This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Building data lakes
Because the aim is to get started on your data lake project, let’s break down your experiments into the phases that are typical in data analytics projects:
-
Data ingestion
-
Processing and transformation
-
Analytics
-
Visualization, data access, and machine learning
By breaking down the problem into these phases, you reduce the complexity of the overall challenge. This makes the number of variables in each experiment lower, enabling you to get model costs more quickly and accurately.
We recommend that you start your analytics project by implementing the foundation of a data lake. This gives you a good structure to tackle analytics challenges and allow great flexibility for the evolution of the platform.
A data lake is a single store of enterprise data that includes raw copies from various source systems and processed data that is consumed for various analytics and machine learning activities that provide business value.
Choosing the right storage to support a data lake is critical to its success. Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data.
Data lakes generally support two types of processing: batch and real-time. It is common for more advanced users to handle both types of processing within their data lake. However, they often use different tooling to deliver these capabilities. We will explore common architectures for both patterns and discuss how to estimates costs with both.
Batch processing
Batch processing is an efficient way to process large volumes of data. The data being processed is typically not time-critical and is usually processed over minutes, hours, and in some cases, days. Generally, batch processing systems automate the steps of gathering the data, extracting it, processing it, enriching it, and formatting it in a way that can be used by business applications, machine learning applications, or business intelligence reports.
Before we get started, let’s look at a common set of services that customers use to build data lakes for processing batch data.
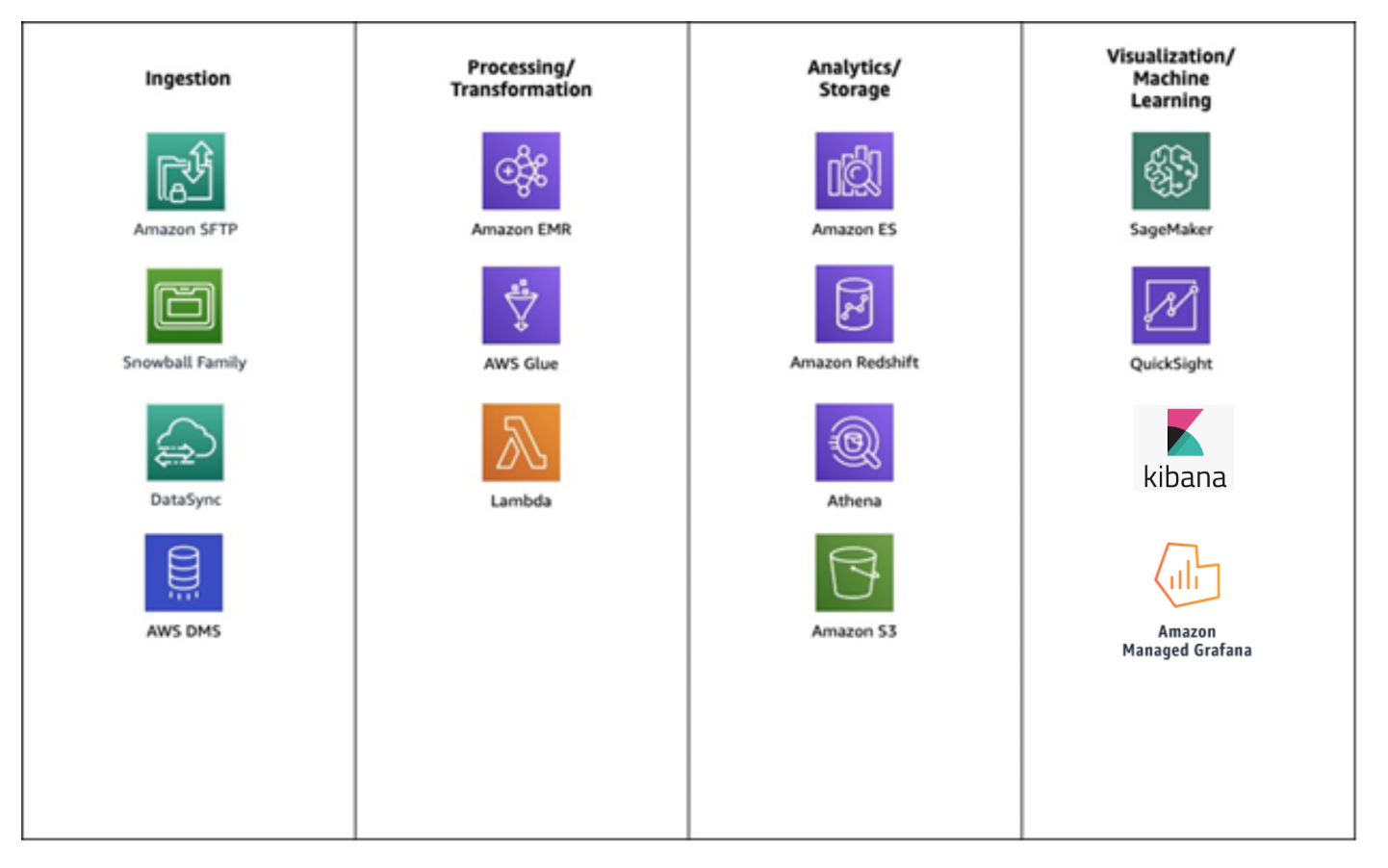
Common services used to build data lakes for batch data
The following example architecture is relatively common. It uses AWS Glue, Amazon Athena, Amazon S3, and QuickSight.

Example architecture for batch processing
The preceding example shows a typical pipeline to ingest raw data from CSV files. AWS Glue automatically infers a schema to allow the data to be queried. AWS Glue jobs are used to extract, clean, curate, and rewrite the data in an optimized format (Parquet) before exposing visualizations to end users. This is all achieved using serverless technologies that reduce the operational burden to the analytics team.
We are going to explore each of these steps in more detail, in addition to the things you need to consider along the way. But, before we do, let’s take a quick look at the other form of processing.
Real-time processing
Real-time processing is a way of processing an unbounded stream of data in order to generate real-time (or nearly real-time) alerts or business decisions. The response time for real-time processing can vary from milliseconds to minutes.
Real-time processing has its own ingestion components and has a streaming layer to stream data for further processing. Examples of real-time processing are:
-
Processing IoT sensor data to generate alerts for predictive maintenance
-
Trading data for financial analytics
-
Identifying sentiment using a real-time Twitter feed
Before we get started, let’s look at a common set of services that customers use to build data lakes for processing real-time data.

Common services used to build data lakes for real-time data
Our example architecture is relatively simple and uses the following services: Amazon Kinesis, AWS Lambda, AWS Glue, Amazon Athena, Amazon S3 and QuickSight.

Example architecture for real-time processing
This example shows that many IoT devices send their telemetry to AWS IoT Core. AWS IoT allows users to securely manage billions of connected devices and route those messages to other AWS endpoints. In this case, AWS IoT Core passes the messages Amazon Kinesis, which ingests streaming data at any scale. The raw data is split into two streams, one that writes the raw data to Amazon S3 and a second that uses AWS Lambda (a serverless compute service) to filter, aggregate, and transform the data before again storing it on Amazon S3. The manipulated data is then cataloged in AWS Glue and made available to end users to run ad hoc queries using Amazon Athena and create visualizations using QuickSight.
