Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Introduction
Votre charge de travail doit exécuter la fonction prévue correctement et de manière cohérente. Pour y parvenir, vous devez concevoir une architecture axée sur la résilience. La résilience est la capacité d'une charge de travail à récupérer après une interruption d'infrastructure, de service ou d'application, à acquérir dynamiquement des ressources informatiques pour répondre à la demande et à atténuer les perturbations, telles que les mauvaises configurations ou les problèmes de réseau transitoires.
La reprise après sinistre (DR) est un élément important de votre stratégie de résilience et concerne la manière dont votre charge de travail réagit en cas de sinistre (un sinistre est un événement qui a de graves répercussions négatives sur votre entreprise). Cette réponse doit être basée sur les objectifs commerciaux de votre organisation, qui spécifient la stratégie de votre charge de travail pour éviter la perte de données, connue sous le nom d'objectif de point de restauration (RPO), et pour réduire les temps d'arrêt lorsque votre charge de travail n'est pas disponible, connue sous le nom d'objectif de temps de restauration (RTO). Vous devez donc implémenter la résilience dans la conception de vos charges de travail dans le cloud afin d'atteindre vos objectifs de restauration (RPO et RTO) en cas de sinistre ponctuel donné. Cette approche aide votre organisation à maintenir la continuité des activités dans le cadre de la planification de la continuité des activités (BCP).
Ce paper explique comment planifier, concevoir et implémenter des architectures AWS répondant aux objectifs de reprise après sinistre de votre entreprise. Les informations partagées ici sont destinées aux personnes occupant des postes technologiques, tels que les directeurs de la technologie (CTOs), les architectes, les développeurs, les membres de l'équipe opérationnelle et les personnes chargées d'évaluer et d'atténuer les risques.
Reprise après sinistre et disponibilité
La reprise après sinistre peut être comparée à la disponibilité, qui constitue un autre élément important de votre stratégie de résilience. Alors que la reprise après sinistre mesure les objectifs pour des événements ponctuels, les objectifs de disponibilité mesurent les valeurs moyennes sur une période donnée.
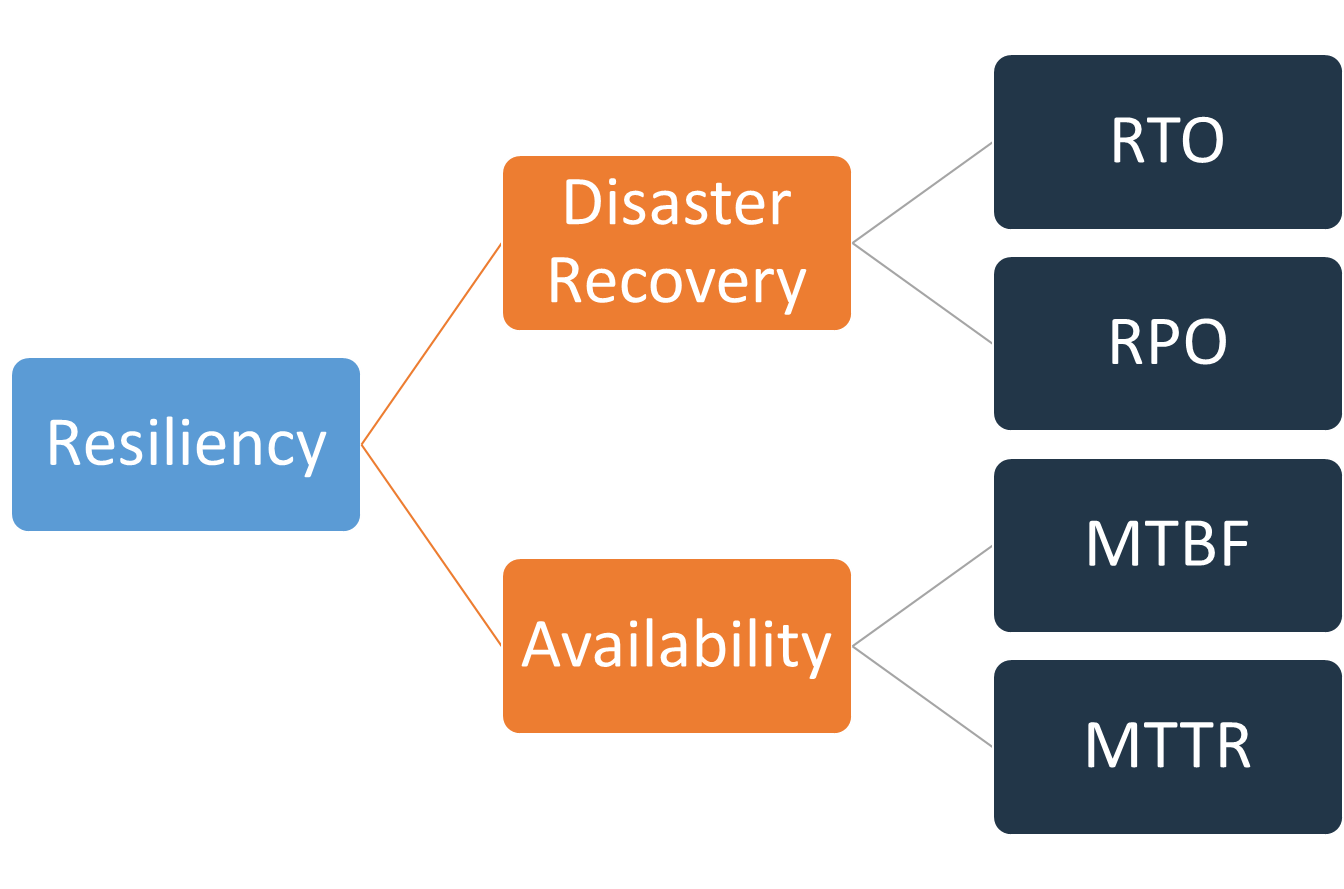
Figure 1 : Objectifs de résilience
La disponibilité est calculée à l'aide du temps moyen entre défaillances (MTBF) et du temps moyen de restauration (MTTR) :

Cette approche est souvent appelée « neuf », alors qu'un objectif de disponibilité de 99,9 % est appelé « trois neuf ».
Pour votre charge de travail, il peut être plus facile de compter les demandes réussies et les demandes échouées plutôt que d'utiliser une approche basée sur le temps. Dans ce cas, le calcul suivant peut être utilisé :
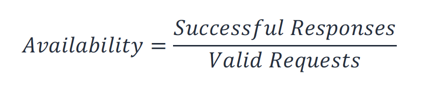
La reprise après sinistre se concentre sur les catastrophes, tandis que la disponibilité se concentre sur les perturbations les plus courantes de moindre envergure, telles que les défaillances de composants, les problèmes de réseau, les bogues logiciels et les pics de charge. L'objectif de la reprise après sinistre est la continuité des activités, tandis que la disponibilité consiste à optimiser le temps pendant lequel une charge de travail est disponible pour exécuter les fonctionnalités commerciales prévues. Les deux devraient faire partie de votre stratégie de résilience.
Êtes-vous Well-Architected ?
L'AWS Well-Architected Framework
Les concepts abordés dans ce livre blanc développent les meilleures pratiques contenues dans le livre blanc sur le pilier de fiabilité, en particulier la question REL 13, « Comment planifiez-vous la reprise après sinistre (DR) ? ». Après avoir mis en œuvre les pratiques décrites dans ce livre blanc, assurez-vous de revoir (ou de revoir) votre charge de travail à l'aide de l'outil AWS Well-Architected Tool.
