Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Cluster Auto Scaling ElastiCache (Redis OSS)
Prasyarat
ElastiCache (Redis OSS) Auto Scaling terbatas pada hal-hal berikut:
-
Redis OSS (mode cluster diaktifkan) cluster yang menjalankan Redis OSS engine versi 6.0 dan seterusnya
-
Tingkat data (mode cluster diaktifkan) cluster yang menjalankan mesin Redis OSS versi 7.0.7 dan seterusnya
-
Ukuran instans - Large, XLarge, 2XLarge
-
Kelompok tipe instans - R7g, R6g, R6gd, R5, M7g, M6g, M5, C7gn
-
Auto Scaling in ElastiCache (Redis OSS) tidak didukung untuk cluster yang berjalan di Datastores Global, Outposts atau Local Zones.
Mengelola Kapasitas Secara Otomatis dengan ElastiCache Auto Scaling (Redis OSS)
ElastiCache (Redis OSS) auto scaling adalah kemampuan untuk menambah atau mengurangi pecahan atau replika yang diinginkan dalam layanan ElastiCache (Redis OSS) Anda secara otomatis. ElastiCache (Redis OSS) memanfaatkan layanan Application Auto Scaling untuk menyediakan fungsionalitas ini. Untuk informasi selengkapnya, lihat Application Auto Scaling. Untuk menggunakan penskalaan otomatis, Anda menentukan dan menerapkan kebijakan penskalaan yang menggunakan CloudWatch metrik dan nilai target yang Anda tetapkan. ElastiCache (Redis OSS) auto scaling menggunakan kebijakan untuk menambah atau mengurangi jumlah instance sebagai respons terhadap beban kerja aktual.
Anda dapat menggunakan AWS Management Console untuk menerapkan kebijakan penskalaan berdasarkan metrik yang telah ditentukan sebelumnya. Sebuah predefined metric didefinisikan dalam penghitungan sehingga Anda dapat menentukannya dengan nama dalam kode atau menggunakannya dalam AWS Management Console. Metrik kustom tidak tersedia untuk pilihan menggunakan AWS Management Console. Atau, Anda dapat menggunakan Application Auto Scaling API AWS CLI atau Application Auto Scaling untuk menerapkan kebijakan penskalaan berdasarkan metrik yang telah ditentukan atau kustom.
ElastiCache (Redis OSS) mendukung penskalaan untuk dimensi berikut:
-
Serpihan – Secara otomatis menambahkan/menghapus serpihan di klaster yang mirip dengan resharding online secara manual. Dalam hal ini, penskalaan otomatis ElastiCache (Redis OSS) memicu penskalaan atas nama Anda.
-
Replika – Secara otomatis menambahkan/menghapus replika di klaster yang mirip dengan operasi Meningkatkan/Menurunkan replika secara manual. ElastiCache (Redis OSS) penskalaan otomatis menambah/menghapus replika secara seragam di semua pecahan di cluster.
ElastiCache (Redis OSS) mendukung jenis kebijakan penskalaan otomatis berikut:
-
Kebijakan penskalaan pelacakan target – Tambah atau kurangi jumlah serpihan/replika yang dijalankan layanan Anda berdasarkan nilai target untuk metrik tertentu. Hal ini serupa dengan cara termostat mempertahankan suhu rumah Anda. Anda memilih suhu dan termostat melakukan sisanya.
-
Penskalaan terjadwal untuk penskalaan otomatis Aplikasi ElastiCache (Redis OSS) — Menambah atau mengurangi jumlah pecahan/replika yang dijalankan layanan Anda berdasarkan tanggal dan waktu.
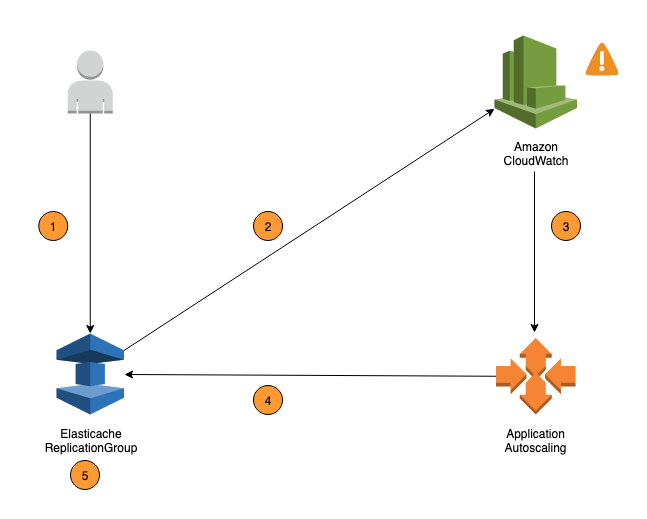
Langkah-langkah berikut merangkum proses penskalaan otomatis ElastiCache (Redis OSS) seperti yang ditunjukkan pada diagram sebelumnya:
-
Anda membuat kebijakan penskalaan otomatis ElastiCache (Redis OSS) untuk Grup Replikasi ElastiCache (Redis OSS) Anda.
-
ElastiCache (Redis OSS) auto scaling menciptakan sepasang CloudWatch alarm atas nama Anda. Setiap pasangan merepresentasikan batas atas dan bawah Anda untuk metrik. CloudWatch Alarm ini dipicu ketika penggunaan aktual cluster menyimpang dari penggunaan target Anda untuk jangka waktu yang berkelanjutan. Anda dapat melihat alarm di konsol.
-
Jika nilai metrik yang dikonfigurasi melebihi pemanfaatan target Anda (atau berada di bawah target) untuk jangka waktu tertentu, CloudWatch memicu alarm yang memanggil penskalaan otomatis ElastiCache (Redis OSS) untuk mengevaluasi kebijakan penskalaan Anda.
-
ElastiCache (Redis OSS) auto scaling mengeluarkan permintaan Modify untuk menyesuaikan kapasitas cluster Anda.
-
ElastiCache (Redis OSS) memproses permintaan Modify, secara dinamis meningkatkan (atau mengurangi) kapasitas Shards/Replicas cluster sehingga mendekati pemanfaatan target Anda.
Untuk memahami cara kerja Auto Scaling ElastiCache (Redis OSS), misalkan Anda memiliki cluster bernama. UsersCluster Dengan memantau CloudWatch metrikUsersCluster, Anda menentukan pecahan Max yang dibutuhkan cluster saat lalu lintas berada di puncaknya dan Min Shards saat lalu lintas berada pada titik terendah. Anda juga memutuskan nilai target untuk pemanfaatan CPU untuk klaster UsersCluster. ElastiCache (Redis OSS) auto scaling menggunakan algoritma pelacakan targetnya untuk memastikan bahwa pecahan yang UsersCluster disediakan disesuaikan sesuai kebutuhan sehingga pemanfaatan tetap pada atau mendekati nilai target.
catatan
Penskalaan mungkin membutuhkan waktu yang nyata dan akan membutuhkan sumber daya klaster tambahan agar pecahan dapat diseimbangkan kembali. ElastiCache (Redis OSS) Auto Scaling memodifikasi pengaturan sumber daya hanya jika beban kerja sebenarnya tetap meningkat (atau tertekan) selama beberapa menit. Algoritma pelacakan target penskalaan otomatis ElastiCache (Redis OSS) berupaya menjaga pemanfaatan target pada atau mendekati nilai yang Anda pilih dalam jangka panjang.
Izin IAM Diperlukan untuk Auto Scaling ElastiCache (Redis OSS)
ElastiCache (Redis OSS) Auto Scaling dimungkinkan oleh kombinasi (Redis OSS), ElastiCache , dan CloudWatch Application Auto Scaling API. Cluster dibuat dan diperbarui dengan ElastiCache (Redis OSS), alarm dibuat dengan CloudWatch, dan kebijakan penskalaan dibuat dengan Application Auto Scaling. Selain izin IAM standar untuk membuat dan memperbarui cluster, pengguna IAM yang mengakses pengaturan Auto Scaling ElastiCache (Redis OSS) harus memiliki izin yang sesuai untuk layanan yang mendukung penskalaan dinamis. Pengguna IAM harus memiliki izin untuk menggunakan tindakan yang ditunjukkan dalam contoh kebijakan berikut:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "application-autoscaling:*", "elasticache:DescribeReplicationGroups", "elasticache:ModifyReplicationGroupShardConfiguration", "elasticache:IncreaseReplicaCount", "elasticache:DecreaseReplicaCount", "elasticache:DescribeCacheClusters", "elasticache:DescribeCacheParameters", "cloudwatch:DeleteAlarms", "cloudwatch:DescribeAlarmHistory", "cloudwatch:DescribeAlarms", "cloudwatch:DescribeAlarmsForMetric", "cloudwatch:GetMetricStatistics", "cloudwatch:ListMetrics", "cloudwatch:PutMetricAlarm", "cloudwatch:DisableAlarmActions", "cloudwatch:EnableAlarmActions", "iam:CreateServiceLinkedRole", "sns:CreateTopic", "sns:Subscribe", "sns:Get*", "sns:List*" ], "Resource": "arn:aws:iam::123456789012:role/autoscaling-roles-for-cluster" } ] }
Peran terkait layanan
Layanan penskalaan otomatis ElastiCache (Redis OSS) juga memerlukan izin untuk menjelaskan cluster dan CloudWatch alarm Anda, dan izin untuk mengubah kapasitas target ElastiCache (Redis OSS) Anda atas nama Anda. Jika Anda mengaktifkan Auto Scaling untuk klaster ElastiCache (Redis OSS) Anda, itu akan membuat peran terkait layanan bernama. AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG Peran terkait layanan ini memberikan izin penskalaan otomatis ElastiCache (Redis OSS) untuk menjelaskan alarm kebijakan Anda, untuk memantau kapasitas armada saat ini, dan untuk memodifikasi kapasitas armada. Peran terkait layanan adalah peran default untuk penskalaan otomatis ElastiCache (Redis OSS). Untuk informasi selengkapnya, lihat Peran terkait layanan untuk penskalaan otomatis ElastiCache (Redis OSS) di Panduan Pengguna Application Auto Scaling.
Praktik Terbaik Auto Scaling
Sebelum mendaftar Auto Scaling, kami merekomendasikan hal berikut:
-
Gunakan hanya satu metrik pelacakan – Identifikasi apakah klaster Anda memiliki beban kerja yang sarat CPU atau sarat data dan gunakan metrik standar yang sesuai untuk menentukan Kebijakan Penskalaan.
-
CPU mesin:
ElastiCachePrimaryEngineCPUUtilization(dimensi serpihan) atauElastiCacheReplicaEngineCPUUtilization(dimensi replika) -
Penggunaan basis data:
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentageKebijakan penskalaan ini berfungsi paling baik dengan maxmemory-policy yang ditetapkan ke noeviction di klaster.
Kami menyarankan Anda menghindari beberapa kebijakan per dimensi pada klaster. ElastiCache (Redis OSS) Penskalaan otomatis akan menskalakan target yang dapat diskalakan jika ada kebijakan pelacakan target yang siap untuk diskalakan, tetapi akan diskalakan hanya jika semua kebijakan pelacakan target (dengan bagian penskalaan diaktifkan) siap untuk diskalakan. Jika beberapa kebijakan menginstruksikan target yang dapat diskalakan untuk menskalakan ke luar atau ke dalam pada saat yang sama, target akan diskalakan berdasarkan kebijakan yang memberikan kapasitas terbesar untuk penskalaan ke dalam dan penskalaan ke luar.
-
-
Metrik yang Disesuaikan untuk Pelacakan Target – Berhati-hatilah saat menggunakan metrik yang disesuaikan untuk Pelacakan Target karena Penskalaan otomatis paling cocok untuk penskalaan ke luar/ke dalam secara berbanding lurus dengan perubahan metrik yang dipilih untuk kebijakan. Jika metrik tersebut tidak berubah secara proporsional dengan tindakan penskalaan yang digunakan untuk pembuatan kebijakan, hal tersebut dapat menyebabkan tindakan penskalaan ke luar atau penskalaan ke dalam berkelanjutan yang dapat memengaruhi ketersediaan atau biaya.
Untuk klaster tingkatan data (jenis instans keluarga r6gd), hindari penggunaan metrik berbasis memori untuk penskalaan.
-
Penskalaan Terjadwal – Jika Anda mengidentifikasi bahwa beban kerja Anda bersifat deterministik (mencapai tinggi/rendah pada waktu tertentu), sebaiknya gunakan Penskalaan Terjadwal dan konfigurasikan kapasitas target Anda sesuai dengan kebutuhan. Pelacakan Target paling cocok untuk beban kerja non-deterministik dan agar klaster beroperasi pada metrik target yang diperlukan dengan penskalaan ke luar saat Anda membutuhkan lebih banyak sumber daya dan penskalaan ke dalam saat Anda membutuhkan lebih sedikit sumber daya.
-
Nonaktifkan Penskalaan ke Dalam – Penskalaan otomatis pada Pelacakan Target paling sesuai untuk klaster dengan peningkatan/penurunan beban kerja secara bertahap karena lonjakan/penurunan metrik dapat memicu pergantian penskalaan ke luar/ke dalam secara berturut-turut. Untuk menghindari pergantian tersebut, Anda dapat memulai dengan menonaktifkan penskalaan ke luar, dan melakukan penskalaan ke dalam secara manual sesuai kebutuhan Anda kapan saja.
-
Uji aplikasi Anda – Kami merekomendasikan Anda menguji aplikasi Anda dengan perkiraan beban kerja Min/Maks untuk menentukan serpihan/replika Min,Maks mutlak yang diperlukan untuk klaster sambil membuat kebijakan Penskalaan untuk menghindari masalah ketersediaan. Penskalaan otomatis dapat menskalakan ke luar hingga Maks dan menskalakan ke dalam hingga ambang batas Min yang dikonfigurasi untuk target.
-
Mendefinisikan Nilai Target — Anda dapat menganalisis CloudWatch metrik yang sesuai untuk pemanfaatan klaster selama periode empat minggu untuk menentukan ambang nilai target. Jika Anda masih tidak yakin nilai apa yang harus dipilih, sebaiknya mulai dengan nilai metrik standar minimum yang didukung.
-
AutoScaling pada Pelacakan Target paling cocok untuk cluster dengan distribusi beban kerja yang seragam di seluruh dimensi pecahan/replika. Memiliki distribusi yang tidak seragam dapat menyebabkan:
-
Penskalaan saat tidak diperlukan karena lonjakan/penurunan beban kerja pada beberapa serpihan/replika "hot".
-
Tidak ada penskalaan saat diperlukan karena nilai rata-rata keseluruhan mendekati target meskipun memiliki serpihan/replika "hot".
-
catatan
Saat menskalakan cluster Anda, secara otomatis ElastiCache akan mereplikasi Fungsi yang dimuat di salah satu node yang ada (dipilih secara acak) ke node baru. Jika klaster Anda memiliki Redis OSS 7.0 atau lebih tinggi dan aplikasi Anda menggunakan Fungsi Redis OSS
Setelah mendaftar AutoScaling, perhatikan hal berikut:
-
Ada batasan pada Konfigurasi yang Didukung Auto Scaling. Jadi, kami menyarankan Anda untuk tidak mengubah konfigurasi grup replikasi yang terdaftar untuk Auto Scaling. Berikut ini adalah beberapa contohnya:
-
Mengubah jenis Instans secara manual ke jenis yang tidak didukung.
-
Mengaitkan grup replikasi ke penyimpanan data Global.
-
Mengubah parameter
ReservedMemoryPercent. -
Meningkatkan/mengurangi serpihan/replika secara manual di luar kapasitas Min/Maks yang dikonfigurasi selama pembuatan kebijakan.
-
