Solution for monitoring Kafka applications with Amazon Managed Grafana
Applications built on top of Apache Kafka
Note
This solution does not support monitoring Amazon Managed Streaming for Apache Kafka applications. For information about monitoring Amazon MSK applications, see Monitor an Amazon MSK cluster in the Amazon Managed Streaming for Apache Kafka Developer Guide.
This solution configures:
-
Your Amazon Managed Service for Prometheus workspace to store Kafka and Java Virtual Machine (JVM) metrics from your Amazon EKS cluster.
-
Gathering specific Kafka and JVM metrics using the CloudWatch agent, as well as a CloudWatch agent add-on. The metrics are configured to be sent to the Amazon Managed Service for Prometheus workspace.
-
Your Amazon Managed Grafana workspace to pull those metrics, and create dashboards to help you monitor your cluster.
Note
This solution provides JVM and Kafka metrics for your application running on Amazon EKS, but does not include Amazon EKS metrics. You can use the Observability solution for monitoring Amazon EKS to see metrics and alerts for your Amazon EKS cluster.
About this solution
This solution configures an Amazon Managed Grafana workspace to provide metrics for your Apache Kafka application. The metrics are used to generate dashboards that help you to operate your application more effectively by providing insights into the performance and workload of the Kafka application.
The following image shows a sample of one of the dashboards created by this solution.
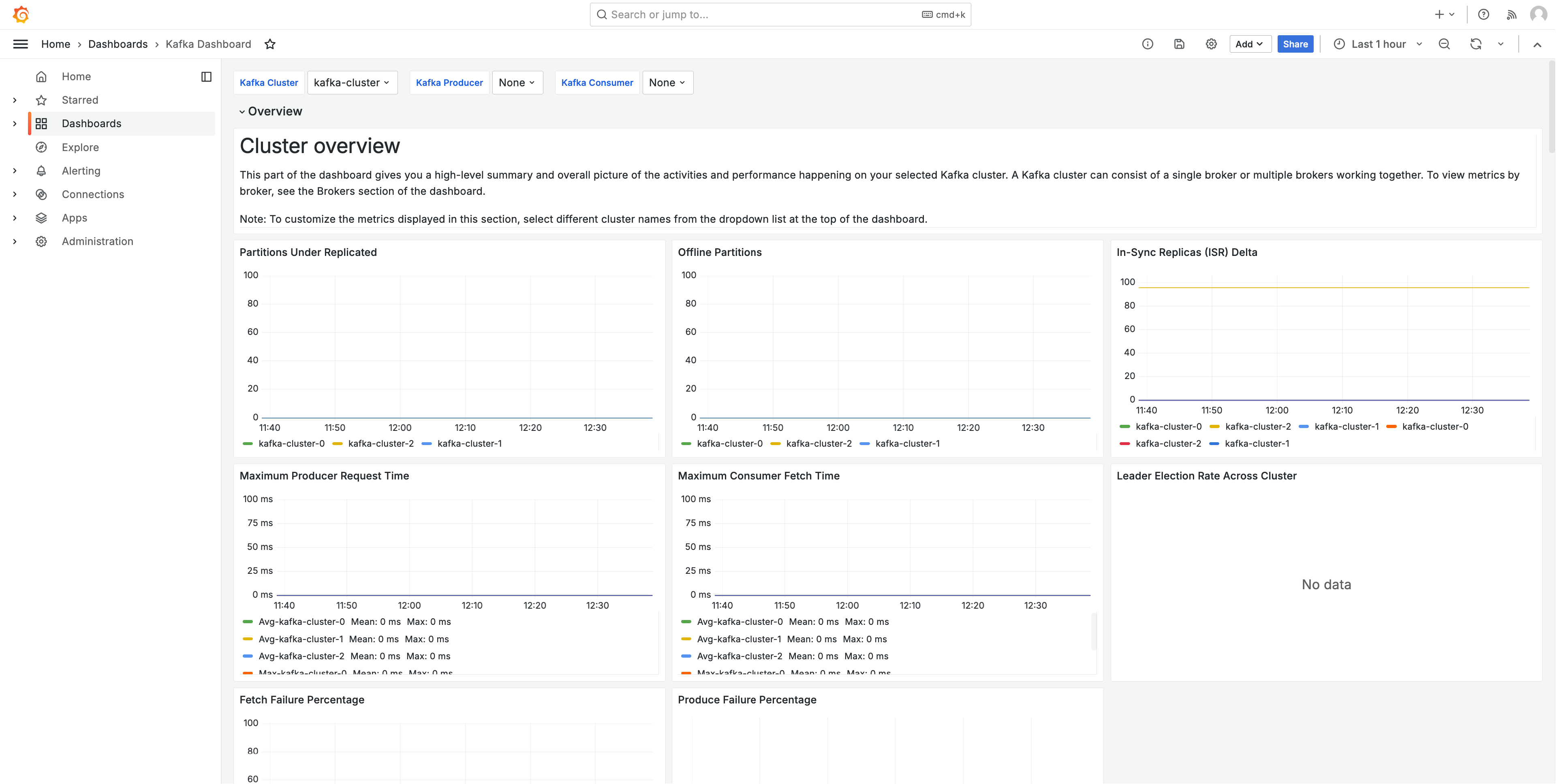
The metrics are scraped with a 1 minute scrape interval. The dashboards show metrics aggregated to 1 minute, 5 minutes, or more, based on the specific metric.
For a list of metrics tracked by this solution, see List of metrics tracked.
Costs
This solution creates and uses resources in your workspace. You will be charged for standard usage of the resources created, including:
-
Amazon Managed Grafana workspace access by users. For more information about pricing, see Amazon Managed Grafana pricing
. -
Amazon Managed Service for Prometheus metric ingestion and storage, and metric analysis (query sample processing). The number of metrics used by this solution depends on your application configuration and usage.
You can view the ingestion and storage metrics in Amazon Managed Service for Prometheus using CloudWatch For more information, see CloudWatch metrics in the Amazon Managed Service for Prometheus User Guide.
You can estimate the cost using the pricing calculator on the Amazon Managed Service for Prometheus pricing
page. The number of metrics will depend on the number of nodes in your cluster, and the metrics your applications produce. -
Networking costs. You may incur standard AWS network charges for cross availability zone, Region, or other traffic.
The pricing calculators, available from the pricing page for each product, can help you understand potential costs for your solution. The following information can help get a base cost, for the solution running in the same availability zone as the Amazon EKS cluster.
| Product | Calculator metric | Value |
|---|---|---|
Amazon Managed Service for Prometheus |
Active series |
95 (per Kafka pod) |
Avg Collection Interval |
60 (seconds) |
|
Amazon Managed Grafana |
Number of active editors/administrators |
1 (or more, based on your users) |
These numbers are the base numbers for a solution running Kafka on Amazon EKS. This will give you an estimate of the base costs. As you add Kafka pods to your application, the costs will grow, as shown. These costs leave out network usage costs, which will vary based on whether the Amazon Managed Grafana workspace, Amazon Managed Service for Prometheus workspace, and Amazon EKS cluster are in the same availability zone, AWS Region, and VPN.
Prerequisites
This solution requires that you have done the following before using the solution.
-
You must have or create an Amazon Elastic Kubernetes Service cluster that you wish to monitor, and the cluster must have at least one node. The cluster must have API server endpoint access set to include private access (it can also allow public access).
The authentication mode must include API access (it can be set to either
APIorAPI_AND_CONFIG_MAP). This allows the solution deployment to use access entries.The following should be installed in the cluster (true by default when creating the cluster via the console, but must be added if you create the cluster using the AWS API or AWS CLI): Amazon EKS Pod Identity Agent, AWS CNI, CoreDNS, Kube-proxy and Amazon EBS CSI Driver AddOns (the Amazon EBS CSI Driver AddOn is not technically required for the solution, but is required for most Kafka applications).
Save the Cluster name to specify later. This can be found in the cluster details in the Amazon EKS console.
Note
For details about how to create an Amazon EKS cluster, see Getting started with Amazon EKS.
-
You must be running an Apache Kafka application on Java Virtual Machines on your Amazon EKS cluster.
-
You must create an Amazon Managed Service for Prometheus workspace in the same AWS account as your Amazon EKS cluster. For details, see Create a workspace in the Amazon Managed Service for Prometheus User Guide.
Save the Amazon Managed Service for Prometheus workspace ARN to specify later.
-
You must create an Amazon Managed Grafana workspace with Grafana version 9 or newer, in the same AWS Region as your Amazon EKS cluster. For details about creating a new workspace, see Create an Amazon Managed Grafana workspace.
The workspace role must have permissions to access Amazon Managed Service for Prometheus and Amazon CloudWatch APIs. The easiest way to do this is to use Service-managed permissions and select Amazon Managed Service for Prometheus and CloudWatch. You can also manually add the AmazonPrometheusQueryAccess and AmazonGrafanaCloudWatchAccess policies to your workspace IAM role.
Save the Amazon Managed Grafana workspace ID and endpoint to specify later. The ID is in the form
g-123example. The ID and the endpoint can be found in the Amazon Managed Grafana console. The endpoint is the URL for the workspace, and includes the ID. For example,https://g-123example.grafana-workspace.<region>.amazonaws.com/.
Note
While not strictly required to set up the solution, you must set up user authentication in your Amazon Managed Grafana workspace before users can access the dashboards created. For more information, see Authenticate users in Amazon Managed Grafana workspaces.
Using this solution
This solution configures AWS infrastructure to support reporting and monitoring metrics from a Kafka application running in an Amazon EKS cluster. You can install it using AWS Cloud Development Kit (AWS CDK).
Note
To use this solution to monitor an Amazon EKS cluster with AWS CDK
-
Make sure that you have completed all of the prerequisites steps.
-
Download all files for the solution from Amazon S3. The files are located at
s3://aws-observability-solutions/Kafka_EKS/OSS/CDK/v1.0.0/iac, and you can download them with the following Amazon S3 command. Run this command from a folder in your command line environment.aws s3 sync s3://aws-observability-solutions/Kafka_EKS/OSS/CDK/v1.0.0/iac/ .You do not need to modify these files.
-
In your command line environment (from the folder where you downloaded the solution files), run the following commands.
Set up the needed environment variables. Replace
REGION,AMG_ENDPOINT,EKS_CLUSTER, andAMP_ARNwith your AWS Region, Amazon Managed Grafana workspace endpoint (n the formhttp://g-123example.grafana-workspace.us-east-1.amazonaws.com), Amazon EKS cluster name, and Amazon Managed Service for Prometheus workspace ARN.export AWS_REGION=REGIONexport AMG_ENDPOINT=AMG_ENDPOINTexport EKS_CLUSTER_NAME=EKS_CLUSTERexport AMP_WS_ARN=AMP_ARN -
You must create annotations that can be used by the deployment. You can choose to annotate a namespace, deployment, statefulset, daemonset, or your pods directly. The Kafka solution requires five annotations. You will use
kubectlto annotation your resources with the following commands:kubectl annotate<resource-type><resource-value>instrumentation.opentelemetry.io/inject-java=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-jvm=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka-producer=true kubectl annotate<resource-type><resource-value>cloudwatch.aws.amazon.com/inject-jmx-kafka-consumer=trueReplace
<resource-type>and<resource-value>with the correct values for your system. For example, to annotate yourfoodeployment, your first command would be:kubectl annotate deployment foo instrumentation.opentelemetry.io/inject-java=true -
Create a service account token with ADMIN access for calling Grafana HTTP APIs. For details, see Use service accounts to authenticate with the Grafana HTTP APIs. You can use the AWS CLI with the following commands to create the token. You will need to replace the
GRAFANA_IDwith the ID of your Grafana workspace (it will be in the formg-123example). This key will expire after 7,200 seconds, or 2 hours. You can change the time (seconds-to-live), if you need to. The deployment takes under one hour.# creates a new service account (optional: you can use an existing account) GRAFANA_SA_ID=$(aws grafana create-workspace-service-account \ --workspace-idGRAFANA_ID\ --grafana-role ADMIN \ --name grafana-operator-key \ --query 'id' \ --output text) # creates a new token for calling APIs export AMG_API_KEY=$(aws grafana create-workspace-service-account-token \ --workspace-id $managed_grafana_workspace_id \ --name "grafana-operator-key-$(date +%s)" \ --seconds-to-live 7200 \ --service-account-id $GRAFANA_SA_ID \ --query 'serviceAccountToken.key' \ --output text)Make the API Key available to the AWS CDK by adding it to AWS Systems Manager with the following command. Replace
AWS_REGIONwith the Region that your solution will run in (in the formus-east-1).aws ssm put-parameter --name "/observability-aws-solution-kafka-eks/grafana-api-key" \ --type "SecureString" \ --value $AMG_API_KEY \ --regionAWS_REGION\ --overwrite -
Run the following
makecommand, which will install any other dependencies for the project.make deps -
Finally, run the AWS CDK project:
make build && make pattern aws-observability-solution-kafka-eks-$EKS_CLUSTER_NAME deploy -
[Optional] After the stack creation is complete, you may use the same environment to create more instances of the stack for other Kafka applications running on Amazon EKS clusters in the same region, as long as you complete the other prerequisites for each (including separate Amazon Managed Grafana and Amazon Managed Service for Prometheus workspaces). You will need to redefine the
exportcommands with the new parameters.
When the stack creation is completed, your Amazon Managed Grafana workspace will be populated with a dashboard showing metrics for your application and Amazon EKS cluster. It will take a few minutes for metrics to be shown, as the metrics are collected.
List of metrics tracked
This solution collects metrics from your JVM-based Kafka application. Those metrics are stored in Amazon Managed Service for Prometheus, and then displayed in Amazon Managed Grafana dashboards.
The following metrics are tracked with this solution.
jvm.classes.loaded
jvm.gc.collections.count
jvm.gc.collections.elapsed
jvm.memory.heap.init
jvm.memory.heap.max
jvm.memory.heap.used
jvm.memory.heap.committed
jvm.memory.nonheap.init
jvm.memory.nonheap.max
jvm.memory.nonheap.used
jvm.memory.nonheap.committed
jvm.memory.pool.init
jvm.memory.pool.max
jvm.memory.pool.used
jvm.memory.pool.committed
jvm.threads.count
kafka.message.count
kafka.request.count
kafka.request.failed
kafka.request.time.total
kafka.request.time.50p
kafka.request.time.99p
kafka.request.time.avg
kafka.network.io
kafka.purgatory.size
kafka.partition.count
kafka.partition.offline
kafka.partition.under_replicated
kafka.isr.operation.count
kafka.max.lag
kafka.controller.active.count
kafka.leader.election.rate
kafka.unclean.election.rate
kafka.request.queue
kafka.logs.flush.time.count
kafka.logs.flush.time.median
kafka.logs.flush.time.99p
kafka.consumer.fetch-rate
kafka.consumer.records-lag-max
kafka.consumer.total.bytes-consumed-rate
kafka.consumer.total.fetch-size-avg
kafka.consumer.total.records-consumed-rate
kafka.consumer.bytes-consumed-rate
kafka.consumer.fetch-size-avg
kafka.consumer.records-consumed-rate
kafka.producer.io-wait-time-ns-avg
kafka.producer.outgoing-byte-rate
kafka.producer.request-latency-avg
kafka.producer.request-rate
kafka.producer.response-rate
kafka.producer.byte-rate
kafka.producer.compression-rate
kafka.producer.record-error-rate
kafka.producer.record-retry-rate
kafka.producer.record-send-rate
Troubleshooting
There are a few things that can cause the setup of the project to fail. Be sure to check the following.
-
You must complete all Prerequisites before installing the solution.
-
The cluster must have at least one node in it before attempting to create the solution or access the metrics.
-
Your Amazon EKS cluster must have the
AWS CNI,CoreDNSandkube-proxyadd-ons installed. If they are not installed, the solution will not work correctly. They are installed by default, when creating the cluster through the console. You may need to install them if the cluster was created through an AWS SDK. -
Amazon EKS pods installation timed out. This can happen if there is not enough node capacity available. There are multiple causes of these issues, including:
-
The Amazon EKS cluster was initialized with Fargate instead of Amazon EC2. This project requires Amazon EC2.
-
The nodes are tainted and therefore unavailable.
You can use
kubectl describe nodeto check the taints. ThenNODENAME| grep Taintskubectl taint nodeto remove the taints. Make sure to include theNODENAMETAINT_NAME--after the taint name. -
The nodes have reached the capacity limit. In this case you can create a new node or increase the capacity.
-
-
You do not see any dashboards in Grafana: using the incorrect Grafana workspace ID.
Run the following command to get information about Grafana:
kubectl describe grafanas external-grafana -n grafana-operatorYou can check the results for the correct workspace URL. If it is not the one you are expecting, re-deploy with the correct workspace ID.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
You do not see any dashboards in Grafana: You are using an expired API key.
To look for this case, you will need to get the grafana operator and check the logs for errors. Get the name of the Grafana operator with this command:
kubectl get pods -n grafana-operatorThis will return the operator name, for example:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2mUse the operator name in the following command:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operatorError messages such as the following indicate an expired API key:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).ReconcileIn this case, create a new API key and deploy the solution again. If the problem persists, you can force synchronization by using the following command before redeploying:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
Missing SSM parameter. If you see an error like the following, run
cdk bootstrapand try again.Deployment failed: Error: aws-observability-solution-kafka-eks-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html)
