Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat laporan penilaian multiserver di AWS Schema Conversion Tool
Untuk menentukan arah target terbaik untuk lingkungan Anda secara keseluruhan, buat laporan penilaian multiserver.
Laporan penilaian multiserver mengevaluasi beberapa server berdasarkan masukan yang Anda berikan untuk setiap definisi skema yang ingin Anda nilai. Definisi skema Anda berisi parameter koneksi server database dan nama lengkap setiap skema. Setelah menilai setiap skema, buat AWS SCT ringkasan, laporan penilaian agregat untuk migrasi database di beberapa server Anda. Laporan ini menunjukkan perkiraan kompleksitas untuk setiap target migrasi yang mungkin.
Anda dapat menggunakan AWS SCT untuk membuat laporan penilaian multiserver untuk sumber dan basis data target berikut.
| Basis data sumber | Basis data target |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Database Azure SQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Analisis Sinaps Azure |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 untuk z/OS |
Amazon Aurora Edisi yang kompatibel dengan MySQL (Aurora MySQL), Edisi Kompatibel dengan Amazon Aurora PostgreSQL (Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish untuk Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Kepingan salju |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
Melakukan penilaian multiserver
Gunakan prosedur berikut untuk melakukan penilaian multiserver dengan AWS SCT. Anda tidak perlu membuat proyek baru AWS SCT untuk melakukan penilaian multiserver. Sebelum memulai, pastikan Anda telah menyiapkan file nilai dipisahkan koma (CSV) dengan parameter koneksi database. Juga, pastikan bahwa Anda telah menginstal semua driver database yang diperlukan dan mengatur lokasi driver dalam AWS SCT pengaturan. Untuk informasi selengkapnya, lihat Menginstal driver JDBC untuk AWS Schema Conversion Tool.
Untuk melakukan penilaian multiserver dan membuat laporan ringkasan agregat
-
Di AWS SCT, pilih File, Penilaian multiserver baru. Kotak dialog penilaian multiserver baru terbuka.
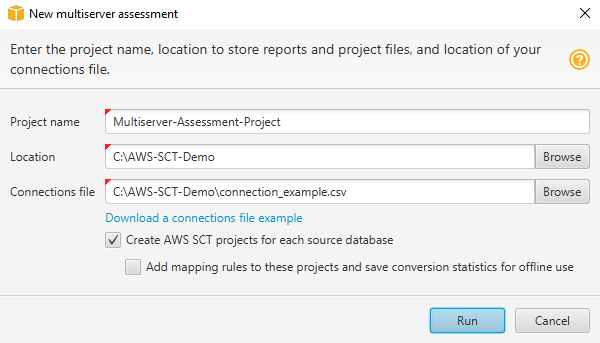
-
Pilih Unduh contoh file koneksi untuk mengunduh templat kosong file CSV dengan parameter koneksi database.
-
Masukkan nilai untuk nama Proyek, Lokasi (untuk menyimpan laporan), dan file Koneksi (file CSV).
-
Pilih Buat AWS SCT proyek untuk setiap database sumber untuk membuat proyek migrasi secara otomatis setelah membuat laporan penilaian.
-
Dengan mengaktifkan Buat AWS SCT proyek untuk setiap basis data sumber, Anda dapat memilih Tambahkan aturan pemetaan ke proyek ini dan menyimpan statistik konversi untuk penggunaan offline. Dalam hal ini, AWS SCT akan menambahkan aturan pemetaan untuk setiap proyek dan menyimpan metadata database sumber dalam proyek. Untuk informasi selengkapnya, lihat Menggunakan mode offline di AWS Schema Conversion Tool.
-
Pilih Jalankan.
Bilah kemajuan muncul yang menunjukkan kecepatan penilaian basis data. Jumlah mesin target dapat memengaruhi runtime penilaian.
-
Pilih Ya jika pesan berikut ditampilkan: Analisis lengkap dari semua server Database mungkin memakan waktu. Apakah Anda ingin melanjutkan?
Ketika laporan penilaian multiserver selesai, layar muncul yang menunjukkan demikian.
-
Pilih Buka Laporan untuk melihat laporan penilaian ringkasan gabungan.
Secara default, AWS SCT menghasilkan laporan agregat untuk semua database sumber dan laporan penilaian terperinci untuk setiap nama skema dalam database sumber. Untuk informasi selengkapnya, lihat Menemukan dan melihat laporan.
Dengan opsi Buat AWS SCT proyek untuk setiap database sumber diaktifkan, AWS SCT buat proyek kosong untuk setiap database sumber. AWS SCT juga membuat laporan penilaian seperti yang dijelaskan sebelumnya. Setelah Anda menganalisis laporan penilaian ini dan memilih tujuan migrasi untuk setiap database sumber, tambahkan database target ke proyek kosong ini.
Dengan opsi Tambahkan aturan pemetaan ke proyek ini dan simpan statistik konversi untuk penggunaan offline diaktifkan, AWS SCT buat proyek untuk setiap basis data sumber. Proyek-proyek ini mencakup informasi berikut:
Database sumber Anda dan platform basis data target virtual. Untuk informasi selengkapnya, lihat Pemetaan ke target virtual di AWS Schema Conversion Tool.
Aturan pemetaan untuk pasangan sumber-target ini. Untuk informasi selengkapnya, lihat Pemetaan tipe data.
Laporan penilaian migrasi database untuk pasangan sumber-target ini.
Metadata skema sumber, yang memungkinkan Anda menggunakan AWS SCT proyek ini dalam mode offline. Untuk informasi selengkapnya, lihat Menggunakan mode offline di AWS Schema Conversion Tool.
Mempersiapkan file CSV input
Untuk menyediakan parameter koneksi sebagai input untuk laporan penilaian multiserver, gunakan file CSV seperti yang ditunjukkan pada contoh berikut.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
Contoh sebelumnya menggunakan titik koma untuk memisahkan dua nama skema untuk database. Sales Ini juga menggunakan titik koma untuk memisahkan dua platform migrasi database target untuk database. Sales
Juga, contoh sebelumnya digunakan AWS Secrets Manager untuk terhubung ke Customers database dan Windows Authentication untuk terhubung ke database. HR
Anda dapat membuat file CSV baru atau mengunduh templat untuk file CSV dari AWS SCT dan mengisi informasi yang diperlukan. Pastikan baris pertama file CSV Anda menyertakan nama kolom yang sama seperti yang ditunjukkan pada contoh sebelumnya.
Untuk mengunduh template file CSV masukan
Mulai AWS SCT.
Pilih File, lalu pilih Penilaian multiserver baru.
Pilih Unduh contoh file koneksi.
Pastikan bahwa file CSV Anda menyertakan nilai-nilai berikut, yang disediakan oleh template:
-
Nama — Label teks yang membantu mengidentifikasi database Anda. AWS SCT menampilkan label teks ini dalam laporan penilaian.
-
Deskripsi — Nilai opsional, di mana Anda dapat memberikan informasi tambahan tentang database.
-
Secret Manager Key — Nama rahasia yang menyimpan kredensi database Anda di. AWS Secrets Manager Untuk menggunakan Secrets Manager, pastikan Anda menyimpan AWS profil AWS SCT. Untuk informasi selengkapnya, lihat Mengkonfigurasi AWS Secrets Manager di AWS Schema Conversion Tool.
penting
AWS SCT mengabaikan parameter Kunci Manajer Rahasia jika Anda menyertakan parameter Server IP, Port, Login, dan Kata Sandi dalam file input.
-
Server IP — Nama Domain Name Service (DNS) atau alamat IP dari server basis data sumber Anda.
-
Port — Port yang digunakan untuk terhubung ke server database sumber Anda.
-
Nama Layanan — Jika Anda menggunakan nama layanan untuk terhubung ke database Oracle Anda, nama layanan Oracle untuk terhubung ke.
-
Nama database — Nama database. Untuk database Oracle, gunakan Oracle System ID (SID).
-
BigQuery path — path ke file kunci akun layanan untuk BigQuery database sumber Anda. Untuk informasi selengkapnya tentang membuat file ini, lihatHak istimewa untuk BigQuery sebagai sumber.
-
Source Engine — Jenis database sumber Anda. Gunakan salah satu nilai berikut:
AZURE_MSSQL untuk Database Azure SQL.
AZURE_SYNAPSE untuk database Azure Synapse Analytics.
GOOGLE_BIGQUERY untuk database. BigQuery
DB2ZOS untuk IBM Db2 untuk database z/OS.
DB2LUW untuk database IBM Db2 LUW.
GREENPLUM untuk database Greenplum.
MSSQL untuk database Microsoft SQL Server.
MYSQL untuk database MySQL.
NETEZZA untuk database Netezza.
ORACLE untuk database Oracle.
POSTGRESQL untuk database PostgreSQL.
REDSHIFT untuk database Amazon Redshift.
SNOWFLAKE untuk database Snowflake.
SYBASE_ASE untuk database SAP ASE.
TERADATA untuk database Teradata.
VERTICA untuk database Vertica.
-
Nama Skema — Nama-nama skema database untuk dimasukkan dalam laporan penilaian.
Untuk Azure SQL Database, Azure Synapse Analytics, Netezza BigQuery, SAP ASE, Snowflake, dan SQL Server, gunakan format nama skema berikut:
db_name.schema_nameGanti
db_nameGanti
schema_nameLampirkan nama database atau skema yang menyertakan titik dalam tanda kutip ganda seperti yang ditunjukkan berikut:.
"database.name"."schema.name"Pisahkan beberapa nama skema dengan menggunakan titik koma seperti yang ditunjukkan berikut:.
Schema1;Schema2Nama database dan skema peka huruf besar/kecil.
Gunakan percent (
%) sebagai wildcard untuk mengganti sejumlah simbol apa pun dalam database atau nama skema. Contoh sebelumnya menggunakan percent (%) sebagai wildcard untuk memasukkan semua skema dariemployeesdatabase dalam laporan penilaian. -
Gunakan Otentikasi Windows - Jika Anda menggunakan Otentikasi Windows untuk terhubung ke database Microsoft SQL Server Anda, masukkan true. Untuk informasi selengkapnya, lihat Menggunakan Otentikasi Windows saat menggunakan Microsoft SQL Server sebagai sumber.
-
Login — Nama pengguna untuk terhubung ke server database sumber Anda.
-
Kata sandi — Kata sandi untuk terhubung ke server basis data sumber Anda.
-
Gunakan SSL — Jika Anda menggunakan Secure Sockets Layer (SSL) untuk terhubung ke database sumber Anda, masukkan true.
-
Trust store — Toko kepercayaan yang digunakan untuk koneksi SSL Anda.
-
Key store — Toko kunci yang digunakan untuk koneksi SSL Anda.
-
Otentikasi SSL - Jika Anda menggunakan otentikasi SSL berdasarkan sertifikat, masukkan true.
-
Mesin Target — Platform basis data target. Gunakan nilai berikut untuk menentukan satu atau beberapa target dalam laporan penilaian:
AURORA_MYSQL untuk database yang kompatibel dengan Aurora MySQL.
AURORA_POSTGRESQL untuk database yang kompatibel dengan Aurora PostgreSQL.
BABELFISH untuk database Babelfish untuk Aurora PostgreSQL.
MARIA_DB untuk database MariaDB.
MSSQL untuk database Microsoft SQL Server.
MYSQL untuk database MySQL.
ORACLE untuk database Oracle.
POSTGRESQL untuk database PostgreSQL.
REDSHIFT untuk database Amazon Redshift.
Pisahkan beberapa target dengan menggunakan titik koma seperti ini:.
MYSQL;MARIA_DBJumlah target mempengaruhi waktu yang dibutuhkan untuk menjalankan penilaian.
Menemukan dan melihat laporan
Penilaian multiserver menghasilkan dua jenis laporan:
-
Laporan agregat dari semua database sumber.
-
Laporan penilaian rinci dari database target untuk setiap nama skema dalam database sumber.
Laporan disimpan di direktori yang Anda pilih untuk Lokasi di kotak dialog Penilaian multiserver baru.
Untuk mengakses laporan terperinci, Anda dapat menavigasi subdirektori, yang diatur oleh database sumber, nama skema, dan mesin basis data target.
Laporan agregat menampilkan informasi dalam empat kolom tentang kompleksitas konversi database target. Kolom mencakup informasi tentang konversi objek kode, objek penyimpanan, elemen sintaks, dan kompleksitas konversi.
Contoh berikut menunjukkan informasi untuk konversi dua skema database Oracle ke Amazon RDS for PostgreSQL.

Empat kolom yang sama ditambahkan ke laporan untuk setiap mesin basis data target tambahan yang ditentukan.
Untuk detail tentang cara membaca informasi ini, lihat berikut.
Output untuk laporan penilaian agregat
Laporan penilaian migrasi database multiserver agregat di AWS Schema Conversion Tool adalah file CSV dengan kolom berikut:
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
Untuk mengumpulkan informasi, AWS SCT jalankan laporan penilaian lengkap dan kemudian agregat laporan berdasarkan skema.
Dalam laporan tersebut, tiga bidang berikut menunjukkan persentase kemungkinan konversi otomatis berdasarkan penilaian:
- Konversi objek kode%
-
Persentase objek kode dalam skema yang AWS SCT dapat dikonversi secara otomatis atau dengan perubahan minimal. Objek kode termasuk prosedur, fungsi, tampilan, dan sejenisnya.
- Konversi objek penyimpanan%
-
Persentase objek penyimpanan yang SCT dapat mengkonversi secara otomatis atau dengan sedikit perubahan. Objek penyimpanan termasuk tabel, indeks, kendala, dan sejenisnya.
- Elemen sintaks konversi%
-
Persentase elemen sintaks yang SCT dapat mengkonversi secara otomatis. Elemen sintaks meliputi
SELECT,FROM,DELETE, danJOINklausa, dan serupa.
Perhitungan kompleksitas konversi didasarkan pada gagasan item tindakan. Item tindakan mencerminkan jenis masalah yang ditemukan dalam kode sumber yang perlu Anda perbaiki secara manual selama migrasi ke target tertentu. Item tindakan dapat memiliki beberapa kejadian.
Timbangan tertimbang mengidentifikasi tingkat kompleksitas untuk melakukan migrasi. Angka 1 mewakili tingkat kompleksitas terendah, dan angka 10 mewakili tingkat kompleksitas tertinggi.
