Étape 4 : Évaluer les prédicteurs
Un flux de travail classique dans le domaine du machine learning consiste à entraîner un ensemble de modèles ou une combinaison de modèles sur un ensemble d'apprentissage et à évaluer leur précision sur un jeu de données d'attente. Cette section traite de la manière de fractionner les données historiques et des métriques à utiliser pour évaluer les modèles de prévision des séries temporelles. Pour les prévisions, la technique du backtesting est le principal outil pour évaluer la précision des prévisions.
Backtesting
Un cadre d'évaluation et de backtesting approprié est l'un des facteurs les plus importants pour faire d'une application de machine learning un succès. Vous pouvez vous appuyer sur des backtests réussis avec vos modèles pour gagner en confiance sur le pouvoir prédictif futur des modèles. En outre, vous pouvez ajuster les modèles via l'optimisation des hyperparamètres (HPO), apprendre des combinaisons de modèles et activer le méta-apprentissage et AutoML.
La série temporelle prédisant le temps caractéristique la différencie, en termes de méthodologie d'évaluation et de backtesting, des autres domaines du machine learning appliqué. Habituellement, dans les tâches de ML, pour évaluer l'erreur prédictive dans un backtest, vous divisez un jeu de données par éléments. Par exemple, pour la validation croisée dans les tâches liées aux images, vous vous entraînez sur un certain pourcentage des images, puis vous utilisez d'autres parties pour le test et la validation. Dans le domaine de la prévision, il est nécessaire de procéder à un fractionnement essentiellement temporel (et, dans une moindre mesure, par éléments) afin de s'assurer que les informations de l'ensemble d'entraînement ne se retrouvent pas dans l'ensemble de test ou de validation, et que vous simulez le cas de production aussi fidèlement que possible.
Le fractionnement dans le temps doit être effectué avec soin car vous ne voulez pas choisir un seul point dans le temps, mais plusieurs points. Sinon, la précision est trop dépendante de la date de début de la prévision, telle que définie par le point de séparation. Une évaluation des prévisions en continu, dans laquelle vous effectuez une série de fractionnements sur plusieurs points dans le temps et produisez le résultat moyen, donne des résultats de backtest plus solides et plus fiables. La figure suivante illustre quatre fractionnements de backtest différents.

Illustration de quatre scénarios de backtesting différents avec une taille croissante de l'ensemble d'entraînement, mais une taille constante de l'ensemble de test
Dans la figure précédente, tous les scénarios de backtesting disposent de données disponibles dans leur intégralité pour pouvoir évaluer les valeurs prévues par rapport aux valeurs réelles.
La raison pour laquelle plusieurs fenêtres de backtest sont nécessaires est que la plupart des séries temporelles dans le monde réel sont normalement non stationnaires. L'entreprise de e-commerce de l'étude de cas est basée en Amérique du Nord et une grande partie de sa demande de produits est déterminée par le pic du quatrième trimestre, avec des pics particuliers autour de Thanksgiving et avant Noël. Pendant la saison des achats du quatrième trimestre, la variabilité de la série temporelle est plus élevée que pendant le reste de l'année. En disposant de plusieurs fenêtres de backtest, vous pouvez évaluer les modèles de prévision dans un cadre plus équilibré.
Pour chaque scénario de backtest, la figure suivante montre les éléments de base dans la terminologie d'Amazon Forecast. Amazon Forecast fractionne automatiquement les données en jeux de données d'entraînement et de test. Amazon Forecast décide comment fractionner les données d'entrée en utilisant le paramètre BackTestWindowOffset spécifié en tant que paramètre dans l'API create_predictor ou en utilisant sa valeur par défaut de ForecastHorizon.
Dans la figure suivante, vous voyez le premier cas, plus général, où les paramètres BackTestWindowOffset et ForecastHorizon ne sont pas égaux. Le paramètre BackTestWindowOffset définit une date de début de prévision virtuelle, représentée par la ligne verticale en pointillés dans la figure suivante. Il peut être utilisé pour répondre à la question hypothétique suivante : si le modèle était déployé ce jour-là, quelle serait la prévision ? Le paramètre ForecastHorizon définit le nombre d'intervalles de temps à partir de la date de début de la prévision virtuelle pour effectuer la prédiction.

Illustration d'un scénario de backtest unique et de sa configuration dans Amazon Forecast
Amazon Forecast peut exporter les valeurs prévisionnelles et les mesures de précision générées pendant le backtesting. Les données exportées peuvent être utilisées pour évaluer des éléments spécifiques à des points de temps et des quantiles spécifiques.
Quantiles de prédiction et métriques de précision
Les quantiles de prévision peuvent fournir une limite supérieure et inférieure pour les prévisions. Par exemple, l'utilisation des types de prévision 0,1 (P10), 0,5 (P50) et 0,9 (P90) fournit une plage de valeurs connue sous le nom d'intervalle de confiance de 80 % autour de la prévision P50. En générant des prévisions à P10, P50 et P90, vous pouvez vous attendre à ce que la valeur réelle se situe entre ces limites 80 % du temps.
Ce document traite plus en détail des quantiles à l'étape 5.
Amazon Forecast utilise les mesures de précision de la perte de quantile pondérée (wQL), de la racine carrée de l'erreur quadratique moyenne (RMSE) et du pourcentage d'erreur absolu pondéré (WAPE) pour évaluer les prédicteurs pendant le backtesting.
Perte de quantile pondérée (wQL)
La métrique d'erreur de perte de quantile pondérée (wQL) mesure la précision de la prévision d'un modèle à un quantile spécifié. Elle est particulièrement utile lorsqu'il existe des coûts différents pour la sous-estimation et la surestimation. La définition de la pondération (τ) de la fonction wQL intègre automatiquement différentes pénalités en cas de sous-estimation et de surestimation.
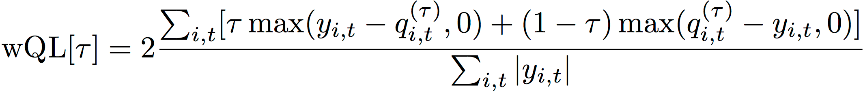
Fonction wQL
Où :
-
τ — Un quantile dans l'ensemble {0,01, 0,02,..., 0,99}
-
qi,t(τ) — Le quantile τ prédit par le modèle.
-
yi,t — La valeur observée au point (i,t)
Pourcentage d'erreur absolu pondéré (WAPE)
Le pourcentage d'erreur absolu pondéré (WAPE) est une métrique couramment utilisée pour mesurer la précision des modèles. Il mesure l'écart global des valeurs prévues par rapport aux valeurs observées.
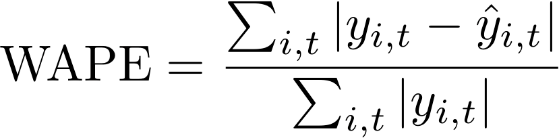
WAPE
Où :
-
yi,t : la valeur observée au point (i,t)
-
ŷi,t : la valeur prédite au point (i,t)
Forecast utilise la prévision moyenne comme valeur prédite, ŷi,t.
Racine carrée de l'erreur quadratique moyenne (RMSE)
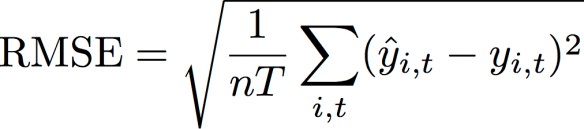
La racine carrée de l'erreur quadratique moyenne (RMSE) est une métrique couramment utilisée pour mesurer la précision des modèles. Comme l'équation WAPE, elle mesure l'écart global des estimations par rapport aux valeurs observées.
Où :
-
yi,t : la valeur observée au point (i,t)
-
ŷi,t : la valeur prédite au point (i,t)
-
nT : le nombre de points de données dans un ensemble de test
Forecast utilise la prévision moyenne comme valeur prédite, ŷi,t. Lors du calcul des métriques de prédiction, nT désigne le nombre de points de données dans une fenêtre de backtest.
Problèmes avec WAPE et RMSE
Dans la plupart des cas, les prévisions ponctuelles qui peuvent être générées en interne ou par d'autres outils de prévision devraient correspondre aux prévisions du quantile ou de la moyenne p50. Pour WAPE et RMSE, Amazon Forecast utilise la prévision moyenne pour représenter la valeur prédite (yhat).
Pour tau = 0,5 dans l'équation wQL[tau], les deux pondérations sont égales, et le wQL[0.5] se réduit au pourcentage d'erreur absolu pondéré (WAPE) couramment utilisé pour les prévisions ponctuelles :
![Image de l'équation wQL [0.5].](images/wql.png)
où yhat = q(0.5) est la prévision calculée. Un facteur d'échelle de 2 est utilisé dans la formule wQL pour annuler le facteur 0,5 afin d'obtenir l'expression exacte de WAPE [médiane].
Notez que la définition ci-dessus de l'équation WAPE diffère de l'interprétation courante du pourcentage d'erreur absolu pondéré (MAPE
Contrairement à la métrique de perte par quantile pondéré pour tau non égal à 0,5, le biais inhérent à chaque quantile ne peut pas être pris en compte par un calcul comme l'équation WAPE, où les pondérations sont égales. Parmi les autres inconvénients de l'équation WAPE, on peut citer le fait qu'elle n'est pas symétrique, qu'elle présente une surinflation des erreurs en pourcentage pour les petits nombres et qu'elle n'est qu'une métrique ponctuelle.
La RMSE est le carré du terme d'erreur dans l'équation WAPE et une mesure d'erreur commune dans d'autres applications ML. La métrique RMSE favorise un modèle où les erreurs individuelles sont d'une magnitude constante, car de grandes variations dans l'erreur augmenteront la RMSE de façon disproportionnée. En raison de l'erreur quadratique, quelques valeurs mal prédites dans une prévision autrement bonne peuvent augmenter le RMSE. De plus, en raison des termes au carré, les termes d'erreur plus petits ont moins de poids dans la RMSE que dans la WAPE.
Les métriques de précision permettent une évaluation quantitative des prévisions. Elles sont cruciales, notamment pour les comparaisons à grande échelle (la méthode A est-elle globalement meilleure que la méthode B). Cependant, il est souvent important de compléter ces éléments par des visuels pour les différentes références.
