Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik untuk kueri dan pemindaian data di DynamoDB
Bagian ini membahas beberapa praktik terbaik untuk menggunakan operasi Query dan Scan di Amazon DynamoDB.
Pertimbangan performa untuk pemindaian
Secara umum, efisiensi operasi Scan lebih rendah daripada operasi lain di DynamoDB. Operasi Scan selalu memindai seluruh tabel atau indeks sekunder. Kemudian, operasi ini memfilter nilai-nilai untuk memberikan hasil yang Anda inginkan, yang pada dasarnya menambahkan langkah tambahan untuk menghapus data dari kumpulan hasil.
Jika memungkinkan, Anda harus menghindari penggunaan operasi Scan pada indeks atau tabel besar dengan filter yang menghapus banyak hasil. Selain itu, seiring dengan berkembangnya tabel atau indeks, operasi Scan melambat. Operasi Scan memeriksa setiap item untuk nilai yang diminta dan dapat menggunakan throughput yang disediakan untuk indeks atau tabel besar dalam satu operasi. Untuk waktu respons yang lebih cepat, rancang tabel dan indeks Anda agar aplikasi Anda dapat menggunakan Query, bukan Scan. (Untuk tabel, Anda juga dapat mempertimbangkan untuk menggunakan GetItem dan BatchGetItem APIs.)
Atau, Anda dapat merancang aplikasi Anda untuk menggunakan operasi Scan dengan cara yang meminimalkan dampak pada tingkat permintaan Anda. Ini dapat mencakup pemodelan jika penggunaan indeks sekunder global mungkin lebih efisien daripada operasi Scan. Informasi selengkapnya tentang proses ini ada di video berikut.
Menghindari lonjakan mendadak dalam aktivitas baca
Jika Anda membuat tabel, Anda akan mengatur persyaratan unit kapasitas baca dan tulisnya. Untuk baca, unit kapasitasnya dinyatakan sebagai jumlah permintaan baca data 4 KB yang sangat konsisten per detik. Untuk bacaan akhir konsisten, unit kapasitas baca memiliki dua permintaan baca 4 KB per detik. Operasi Scan melakukan bacaan akhir konsisten default, dan dapat mengembalikan hingga 1 MB (satu halaman) data. Oleh karena itu, satu permintaan Scan dapat menggunakan (ukuran halaman 1 MB / ukuran item 4 KB) / 2 (bacaan akhir konsisten) = 128 operasi baca. Jika Anda meminta bacaan sangat konsisten, operasi Scan akan menggunakan throughput yang disediakan dua kali lebih banyak – 256 operasi baca.
Hal ini menunjukkan lonjakan tiba-tiba pada penggunaan, dibandingkan dengan kapasitas baca yang dikonfigurasi untuk tabel. Penggunaan unit kapasitas melalui pemindaian ini mencegah permintaan lain yang berpotensi lebih penting untuk tabel yang sama menggunakan unit kapasitas yang tersedia. Akibatnya, Anda mungkin mendapatkan pengecualian ProvisionedThroughputExceeded untuk permintaan tersebut.
Masalahnya bukan hanya peningkatan mendadak pada unit kapasitas yang digunakan Scan. Pemindaian juga kemungkinan akan menggunakan semua unit kapasitasnya dari partisi yang sama karena pemindaian meminta item baca yang berdampingan di partisi. Artinya, permintaan tersebut mengenai partisi yang sama, sehingga menyebabkan semua unit kapasitasnya terpakai, dan membatasi permintaan lain ke partisi tersebut. Jika permintaan untuk membaca data tersebar di beberapa partisi, operasi tidak akan membatasi partisi tertentu.
Diagram berikut mengilustrasikan dampak lonjakan penggunaan unit kapasitas secara mendadak oleh operasi Query dan Scan, serta dampaknya pada permintaan Anda lainnya terhadap tabel yang sama.
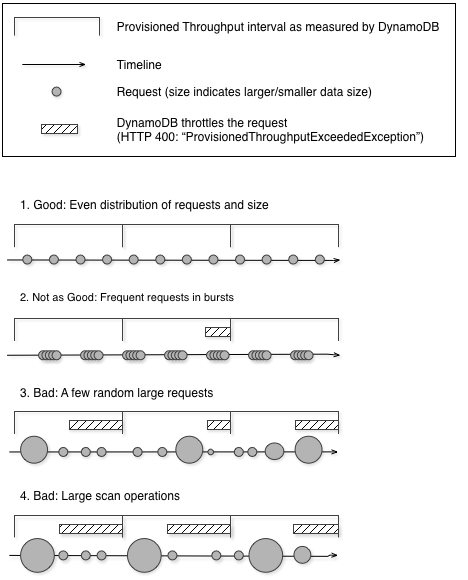
Seperti yang diilustrasikan di sini, lonjakan penggunaan dapat memengaruhi throughput yang disediakan pada tabel dalam beberapa cara:
-
Baik: Distribusi permintaan dan ukuran yang merata
-
Tidak cukup baik: Permintaan yang sering terjadi secara beruntun
-
Buruk: Beberapa permintaan besar acak
-
Buruk: Operasi pemindaian besar
Daripada menggunakan operasi Scan besar, Anda dapat menggunakan teknik berikut untuk meminimalkan dampak pemindaian pada throughput yang disediakan di tabel.
-
Mengurangi ukuran halaman
Karena operasi Pindai membaca seluruh halaman (secara default, 1 MB), Anda dapat mengurangi dampak operasi pemindaian dengan mengatur ukuran halaman yang lebih kecil. Operasi
Scanmenyediakan parameter Limit yang dapat Anda gunakan untuk mengatur ukuran halaman untuk permintaan Anda. Setiap permintaanQueryatauScanyang memiliki ukuran halaman yang lebih kecil menggunakan lebih sedikit operasi baca dan membuat "jeda" di antara setiap permintaan. Misalnya, katakanlah setiap item berukuran 4 KB dan Anda mengatur ukuran halamannya menjadi 40 item. PermintaanQuerykemudian hanya akan menggunakan 20 operasi bacaan akhir konsisten atau 40 operasi bacaan sangat konsisten. Sejumlah besar operasiQueryatauScanyang lebih kecil akan memungkinkan permintaan penting Anda yang lain untuk berhasil tanpa mengalami throttling. -
Mengisolasi operasi pemindaian
DynamoDB dirancang untuk skalabilitas yang mudah. Dengan demikian, aplikasi dapat membuat tabel untuk tujuan yang berbeda, bahkan mungkin menduplikasi konten di beberapa tabel. Anda ingin melakukan pemindaian pada tabel yang tidak mengambil lalu lintas "vital". Beberapa aplikasi menangani beban ini dengan memutar lalu lintas setiap jam antara dua tabel—satu untuk lalu lintas vital, dan satu lagi untuk pembukuan. Aplikasi lain dapat melakukan ini dengan melakukan setiap penulisan pada dua tabel: tabel "vital", dan tabel "bayangan".
Konfigurasikan aplikasi Anda untuk mencoba kembali permintaan apa pun yang menerima kode respons yang menunjukkan bahwa Anda telah melampaui throughput yang disediakan. Atau, tingkatkan throughput yang disediakan untuk tabel Anda menggunakan operasi UpdateTable. Jika Anda mengalami lonjakan sementara dalam beban kerja yang menyebabkan throughput Anda melebihi, terkadang, melampaui tingkat yang disediakan, coba ulang permintaan dengan penundaan eksponensial. Untuk informasi selengkapnya tentang cara mengimplementasikan penundaan eksponensial, lihat Percobaan ulang kesalahan dan penundaan eksponensial.
Memanfaatkan pemindaian paralel
Banyak aplikasi mendapatkan keuntungan dari penggunaan operasi Scan paralel dibandingkan pemindaian berurutan. Misalnya, aplikasi yang memproses tabel data historis besar dapat melakukan pemindaian paralel jauh lebih cepat dibandingkan pemindaian berurutan. Beberapa thread pekerja dalam proses "sweeper" latar belakang dapat memindai tabel dengan prioritas rendah tanpa memengaruhi lalu lintas produksi. Dalam masing-masing contoh ini, Scan paralel digunakan sedemikian rupa sehingga tidak membuat aplikasi lain kekurangan sumber daya throughput yang disediakan.
Meskipun pemindaian paralel menguntungkan, pemindaian ini dapat memberikan tuntutan besar pada throughput yang disediakan. Dengan pemindaian paralel, aplikasi Anda memiliki beberapa pekerja yang semuanya menjalankan operasi Scan secara bersamaan. Operasi ini dapat dengan cepat menghabiskan seluruh kapasitas baca yang disediakan pada tabel Anda. Dalam hal ini, aplikasi lain yang perlu mengakses tabel mungkin akan mengalami throttling.
Pemindaian paralel dapat menjadi pilihan tepat jika kondisi berikut terpenuhi:
Ukuran tabel sebesar 20 GB atau lebih.
Throughput baca yang disediakan pada tabel tidak digunakan sepenuhnya.
Operasi
Scanyang berurutan terlalu lambat.
Memilih TotalSegments
Pengaturan terbaik untuk TotalSegments tergantung pada data spesifik Anda, pengaturan throughput yang disediakan pada tabel, dan kebutuhan performa Anda. Anda mungkin perlu bereksperimen untuk melakukannya dengan benar. Sebaiknya mulai dengan rasio sederhana, seperti satu segmen per 2 GB data. Misalnya, untuk tabel 30 GB, Anda dapat mengatur TotalSegments ke 15 (30 GB / 2 GB). Aplikasi Anda kemudian akan menggunakan 15 pekerja, masing-masing pekerja memindai segmen yang berbeda.
Anda juga dapat memilih nilai untuk TotalSegments yang didasarkan pada sumber daya klien. Anda dapat mengatur TotalSegments ke angka berapa pun dari 1 hingga 1000000, dan DynamoDB akan memungkinkan Anda memindai jumlah segmen tersebut. Misalnya, jika klien Anda membatasi jumlah thread yang dapat berjalan secara bersamaan, Anda dapat meningkatkan TotalSegments secara bertahap hingga mendapatkan performa Scan terbaik dengan aplikasi Anda.
Pantau pemindaian paralel Anda untuk mengoptimalkan penggunaan throughput yang disediakan, sekaligus memastikan bahwa aplikasi Anda yang lain tidak kekurangan sumber daya. Tingkatkan nilai TotalSegments jika Anda tidak menggunakan seluruh throughput yang disediakan tetapi masih mengalami throttling dalam permintaan Scan Anda. Kurangi nilai TotalSegments jika permintaan Scan menggunakan lebih banyak throughput yang disediakan daripada yang ingin Anda gunakan.
