tempus/vivamus.jpg |
The corresponding GROK expression is as follows:
%{YEAR:log_year}-%{MONTHNUM:log_month}- %{MONTHDAY:log_day}%{USERNAME:username} %{WINDOWSMAC:mac_address}%{URIPATH:referer_url}
When working with a GROK pattern, you can use many built-in patterns that AWS Glue provides, or you can define your own.
Creating a custom classifier
Let’s look at how to create a custom classifier from the previous GROK expression. Keep in mind that you can also create JSON, CSV, or XML-based custom classifiers, but we are limiting the scope of this document to a GROK-based example.
To create a custom classifier:
-
From the AWS Glue console, choose Classifiers.

From the AWS Glue console, choose Classifiers
-
Choose Add Classifier and use the form to add the details.

From the AWS Glue console, choose Add classifier
-
Options in the form vary based on our choice of the classifier type. In this case, use the Grok Classifier. Following is an instance of the form updated to meet our parsing requirements. Choose Create to create the classifier.

Fill in the forms to create the classifier
Adding the classifier to a crawler
Now that we have created the classifier, the next step is to attach this to a crawler.
To add the classifier to a crawler:
-
On the Create crawler window in the AWS Glue console, choose and expand the Tags, description, security configuration, and classifiers (optional) section.

Choose and expand the Tags, description, security configuration, and classifiers (optional) section.
-
Scroll down to the Classifiers section, and choose Add (close to the classifier we just created).
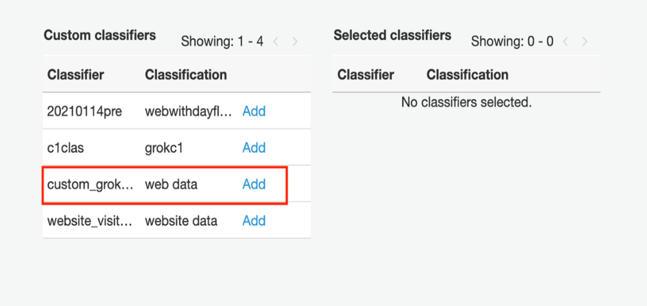
Scroll down to the Classifiers section and choose Add
The classifier should appear on the right side of the screen. You can complete the remaining crawler configurations, run it, and observe the target table it created:

The classifier appears

Schema of log data identified by classifier

Parsed log data
Incremental data pipeline
In the modern world of data engineering, one of the most common requirements is to store the data in its raw format and enabling a variety of consumption patterns (analytics, reporting, search, ML, and so on) on it. The data being ingested is typically of two types:
-
Immutable data such as social network feeds, Internet of Things (IoT) sensor data, log files, and so on.
-
Mutable data that is updated or deleted in transactional systems such as enterprise resource planning (ERP) or online transaction processing (OLTP) databases.
The need for data in its raw format leads to a huge volume of data being processed and engineered in an integration solution. Loading data incrementally (or delta) in the form of batches after an initial full data load is a widely accepted approach for such scenarios. The idea is to identify and extract only the newly added or updated records in tables in a source system instead of dealing with the entire table data. It reduces the volume of data being moved/processed during each load and results in efficient processing of data pipelines. Following are some of the ways of loading data incrementally.
-
Change tracking/CDC — Depending on the type of source database, one of the most efficient way of extracting delta records from source system is by enabling change data capture (CDC), or change tracking. It records the changes in a table at the most granular level (insert/update/delete) and allows you to store the entire history of changes and transactions in a data lake or data warehouse. While AWS Glue doesn't support extracting data using CDC, AWS Data Migration Service
(AWS DMS) is the recommended service for this purpose. Once the delta records are exported to the data lake or stage tables by AWS DMS, AWS Glue can then load them into a data warehouse efficiently (refer to the next section, AWS Glue job bookmarks). -
AWS Glue job bookmarks — If your source is an Amazon S3 data lake or a database that supports JDBC connection, AWS Glue job bookmarks are a great way to process delta files and records. They’re an AWS Glue feature that removes all the overhead of implementing any algorithm to identify delta records. AWS Glue keeps track of bookmarks for each job. If you delete a job, you also delete the job bookmark. If for some reason, you need to reprocess all or part of the data from previous job runs, you can pick a bookmark for Glue to start processing the data from that bookmark onward. If you need to re-process all data, you can disable job bookmarks.
Popular S3-based storage formats, including JSON, CSV, Apache Avro, XML, and JDBC sources, support job bookmarks. Starting with AWS Glue version 1.0, columnar storage formats such as Apache Parquet and ORC are also supported.
For S3 input sources, AWS Glue job bookmarks check the last modified time of the objects to verify which objects to reprocess. If there are new files that have arrived, or existing files changed, since your last job run, the files are reprocessed when the job is run again using a periodic AWS Glue job trigger or an S3 trigger notification
. For JDBC sources, job bookmarks require source tables to either have a primary key column(s) or a column(s) with incrementing values, which need to be specified in the source options. The AWS Glue bookmark checks for newly added records based on the columns provided and processes the delta records.
-
Limitation — For JDBC sources, job bookmarks can capture only newly added rows and it needs to be processed in batches. This behavior does not apply to source tables stored on S3.
For examples of implementing job bookmark, refer to the blog post Load data incrementally and optimized Parquet writer with AWS Glue
. -
High watermark — If the source database system doesn't have CDC feature at all, then high watermark is a classic way of extracting delta records. It is the process of storing data load status and its timestamp into metadata tables. During the ETL load, it calculates the maximum value of load timestamp (high watermark) from metadata tables and filters the data being extracted. It does require a create timestamp (new records) and update timestamp (updated records) field in each of the table in source system to allow filtering on them based on high watermark timestamp. While this process requires creation and maintenance of metadata tables, it provides great flexibility of rewinding or reprocessing data from a time in past with a simple update of the high watermark value. These high watermark filters can easily be embedded into the SQL scripts in AWS Glue ETL jobs to extracting delta records.
-
Use cases — Source system is a database that doesn't have CDC/change tracking available, and updated records must be processed.
-
Event driven — In the modern era, event driven data pipelines have become really popular especially for streaming and micro batch (< 15 min) data load patterns where the data pipeline is decoupled. The first part is to extract data from source system and load via streaming to S3 data lake within seconds. The second part is to load the data from the data lake to the data warehouse via event-driven triggers. This eliminates the need to identify delta records based on a column or timestamp, and instead relies on object/bucket level events such as put, copy, and delete to process the data, resulting in a seamless process with very less overhead. Both S3 and Amazon EventBridge support this feature, where an AWS Glue workflow or job loads the delta records to a target system as an incremental load.
Following are few use cases where the event-driven approach may be more suitable:
-
Decoupled data pipelines that have an extract process (CDC/streaming) from source systems to the S3 data lake then use events to load data to the data warehouse.
-
It’s difficult to predict the frequency at which upstream systems generate data. Once generated, it needs to load to the target system as soon as possible.
The following table provides considerations using different mechanism for incremental data loads.
Table 8 — Incremental data
| Source | CDC/change tracking | High watermark | Job bookmark for S3 source | Job bookmark for JDBC source | Event driven |
|---|---|---|---|---|---|
| Source system is a database |
Yes (CDC must be supported and enabled) |
Yes | No |
Yes (must support JDBC connection) |
No |
| Source is S3 | No | No | Yes | NA | Yes |
| Inserting new records | Yes | Yes | Yes | Yes | Yes |
| Updating records | Yes | Yes (source table should have update timestamp column) | Yes | No | Yes |
| Streaming datasets | Yes | No | No | No | Yes |
| Micro batches (< 15 min) | Yes | Yes | No | No | Yes |
| Batches (> 15 min) | Yes | Yes | Yes | Yes | Yes |
| Proprietary feature | Yes | No | Yes | Yes | Yes |
