Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat danau data Amazon Chime SDK
Danau data analitik panggilan Amazon Chime SDK memungkinkan Anda mengalirkan wawasan yang didukung pembelajaran mesin dan metadata apa pun dari Amazon Kinesis Data Stream ke bucket Amazon S3 Anda. Misalnya, menggunakan data lake URLs untuk mengakses rekaman. Untuk membuat data lake, Anda menerapkan satu set AWS CloudFormation template baik dari konsol Amazon Chime SDK atau secara terprogram menggunakan. AWS CLI Data lake memungkinkan Anda untuk menanyakan metadata panggilan dan data analitik suara Anda dengan AWS mereferensikan tabel data Glue di Amazon Athena.
Topik
Prasyarat
Anda harus memiliki item berikut untuk membuat danau Amazon Chime SDK:
-
Aliran data Amazon Kinesis. Untuk informasi selengkapnya, lihat Membuat Stream melalui AWS Management Console di Panduan Pengembang Amazon Kinesis Streams.
-
Ember S3. Untuk informasi selengkapnya, lihat Membuat bucket Amazon S3 pertama Anda di Panduan Pengguna Amazon S3.
Terminologi dan konsep data lake
Gunakan istilah dan konsep berikut untuk memahami cara kerja data lake.
- Amazon Kinesis Data Firehose
-
Layanan ekstrak, transformasi, dan muat (ETL) yang andal menangkap, mengubah, dan mengirimkan data streaming ke data lake, penyimpanan data, dan layanan analitik. Untuk informasi selengkapnya, lihat Apa Itu Amazon Kinesis Data Firehose?
- Amazon Athena
-
Amazon Athena adalah layanan kueri interaktif yang memungkinkan Anda menganalisis data di Amazon S3 menggunakan SQL standar. Athena tanpa server, jadi Anda tidak memiliki infrastruktur untuk dikelola, dan Anda hanya membayar untuk kueri yang Anda jalankan. Untuk menggunakan Athena, arahkan ke data Anda di Amazon S3, tentukan skema, dan gunakan kueri SQL standar. Anda juga dapat menggunakan grup kerja untuk mengelompokkan pengguna dan mengontrol sumber daya yang dapat mereka akses saat menjalankan kueri. Workgroup memungkinkan Anda mengelola konkurensi kueri dan memprioritaskan eksekusi kueri di berbagai grup pengguna dan beban kerja.
- Katalog Data Glue
-
Di Amazon Athena, tabel dan database berisi metadata yang merinci skema untuk data sumber yang mendasarinya. Untuk setiap dataset, tabel harus ada di Athena. Metadata dalam tabel memberi tahu Athena lokasi bucket Amazon S3 Anda. Ini juga menentukan struktur data, seperti nama kolom, tipe data, dan nama tabel. Database hanya menyimpan informasi metadata dan skema untuk kumpulan data.
Membuat beberapa danau data
Beberapa data lake dapat dibuat dengan menyediakan nama database Glue yang unik untuk menentukan tempat menyimpan wawasan panggilan. Untuk AWS akun tertentu, mungkin ada beberapa konfigurasi analitik panggilan, masing-masing dengan data lake yang sesuai. Ini berarti bahwa pemisahan data dapat diterapkan untuk kasus penggunaan tertentu, seperti menyesuaikan kebijakan retensi, dan kebijakan akses tentang bagaimana data disimpan. Mungkin ada kebijakan keamanan berbeda yang diterapkan untuk akses wawasan, rekaman, dan metadata.
Data ketersediaan regional danau
Danau data Amazon Chime SDK tersedia di Wilayah berikut.
Wilayah |
Glue meja |
QuickSight |
|---|---|---|
us-east-1 |
Tersedia |
Tersedia |
us-west-2 |
Tersedia |
Tersedia |
eu-central-1 |
Tersedia |
Tersedia |
Arsitektur danau data
Diagram berikut menunjukkan arsitektur danau data. Angka dalam gambar sesuai dengan teks bernomor di bawah ini.
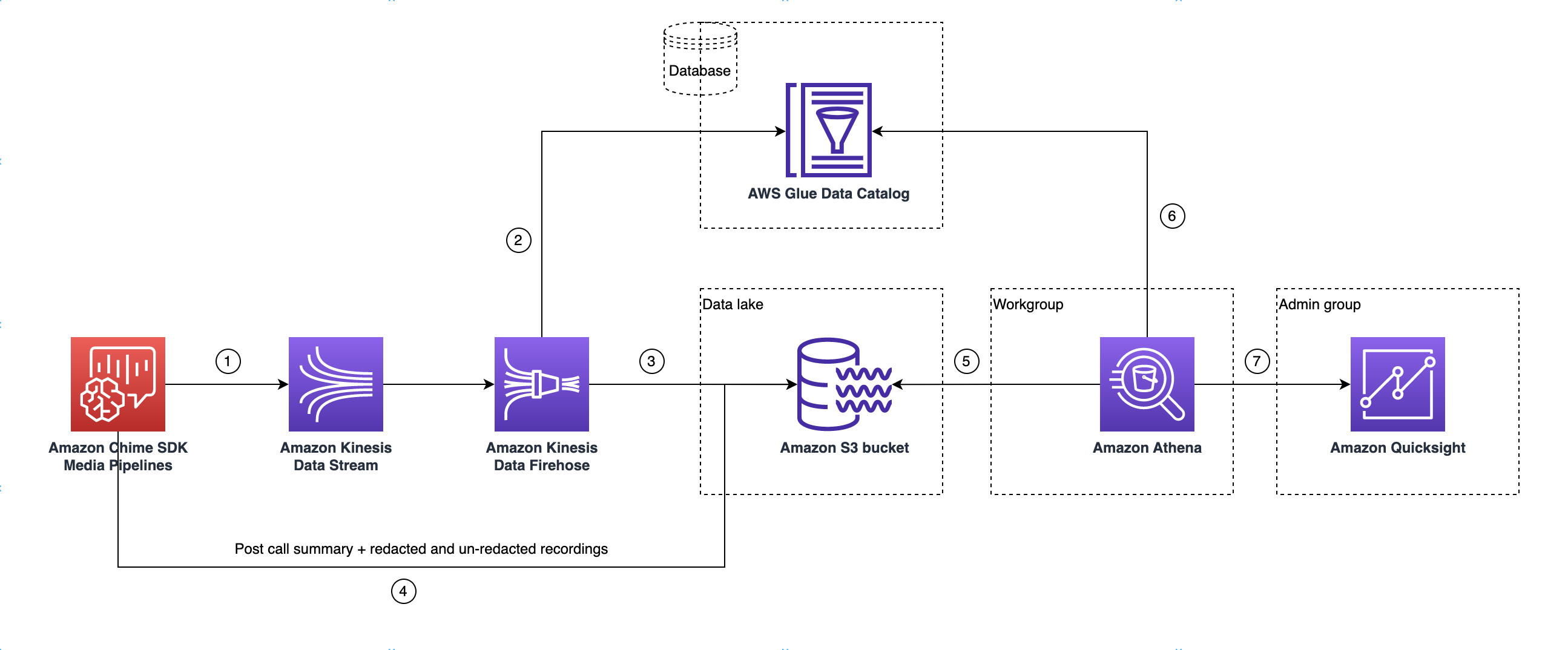
Dalam diagram, setelah Anda menggunakan AWS konsol untuk menerapkan CloudFormation template dari alur kerja penyiapan konfigurasi pipeline media insights, data berikut akan mengalir ke bucket Amazon S3:
-
Analisis panggilan Amazon Chime SDK akan mulai mengalirkan data real-time ke Kinesis Data Stream pelanggan.
-
Amazon Kinesis Firehose menyangga data waktu nyata ini hingga terakumulasi 128 MB, atau 60 detik berlalu, mana yang pertama. Firehose kemudian menggunakan
amazon_chime_sdk_call_analytics_firehose_schemadalam Katalog Data Glue untuk mengompres data dan mengubah catatan JSON menjadi file parket. -
File parket berada di bucket Amazon S3 Anda, dalam format yang dipartisi.
-
Selain data real-time, Amazon Transcribe Call Analytics pasca-panggilan meringkas file.wav (disunting dan tidak disunting, jika ditentukan dalam konfigurasi), dan rekaman panggilan file.wav juga dikirim ke Amazon S3 Bucket Anda.
-
Anda dapat menggunakan Amazon Athena dan SQL standar untuk menanyakan data di bucket Amazon S3.
-
CloudFormation Template juga membuat Katalog Data Glue untuk menanyakan data ringkasan pasca-panggilan ini melalui Athena.
-
Semua data di bucket Amazon S3 juga dapat divisualisasikan menggunakan. QuickSight QuickSight membangun koneksi dengan bucket Amazon S3 menggunakan Amazon Athena.
Tabel Amazon Athena menggunakan fitur berikut untuk mengoptimalkan kinerja kueri:
- Pembuatan Partisi Data
-
Partisi membagi tabel Anda menjadi beberapa bagian dan menyimpan data terkait bersama-sama berdasarkan nilai kolom seperti tanggal, negara, dan wilayah. Partisi bertindak sebagai kolom virtual. Dalam hal ini, CloudFormation template mendefinisikan partisi pada pembuatan tabel, yang membantu mengurangi jumlah data yang dipindai per kueri dan meningkatkan kinerja. Anda juga dapat memfilter berdasarkan partisi untuk membatasi jumlah data yang dipindai oleh kueri. Untuk informasi selengkapnya, lihat Mempartisi data di Athena di Panduan Pengguna Amazon Athena.
Contoh ini menunjukkan struktur partisi dengan tanggal 1 Januari 2023:
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
di mana
DETAIL_TYPEadalah salah satu dari berikut ini:-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- Optimalkan pembuatan penyimpanan data kolumnar
-
Apache Parquet menggunakan kompresi kolom, kompresi berdasarkan tipe data, dan predikat pushdown untuk menyimpan data. Rasio kompresi yang lebih baik atau melewatkan blok data berarti membaca lebih sedikit byte dari bucket Amazon S3 Anda. Itu mengarah pada kinerja kueri yang lebih baik dan pengurangan biaya. Untuk pengoptimalan ini, konversi data dari JSON ke parket diaktifkan di Amazon Kinesis Data Firehose.
- Partisi
-
Fitur Athena ini secara otomatis membuat partisi untuk setiap hari untuk meningkatkan kinerja kueri berbasis tanggal.
Pengaturan danau data
Gunakan konsol Amazon Chime SDK untuk menyelesaikan langkah-langkah berikut.
-
Mulai konsol Amazon Chime SDK ( https://console.aws.amazon.com/chime-sdk/home
) dan di panel navigasi, di bawah Call Analytics, pilih Konfigurasi. -
Selesaikan Langkah 1, pilih Berikutnya dan pada halaman Langkah 2, pilih kotak centang Voice Analytics.
-
Di bawah Rincian keluaran, pilih kotak centang Data warehouse untuk melakukan analisis historis, lalu pilih tautan Deploy CloudFormation stack.
Sistem mengirim Anda ke halaman Quick create stack di CloudFormation konsol.
-
Masukkan nama untuk tumpukan, lalu masukkan parameter berikut:
-
DataLakeType— Pilih Buat Analisis Panggilan DataLake. -
KinesisDataStreamName— Pilih aliran Anda. Ini harus menjadi aliran yang digunakan untuk streaming analitik panggilan. -
S3BucketURI— Pilih ember Amazon S3 Anda. URI harus memiliki awalans3://bucket-name -
GlueDatabaseName— Pilih nama Database AWS Glue yang unik. Anda tidak dapat menggunakan kembali database yang ada di AWS akun.
-
-
Pilih kotak centang pengakuan, lalu pilih Buat danau data. Biarkan 10 menit agar sistem membuat danau.
Pengaturan danau data menggunakan AWS CLI
Gunakan AWS CLI untuk membuat peran dengan izin untuk memanggil CloudFormation tumpukan create. Ikuti prosedur di bawah ini untuk membuat dan mengatur peran IAM. Untuk informasi selengkapnya, lihat Membuat tumpukan di Panduan AWS CloudFormation Pengguna.
-
Buat peran yang disebut AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role dan lampirkan kebijakan kepercayaan ke peran yang memungkinkan untuk mengambil peran tersebut. CloudFormation
-
Buat kebijakan kepercayaan IAM menggunakan templat berikut dan simpan file dalam format.json.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
Jalankan aws iam create-role perintah dan teruskan kebijakan kepercayaan sebagai parameter.
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
Catat peran arn yang dikembalikan dari respons. peran arn diperlukan pada langkah berikutnya.
-
-
Buat kebijakan dengan izin untuk membuat CloudFormation tumpukan.
-
Buat kebijakan IAM menggunakan template berikut dan simpan file dalam format.json. File ini diperlukan saat memanggil create-policy.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
Jalankan aws iam create-policy dan lewati buat kebijakan tumpukan sebagai parameter.
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
Catat peran arn yang dikembalikan dari respons. peran arn diperlukan pada langkah berikutnya.
-
-
Lampirkan kebijakan aws iam attach-role-policy pada peran tersebut.
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
Buat CloudFormation tumpukan dan masukkan parameter yang diperlukan:aws cloudformation create-stack.
Berikan nilai parameter untuk setiap ParameterKey penggunaan ParameterValue.
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
Sumber daya yang dibuat oleh penyiapan danau data
Tabel berikut mencantumkan sumber daya yang dibuat saat Anda membuat data lake.
Jenis sumber daya |
Nama dan deskripsi sumber daya |
Nama layanan |
|---|---|---|
Database Katalog Data AWS Glue |
GlueDatabaseName— Secara logis mengelompokkan semua tabel AWS Glue Data milik wawasan panggilan dan analitik suara. |
Analisis panggilan, analitik suara |
|
Tabel Katalog Data AWS Glue |
amazon_chime_sdk_call_analytics_firehose_schema — Skema gabungan untuk analitik panggilan analitik suara yang diumpankan ke Kinesis Firehose. |
Analisis panggilan, analitik suara |
call_analytics_metadata — Skema untuk metadata analitik panggilan. Berisi SIPmetadata dan OneTimeMetadata. |
Analitik panggilan |
|
| call_analytics_recording_metadata — Skema untuk metadata Perekaman dan Peningkatan Suara | Analisis panggilan, analitik suara | |
transcribe_call_analytics — Skema untuk Payload “utteranceEvent” TranscribeCallAnalytics |
Analitik panggilan |
|
transcribe_call_analytics_category_events — Skema untuk Payload “CategoryEvent” TranscribeCallAnalytics |
Analitik panggilan |
|
transcribe_call_analytics_post_call — Skema untuk Pasca Panggilan Transcribe Call Analytics ringkasan payload |
Analitik panggilan |
|
transcribe — Skema untuk Transcribe Payload |
Analitik panggilan |
|
voice_analytics_status - Skema untuk acara siap analitik suara |
Analitik suara |
|
speaker_search_status — Skema untuk kecocokan identifikasi |
Analitik suara |
|
voice_tone_analysis_status — Skema untuk acara analisis nada suara |
Analitik suara |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-Call-Analytics- — |
Analisis panggilan, analitik suara |
Kelompok Kerja Amazon Athena |
GlueDatabaseName- AmazonChime SDKData Analytics - Kelompok pengguna logis untuk mengontrol sumber daya yang mereka akses saat menjalankan kueri. |
Analisis panggilan, analitik suara |
