Tutorial: Creating a machine learning transform with AWS Glue
This tutorial guides you through the actions to create and manage a machine learning (ML) transform using AWS Glue. Before using this tutorial, you should be familiar with using the AWS Glue console to add crawlers and jobs and edit scripts. You should also be familiar with finding and downloading files on the Amazon Simple Storage Service (Amazon S3) console.
In this example, you create a FindMatches transform to find matching
records, teach it how to identify matching and nonmatching records, and use it in an AWS Glue job.
The AWS Glue job writes a new Amazon S3 file with an additional column named match_id.
The source data used by this tutorial is a file named
dblp_acm_records.csv. This file is a modified version of academic
publications (DBLP and ACM) available from the original DBLP ACM datasetdblp_acm_records.csv file is a comma-separated values (CSV) file in UTF-8
format with no byte-order mark (BOM).
A second file, dblp_acm_labels.csv, is an example labeling file that
contains both matching and nonmatching records used to teach the transform as part of the
tutorial.
Topics
Step 1: Crawl the source data
First, crawl the source Amazon S3 CSV file to create a corresponding metadata table in the Data Catalog.
Important
To direct the crawler to create a table for only the CSV file, store the CSV source data in a different Amazon S3 folder from other files.
Sign in to the AWS Management Console and open the AWS Glue console at https://console.aws.amazon.com/glue/
. -
In the navigation pane, choose Crawlers, Add crawler.
-
Follow the wizard to create and run a crawler named
demo-crawl-dblp-acmwith output to databasedemo-db-dblp-acm. When running the wizard, create the databasedemo-db-dblp-acmif it doesn't already exist. Choose an Amazon S3 include path to sample data in the current AWS Region. For example, forus-east-1, the Amazon S3 include path to the source file iss3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv.If successful, the crawler creates the table
dblp_acm_records_csvwith the following columns: id, title, authors, venue, year, and source.
Step 2: Add a machine learning transform
Next, add a machine learning transform that is based on the schema of your data source
table created by the crawler named demo-crawl-dblp-acm.
-
On the AWS Glue console, in the navigation pane under Data Integration and ETL, choose Data classification tools > Record Matching, then Add transform. Follow the wizard to create a
Find matchestransform with the following properties.-
For Transform name, enter
demo-xform-dblp-acm. This is the name of the transform that is used to find matches in the source data. -
For IAM role, choose an IAM role that has permission to the Amazon S3 source data, labeling file, and AWS Glue API operations. For more information, see Create an IAM Role for AWS Glue in the AWS Glue Developer Guide.
-
For Data source, choose the table named dblp_acm_records_csv in database demo-db-dblp-acm.
-
For Primary key, choose the primary key column for the table, id.
-
In the wizard, choose Finish and return to the ML transforms list.
Step 3: Teach your machine learning transform
Next, you teach your machine learning transform using the tutorial sample labeling file.
You can't use a machine language transform in an extract, transform, and load (ETL) job
until its status is Ready for use. To get your transform ready, you must
teach it how to identify matching and nonmatching records by providing examples of matching
and nonmatching records. To teach your transform, you can Generate a label
file, add labels, and then Upload label file. In this
tutorial, you can use the example labeling file named
dblp_acm_labels.csv. For more information about the labeling process, see
Labeling.
-
On the AWS Glue console, in the navigation pane, choose Record Matching.
-
Choose the
demo-xform-dblp-acmtransform, and then choose Action, Teach. Follow the wizard to teach yourFind matchestransform. On the transform properties page, choose I have labels. Choose an Amazon S3 path to the sample labeling file in the current AWS Region. For example, for
us-east-1, upload the provided labeling file from the Amazon S3 paths3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvwith the option to overwrite existing labels. The labeling file must be located in Amazon S3 in the same Region as the AWS Glue console.When you upload a labeling file, a task is started in AWS Glue to add or overwrite the labels used to teach the transform how to process the data source.
On the final page of the wizard, choose Finish, and return to the ML transforms list.
Step 4: Estimate the quality of your machine learning transform
Next, you can estimate the quality of your machine learning transform. The quality depends on how much labeling you have done. For more information about estimating quality, see Estimate quality.
-
On the AWS Glue console, in the navigation pane under Data Integration and ETL, choose Data classification tools > Record Matching.
-
Choose the
demo-xform-dblp-acmtransform, and choose the Estimate quality tab. This tab displays the current quality estimates, if available, for the transform. Choose Estimate quality to start a task to estimate the quality of the transform. The accuracy of the quality estimate is based on the labeling of the source data.
Navigate to the History tab. In this pane, task runs are listed for the transform, including the Estimating quality task. For more details about the run, choose Logs. Check that the run status is Succeeded when it finishes.
Step 5: Add and run a job with your machine learning transform
In this step, you use your machine learning transform to add and run a job in AWS Glue.
When the transform demo-xform-dblp-acm is Ready for
use, you can use it in an ETL job.
-
On the AWS Glue console, in the navigation pane, choose Jobs.
-
Choose Add job, and follow the steps in the wizard to create an ETL Spark job with a generated script. Choose the following property values for your transform:
-
For Name, choose the example job in this tutorial, demo-etl-dblp-acm.
-
For IAM role, choose an IAM role with permission to the Amazon S3 source data, labeling file, and AWS Glue API operations. For more information, see Create an IAM Role for AWS Glue in the AWS Glue Developer Guide.
-
For ETL language, choose Scala. This is the programming language in the ETL script.
-
For Script file name, choose demo-etl-dblp-acm. This is the file name of the Scala script (same as the job name).
-
For Data source, choose dblp_acm_records_csv. The data source you choose must match the machine learning transform data source schema.
-
For Transform type, choose Find matching records to create a job using a machine learning transform.
-
Clear Remove duplicate records. You don't want to remove duplicate records because the output records written have an additional
match_idfield added. -
For Transform, choose demo-xform-dblp-acm, the machine learning transform used by the job.
-
For Create tables in your data target, choose to create tables with the following properties:
-
Data store type —
Amazon S3 -
Format —
CSV -
Compression type —
None -
Target path — The Amazon S3 path where the output of the job is written (in the current console AWS Region)
-
-
-
Choose Save job and edit script to display the script editor page.
-
Edit the script to add a statement to cause the job output to the Target path to be written to a single partition file. Add this statement immediately following the statement that runs the
FindMatchestransform. The statement is similar to the following.val single_partition = findmatches1.repartition(1)You must modify the
.writeDynamicFrame(findmatches1)statement to write the output as.writeDynamicFrame(single_partion). -
After you edit the script, choose Save. The modified script looks similar to the following code, but customized for your environment.
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } Choose Run job to start the job run. Check the status of the job in the jobs list. When the job finishes, in the ML transform, History tab, there is a new Run ID row added of type ETL job.
Navigate to the Jobs, History tab. In this pane, job runs are listed. For more details about the run, choose Logs. Check that the run status is Succeeded when it finishes.
Step 6: Verify output data from Amazon S3
In this step, you check the output of the job run in the Amazon S3 bucket that you chose when you added the job. You can download the output file to your local machine and verify that matching records were identified.
Open the Amazon S3 console at https://console.aws.amazon.com/s3/
. Download the target output file of the job
demo-etl-dblp-acm. Open the file in a spreadsheet application (you might need to add a file extension.csvfor the file to properly open).The following image shows an excerpt of the output in Microsoft Excel.
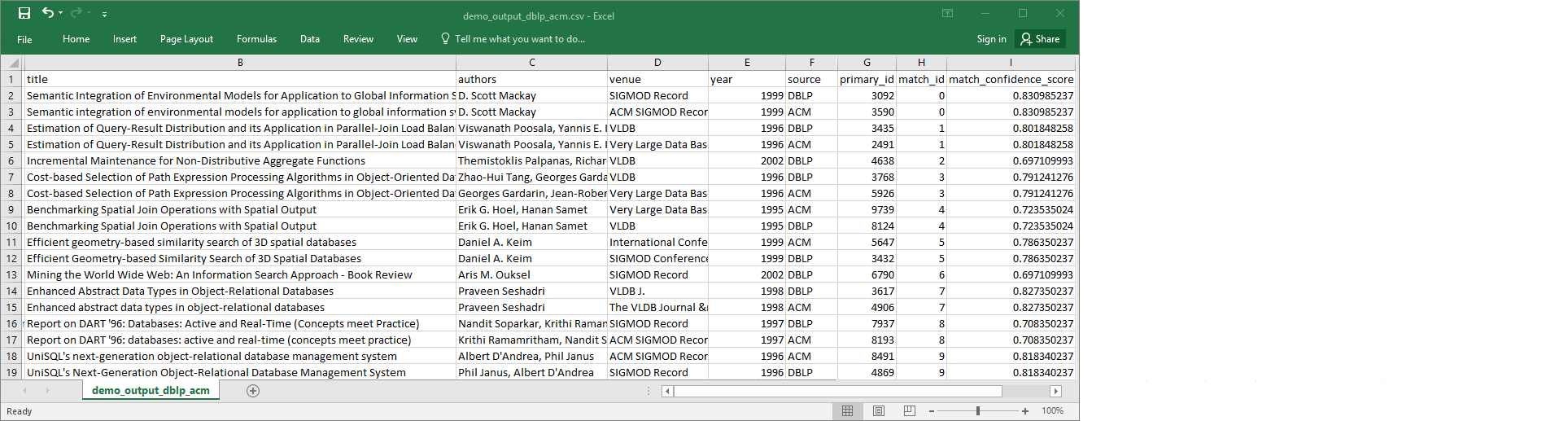
The data source and target file both have 4,911 records. However, the
Find matchestransform adds another column namedmatch_idto identify matching records in the output. Rows with the samematch_idare considered matching records. Thematch_confidence_scoreis a number between 0 and 1 that provides an estimate of the quality of matches found byFind matches.-
Sort the output file by
match_idto easily see which records are matches. Compare the values in the other columns to see if you agree with the results of theFind matchestransform. If you don't, you can continue to teach the transform by adding more labels.You can also sort the file by another field, such as
title, to see if records with similar titles have the samematch_id.
