Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Melihat anomali reaktif
Dalam wawasan, Anda dapat melihat anomali untuk sumber daya Amazon RDS. Pada halaman wawasan reaktif, di bagian Metrik Teragregasi, Anda dapat melihat daftar anomali dengan garis waktu yang sesuai. Ada juga bagian yang menampilkan informasi tentang grup log dan peristiwa yang terkait dengan anomali. Anomali kausal dalam wawasan reaktif masing-masing memiliki halaman yang sesuai dengan detail tentang anomali.
Melihat analisis terperinci dari anomali reaktif RDS
Pada tahap ini, telusuri anomali untuk mendapatkan analisis dan rekomendasi terperinci untuk instans Amazon RDS DB Anda.
Analisis terperinci hanya tersedia untuk instans Amazon RDS DB yang mengaktifkan Performance Insights.
Untuk menelusuri halaman detail anomali
-
Pada halaman wawasan, temukan metrik agregat dengan tipe sumber daya AWS/RDS.
-
Pilih Lihat detail.
Halaman detail anomali muncul. Judul dimulai dengan anomali kinerja Database dan menamai pertunjukan sumber daya. Konsol default ke anomali dengan tingkat keparahan tertinggi, terlepas dari kapan anomali terjadi.
-
(Opsional) Jika beberapa sumber daya terpengaruh, pilih sumber daya yang berbeda dari daftar di bagian atas halaman.
Berikut ini, Anda dapat menemukan deskripsi untuk komponen halaman detail.
Ikhtisar sumber daya
Bagian atas halaman detail adalah Ikhtisar sumber daya. Bagian ini merangkum anomali kinerja yang dialami oleh instans Amazon RDS DB Anda.
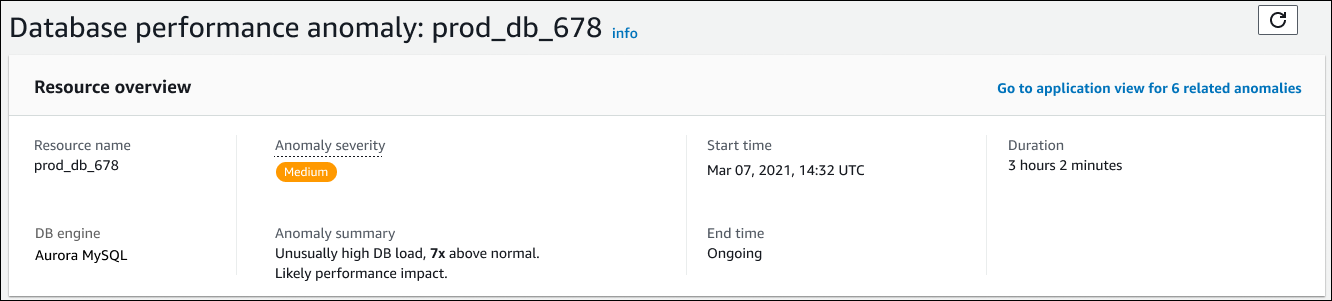
Bagian ini memiliki bidang-bidang berikut:
-
Nama sumber daya — Nama instans DB yang mengalami anomali. Dalam contoh ini, sumber daya diberi nama prod_db_678.
-
Mesin DB — Nama instans DB yang mengalami anomali. Dalam contoh ini, mesinnya adalah Aurora MySQL.
-
Tingkat keparahan anomali — Ukuran dampak negatif anomali pada contoh Anda. Kemungkinan tingkat keparahan adalah Tinggi, Sedang, dan Rendah.
-
Ringkasan anomali — Ringkasan singkat dari masalah ini. Ringkasan tipikal adalah beban DB yang luar biasa tinggi.
-
Waktu mulai dan Waktu akhir — Waktu ketika anomali dimulai dan berakhir. Jika waktu akhir sedang berlangsung, anomali masih terjadi.
-
Durasi — Durasi perilaku anomali. Dalam contoh ini, anomali sedang berlangsung dan telah terjadi selama 3 jam 2 menit.
Metrik primer
Bagian metrik Primer merangkum anomali kasual, yang merupakan anomali tingkat atas dalam wawasan. Anda dapat menganggap anomali kausal sebagai masalah umum yang dialami oleh instans DB Anda.
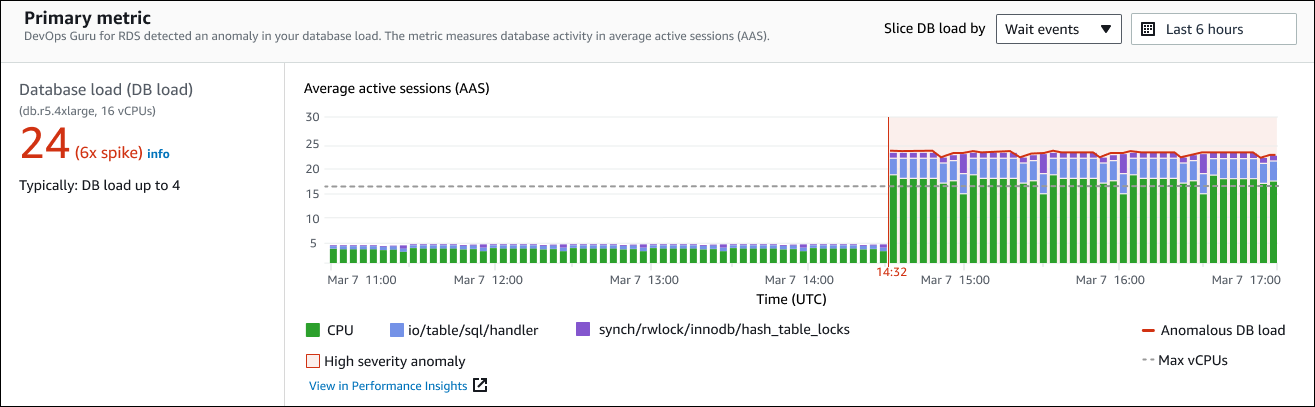
Panel kiri memberikan detail lebih lanjut tentang masalah ini. Dalam contoh ini, ringkasan mencakup informasi berikut:
-
Beban basis data (beban DB) - Kategorisasi anomali sebagai masalah beban basis data. Metrik yang sesuai dalam Performance Insights adalah.
DBLoadMetrik ini juga dipublikasikan ke Amazon CloudWatch. -
db.r5.4xlarge - Kelas instance DB. Jumlah vCPUs, yaitu 16 dalam contoh ini, sesuai dengan garis putus-putus dalam grafik Average active session (AAS).
-
24 (lonjakan 6x) - Beban DB, diukur dalam sesi aktif rata-rata (AAS) selama interval waktu yang dilaporkan dalam wawasan. Jadi, pada waktu tertentu selama periode anomali, rata-rata 24 sesi aktif di database. Beban DB adalah 6 kali beban DB normal untuk contoh ini.
-
Biasanya: DB memuat hingga 4 - Dasar beban DB, diukur dalam AAS, selama beban kerja yang khas. Nilai 4 berarti bahwa, selama operasi normal, rata-rata 4 atau lebih sedikit sesi aktif pada database pada waktu tertentu.
Secara default, bagan beban diiris oleh peristiwa tunggu. Ini berarti bahwa untuk setiap batang dalam bagan, area berwarna terbesar mewakili peristiwa tunggu yang berkontribusi paling besar terhadap total beban DB. Bagan menunjukkan waktu (berwarna merah) saat masalah dimulai. Fokuskan perhatian Anda pada acara tunggu yang paling banyak memakan ruang di bilah:
-
CPU -
IO:wait/io/sql/table/handler
Peristiwa tunggu sebelumnya muncul lebih dari biasanya untuk database Aurora MySQL ini. Untuk mempelajari cara menyetel kinerja menggunakan peristiwa tunggu di Amazon Aurora, lihat Menyetel dengan peristiwa tunggu untuk Aurora MySQL dan Menyetel dengan peristiwa tunggu untuk Aurora PostgreSQL di Panduan Pengguna Amazon Aurora. Untuk mempelajari cara menyetel kinerja menggunakan peristiwa tunggu di RDS untuk PostgreSQL, lihat Menyetel dengan peristiwa tunggu untuk RDS untuk PostgreSQL di Panduan Pengguna Amazon RDS.
Metrik terkait
Bagian metrik Terkait mencantumkan anomali kontekstual, yang merupakan temuan spesifik dalam anomali kausal. Temuan ini memberikan informasi tambahan tentang masalah kinerja.
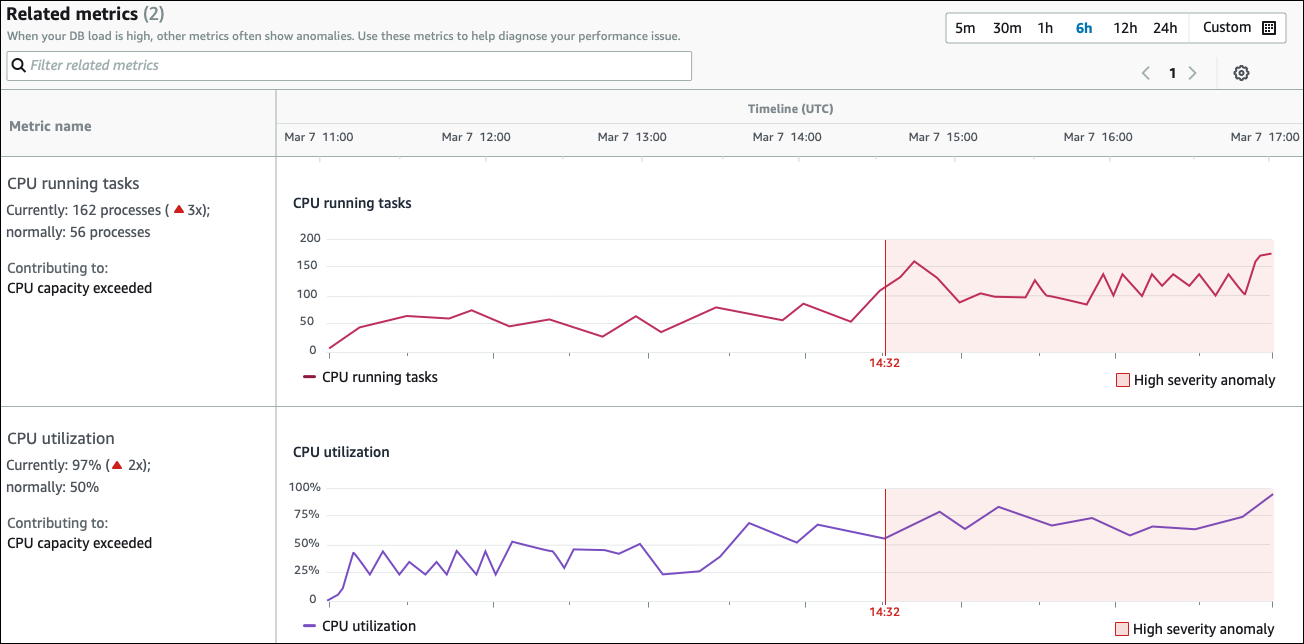
Tabel metrik Terkait memiliki dua kolom: Nama metrik dan Garis Waktu (UTC). Setiap baris dalam tabel sesuai dengan metrik tertentu.
Kolom pertama dari setiap baris memiliki informasi berikut:
-
Name— Nama metrik. Baris pertama mengidentifikasi metrik sebagai tugas yang menjalankan CPU. -
Saat ini — Nilai metrik saat ini. Di baris pertama, nilai saat ini adalah 162 proses (3x).
-
Biasanya — Dasar metrik ini untuk database ini ketika berfungsi normal. DevOpsGuru untuk RDS menghitung baseline sebagai nilai persentil ke-95 selama 1 minggu sejarah. Baris pertama menunjukkan bahwa 56 proses biasanya berjalan pada CPU.
-
Berkontribusi pada — Temuan yang terkait dengan metrik ini. Pada baris pertama, CPU menjalankan tugas metrik dikaitkan dengan kapasitas CPU melebihi anomali.
Kolom Timeline menunjukkan grafik garis untuk metrik. Area yang diarsir menunjukkan interval waktu ketika DevOps Guru untuk RDS menetapkan temuan tersebut sebagai tingkat keparahan yang tinggi.
Analisis dan rekomendasi
Sedangkan anomali kausal menggambarkan masalah keseluruhan, anomali kontekstual menggambarkan temuan spesifik yang memerlukan penyelidikan. Setiap temuan sesuai dengan satu set metrik terkait.
Dalam contoh berikut dari bagian Analisis dan rekomendasi, anomali beban DB tinggi memiliki dua temuan.
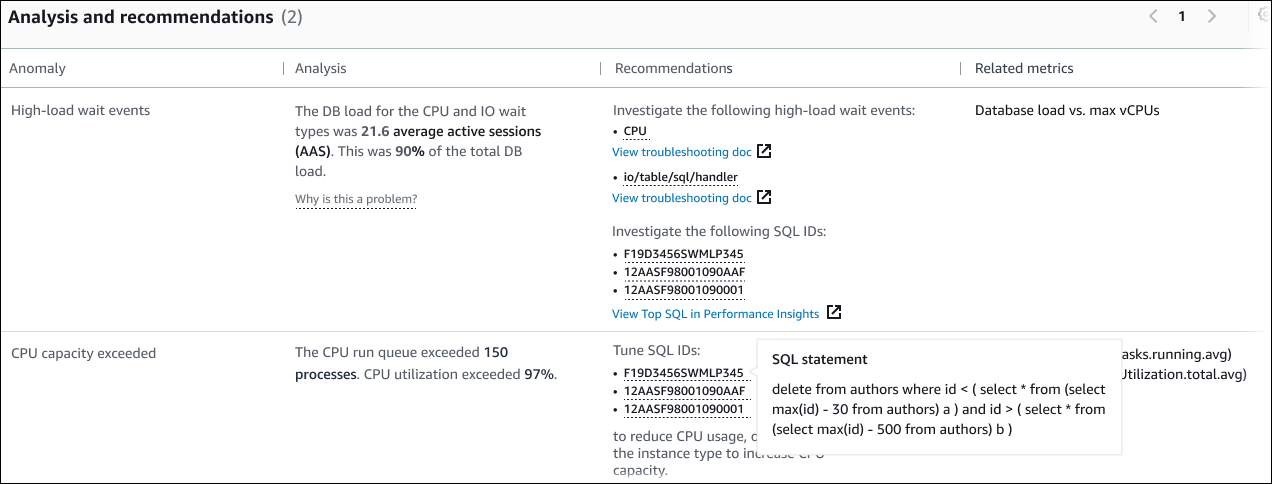
Tabel memiliki kolom berikut:
-
Anomali — Gambaran umum tentang anomali kontekstual ini. Dalam contoh ini, anomali pertama adalah peristiwa tunggu beban tinggi, dan yang kedua adalah kapasitas CPU terlampaui.
-
Analisis — Penjelasan rinci tentang anomali.
Pada anomali pertama, tiga jenis tunggu berkontribusi pada 90% beban DB. Dalam anomali kedua, antrian CPU run melebihi 150, yang berarti bahwa pada waktu tertentu, lebih dari 150 sesi menunggu waktu CPU. Pemanfaatan CPU lebih dari 97%, yang berarti bahwa selama masalah, CPU sibuk 97% dari waktu. Dengan demikian, CPU hampir terus ditempati sementara rata-rata 150 sesi menunggu untuk berjalan pada CPU.
-
Rekomendasi — Respons pengguna yang disarankan terhadap anomali.
Dalam anomali pertama, DevOps Guru untuk RDS merekomendasikan agar Anda menyelidiki peristiwa menunggu dan.
cpuio/table/sql/handlerUntuk mempelajari cara menyetel kinerja database berdasarkan peristiwa ini, lihat cpu dan io/table/sql/handlerdi Panduan Pengguna Amazon Aurora.Dalam anomali kedua, DevOps Guru untuk RDS merekomendasikan agar Anda mengurangi konsumsi CPU dengan menyetel tiga pernyataan SQL. Anda dapat mengarahkan kursor ke tautan untuk melihat teks SQL.
-
Metrik terkait — Metrik yang memberi Anda pengukuran spesifik untuk anomali. Untuk informasi selengkapnya tentang metrik ini, lihat Referensi metrik untuk Amazon Aurora di Panduan Pengguna Amazon Aurora atau referensi Metrik untuk Amazon RDS di Panduan Pengguna Amazon RDS.
Pada anomali pertama, DevOps Guru for RDS merekomendasikan agar membandingkan beban DB dengan CPU maksimum untuk instans Anda. Pada anomali kedua, rekomendasinya adalah melihat antrian run CPU, pemanfaatan CPU, dan tingkat eksekusi SQL.
